
![]()
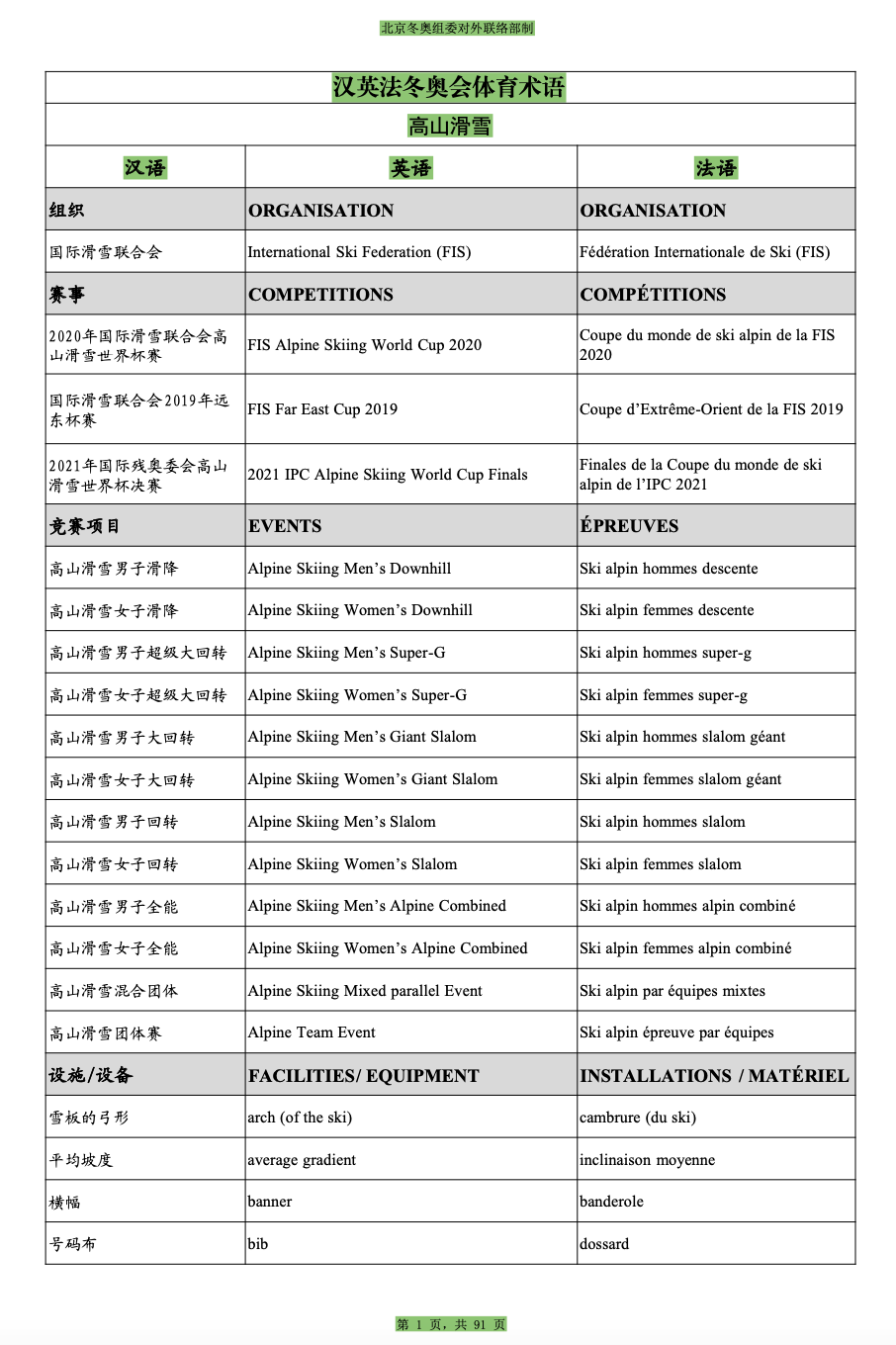
图1-1 PDF术语表(案例)

打开软件,在首页上传文档中的文档语言,避免出现乱码等情况
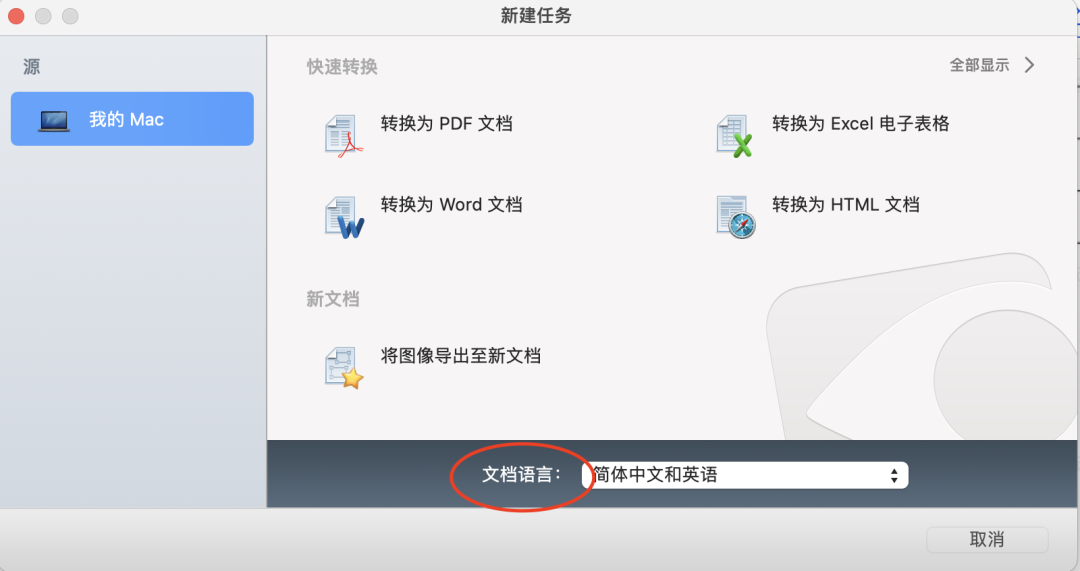
图1-2 ABBYY FineReader PDF for Mac 新建任务页面
