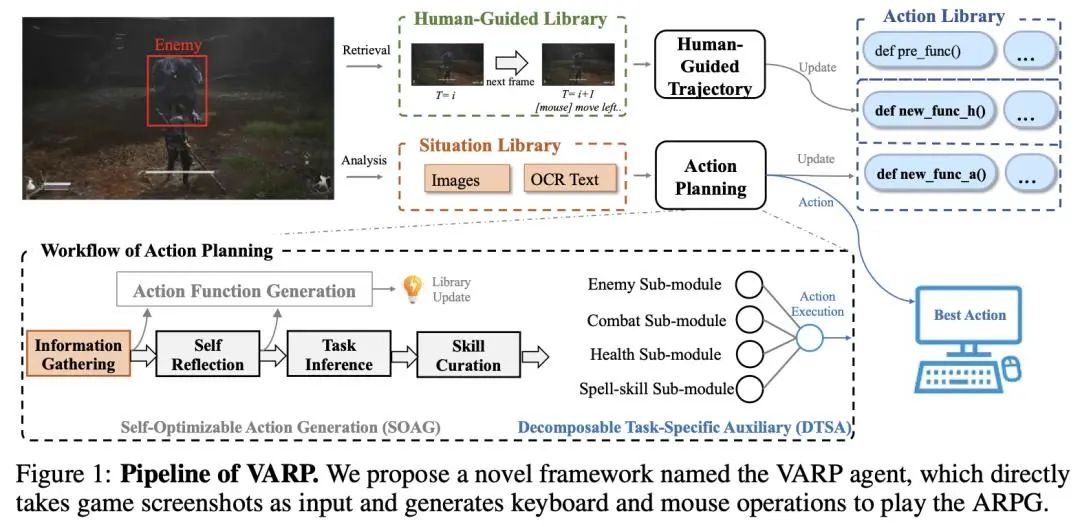
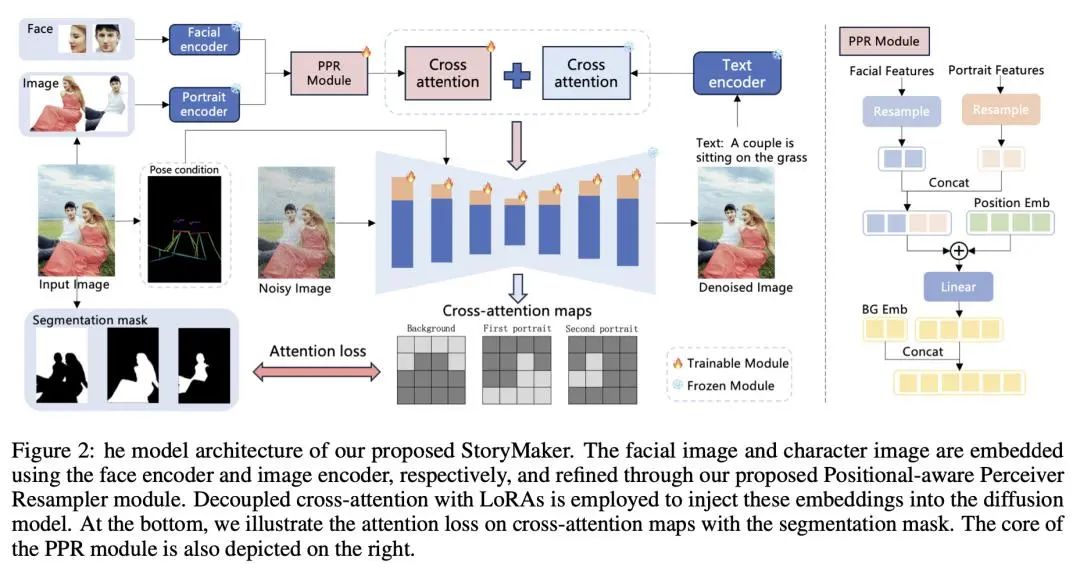
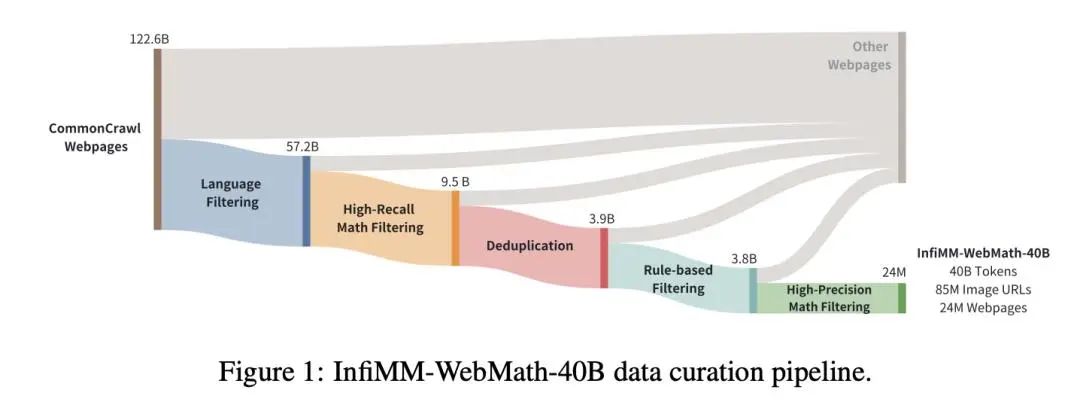
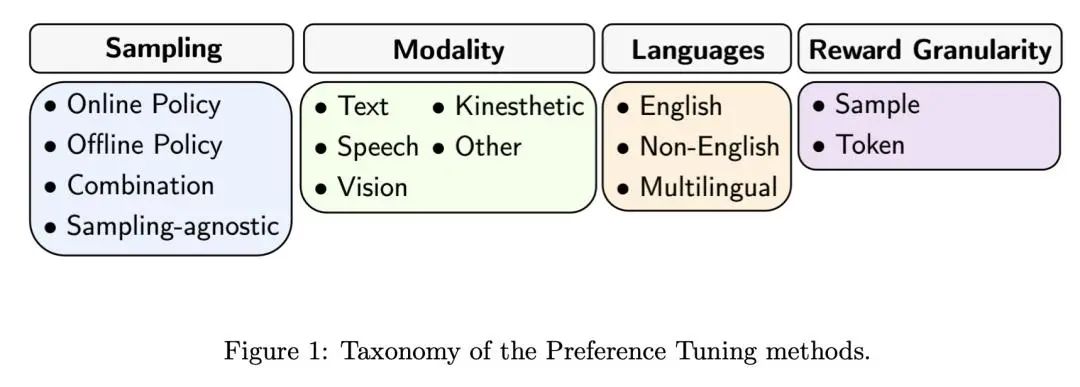
