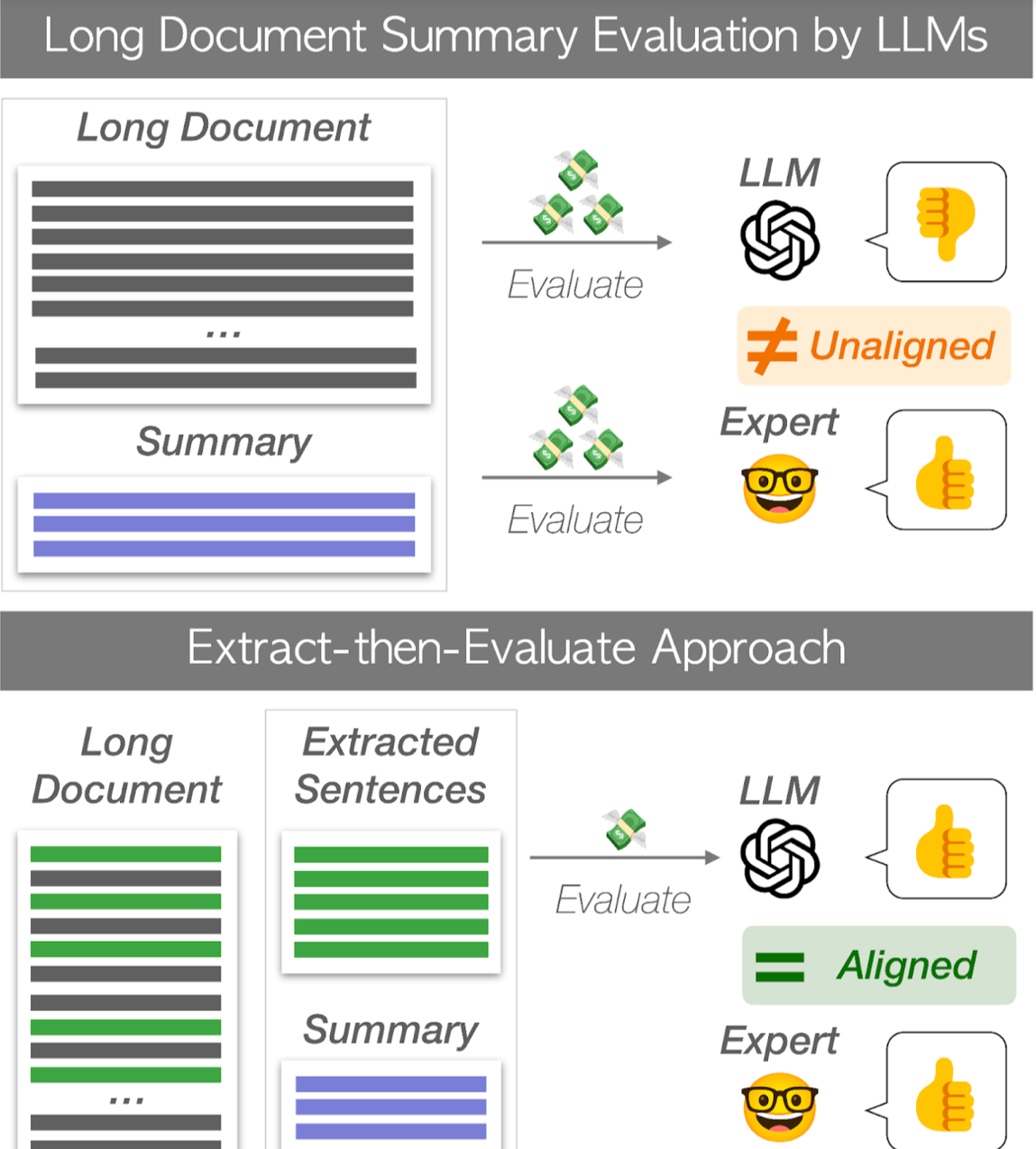
在文本生成和摘要领域,评估生成摘要的质量,尤其是对于长文档,一直是一个具有挑战性的任务。传统方法往往面临着高计算成本和“中间遗失”问题,即模型经常忽视长文档中关键信息的情况。为了解决这些挑战,我们进行了一项研究,使用一种创新方法来评估长模型,这种方法不仅可以显著降低评估成本,还能更接近人类评估。
抽取-然后评估方法
我们方法的核心,称为“先抽取后评估”,在于其简单性和有效性。与其评估整个长文档不同,该方法专注于从源文档中提取关键句子,然后根据这些提取的句子来评估摘要。通过这样做,它有效地解决了“中间遗失”问题,并显著降低了评估所需的计算资源。
主要贡献
- 成本效益的评估:通过专注于关键句子,该方法大大降低了评估长文档所需的计算成本。
- 与人类评估的更高相关性:这种方法与人类评估的相关性更高,使其成为摘要评估的更可靠方法。
实验和结果
我们在各种数据集上进行了广泛的实验,包括arXiv、GovReport、PubMed和SQuALITY。实验探索了不同的句子抽取方法,如LEAD、ROUGE、BERTScore和NLI,以确定“先抽取后评估”方法的最有效方法。结果是令人鼓舞的,表明所提出的方法相比现有的自动度量标准,降低了评估成本并提高了与人类评估的一致性。
意义和未来方向
我们的研究代表了文本生成评估的一个显着进步。它的影响不仅限于学术界,还为需要总结长文档的行业提供了实用的解决方案,包括法律文件分析、医疗报告摘要和新闻聚合等领域。
展望未来,这项研究为进一步研究开辟了新的途径,特别是在探索更复杂的句子抽取方法和将该方法扩展到其他形式的文本生成任务方面。此外,该研究突显了利用大型语言模型(LLMs)以更具成本效益和准确性的方式的潜力,为未来人工智能和自然语言处理技术的发展提供了一个有前途的方向。
结论
总之,“先抽取后评估”方法是在评估长文档摘要方面的重大进步。通过解决高计算成本和“中间遗失”等关键挑战,该方法不仅提高了摘要评估的效率和准确性,而且与人类判断紧密相符。随着我们的前进,看到这种方法如何进一步完善并应用于各个领域将是令人兴奋的。
对于那些对深入了解这种创新方法感兴趣的人,我们已经在GitHub上提供了代码,并邀请社区参与我们的研究工作,共同开发更有效的文本生成评估方法。
(机器翻译,轻度译后编辑,仅供参考)
编辑:胡跃