点击文档语言菜单栏,可以直接输入要选择的语言,不用下滑找选项浪费时间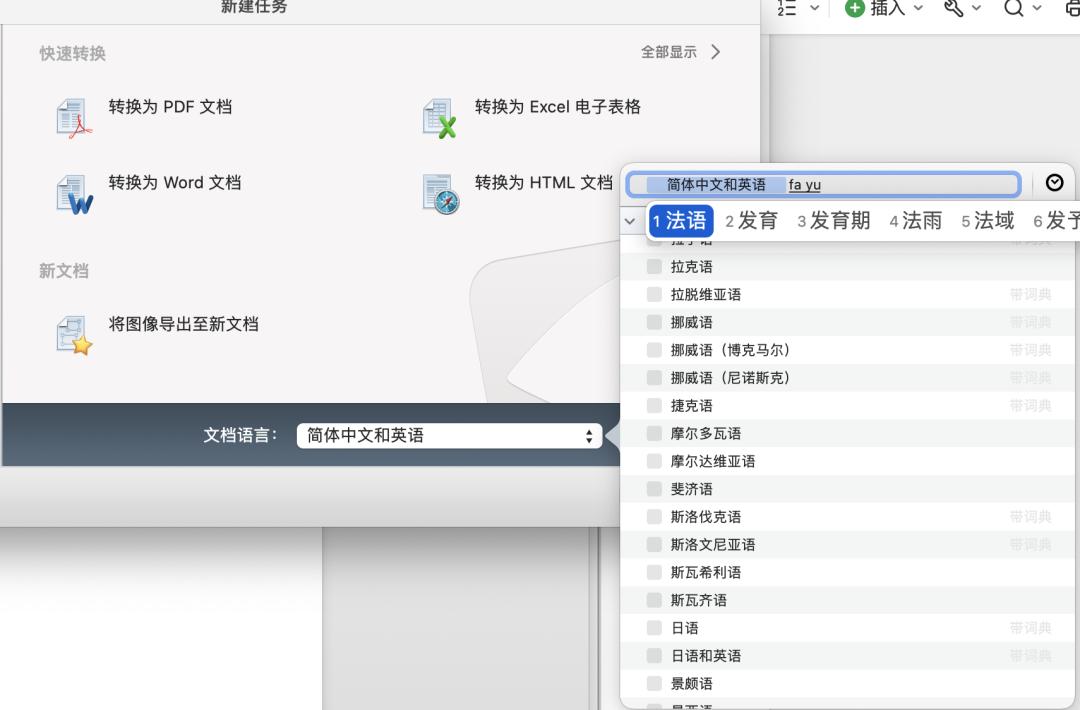
图1-3 选择目标识别语言
选择转化为 EXCEL 电子表格
图1-4 选择转化格式