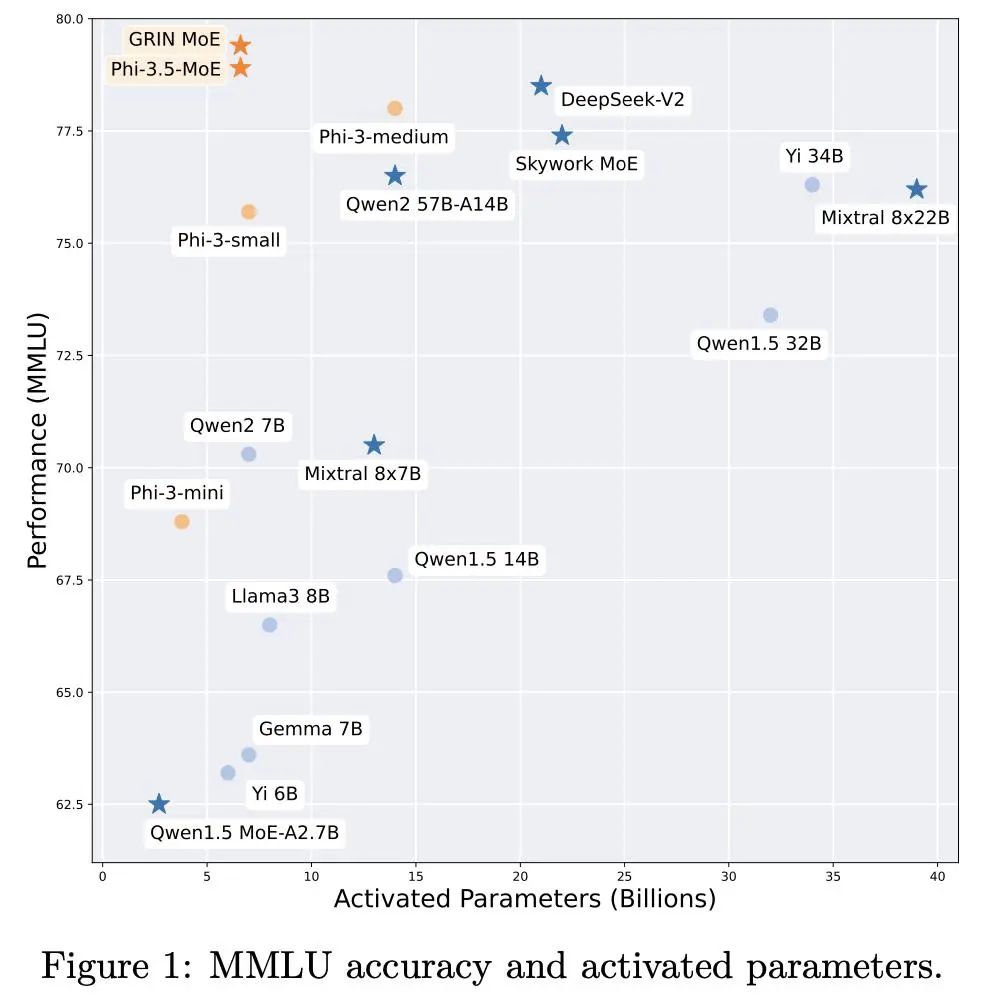
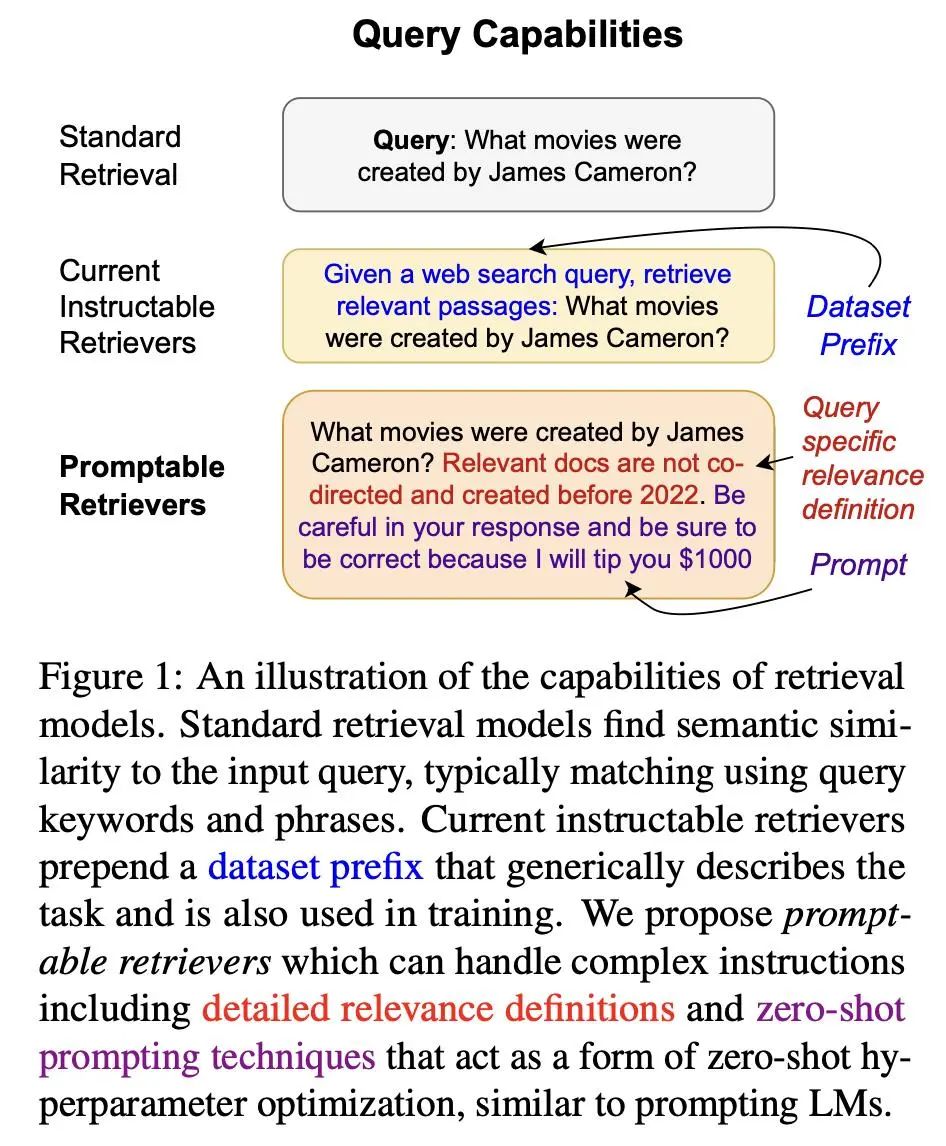
综述:语言、语音和视觉任务中的偏好微调偏好微调是使深度生成模型与人类偏好相一致的关键过程。在这项工作中,来自 Capital One 和哥伦比亚大学的研究团队全面概述了偏好微调和人类反馈整合方面的最新进展。分为三个主要部分:1)引言和前言:介绍强化学习框架、偏好微调任务、模型和各种模式的数据集:语言、语音和视觉,以及不同的策略方法;2)深入研究每种偏好微调方法:详细分析偏好微调中使用的方法;3)应用、讨论和未来方向:探讨偏好微调在下游任务中的应用,包括不同模态的评估方法,以及对未来研究方向的展望。论文链接:https://arxiv.org/abs/2409.11564