选择需要打开的文件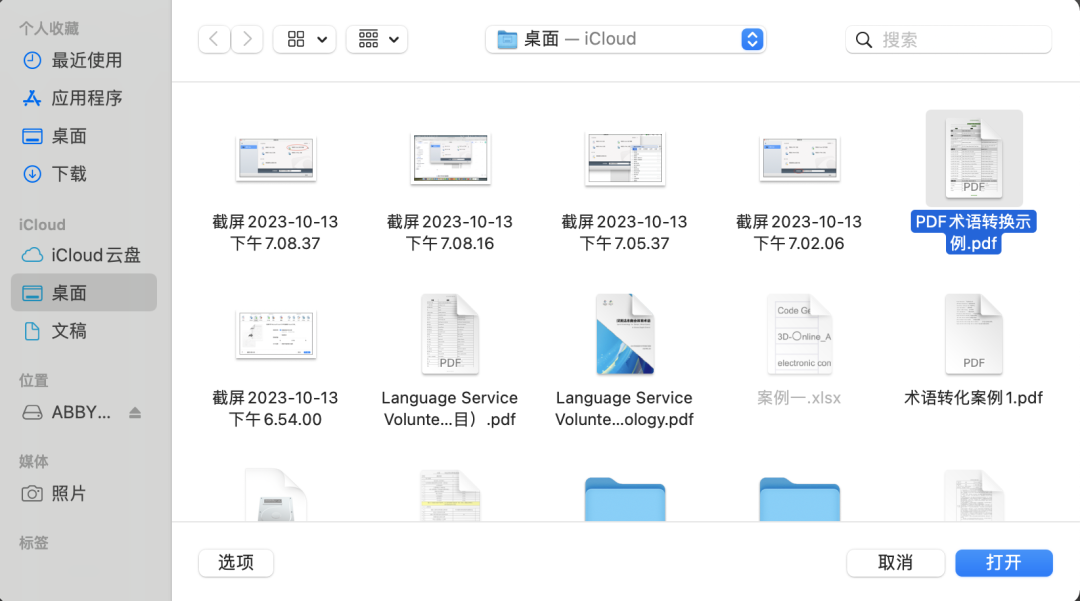
图1-5 选择目标文件
图1-6 添加页面
识别文档
图1-7 识别文档
管理文档页面
图1-8 管理文档
图1-9
-
文本(以绿色突出显示)
此区域的内容将识别为文本。 -
图片(以红色突出显示)
不会识别此区域的内容,而是在结果文档中按它们的原始状态重新创建。 -
表格(以蓝色突出显示)
在识别此区域的内容时会考虑到表格的结构。 -
背景图片(以棕色突出显示)
不会识别此区域的内容,而是在结果文档中将它们重新创建为背景。

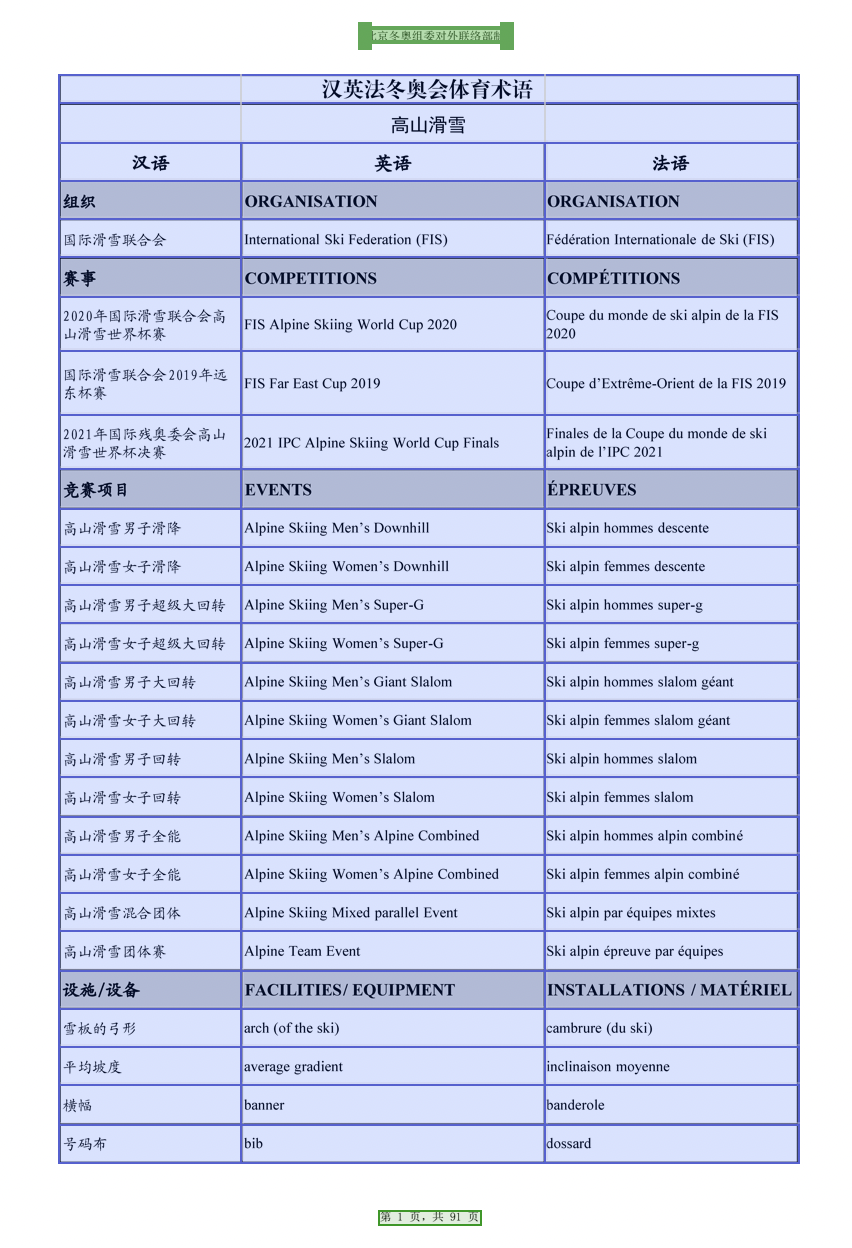
图1-10 案例中的区域识别结果
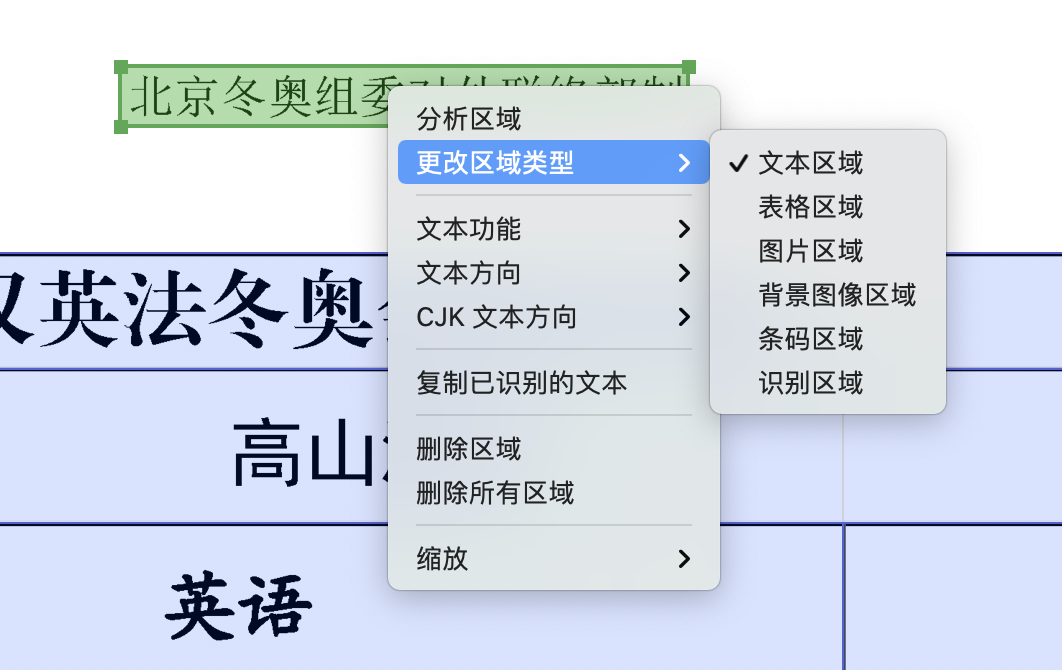
图1-11
编辑筛选需要导出为 Excel 表格的内容,删除不需要的内容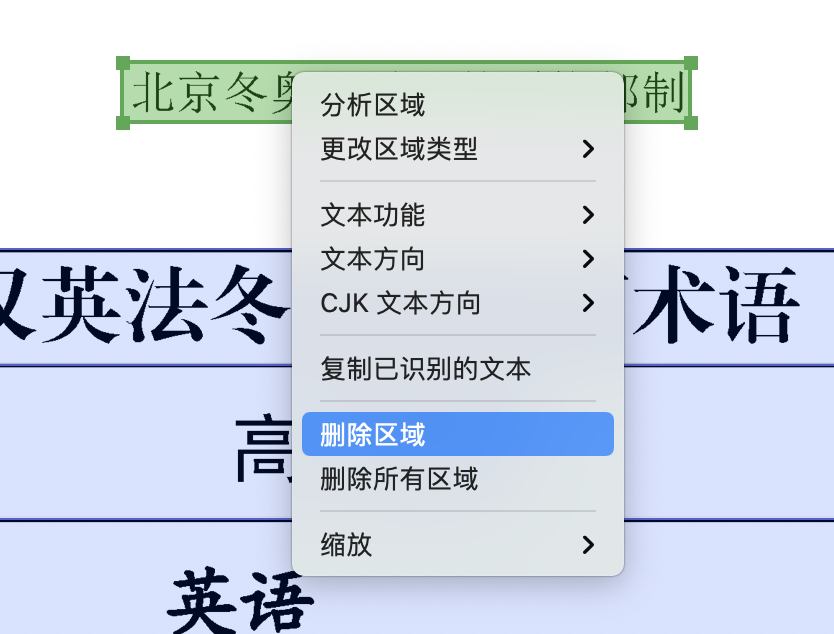
图1-12 如何删除区域

图1-13 删除后页面
下面来去除图 1-14 红圈内不需要的内容,在左侧工具栏选择绘制识别区域(见图 1-15)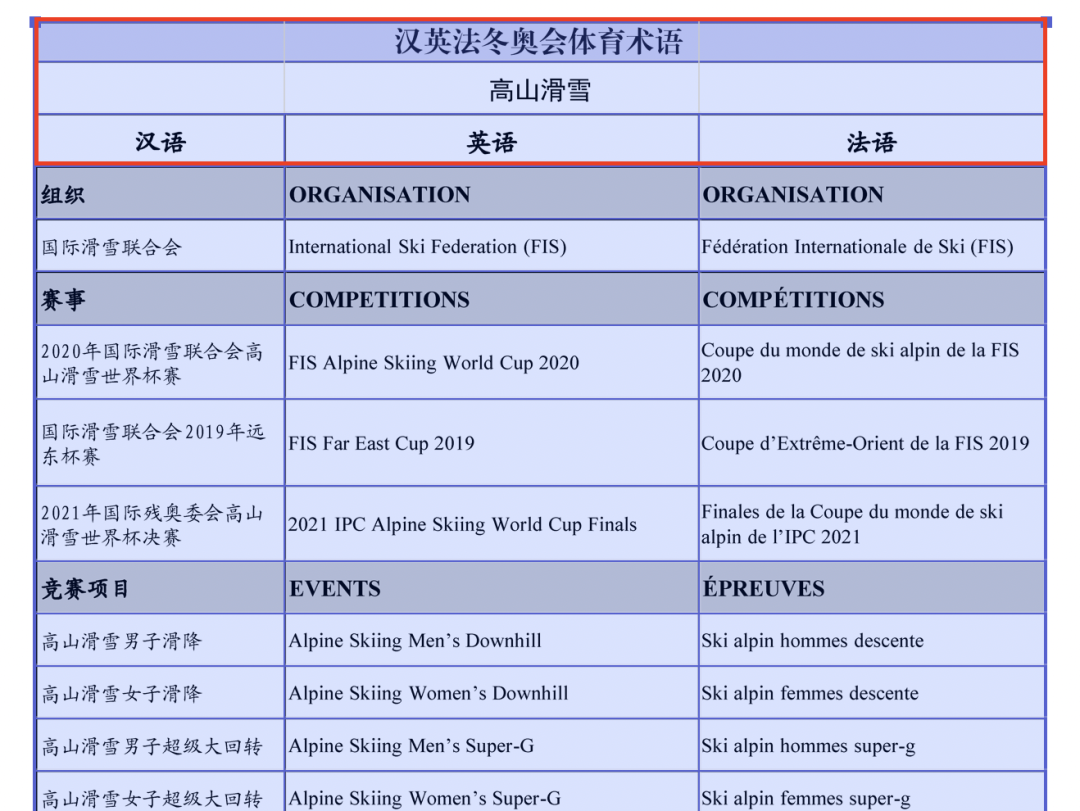
图1-14 如何去除红圈内不需要的内容
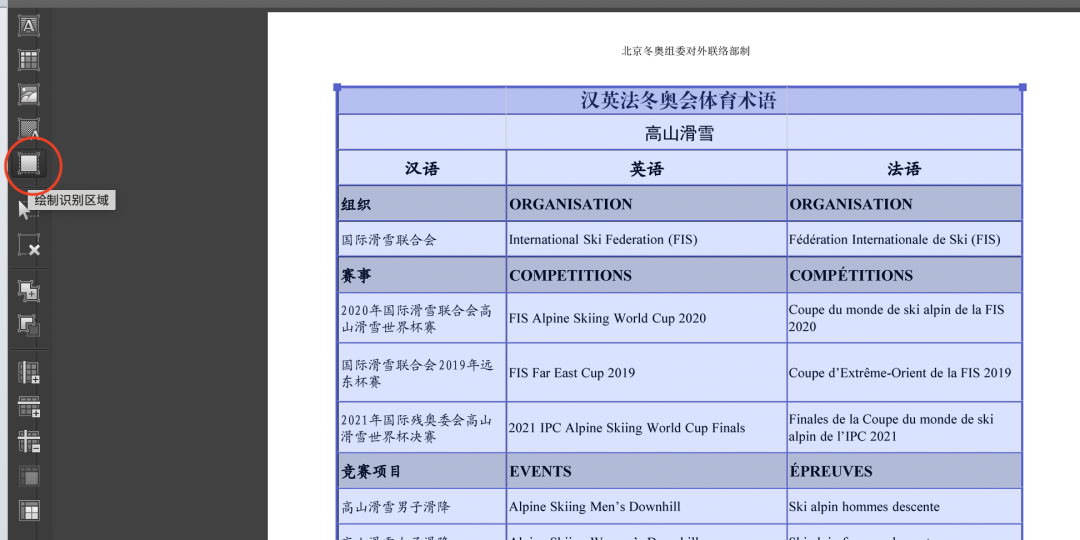
图1-15 点击绘制识别区域
拖动上边界至想要保留的部分(见图 1-16)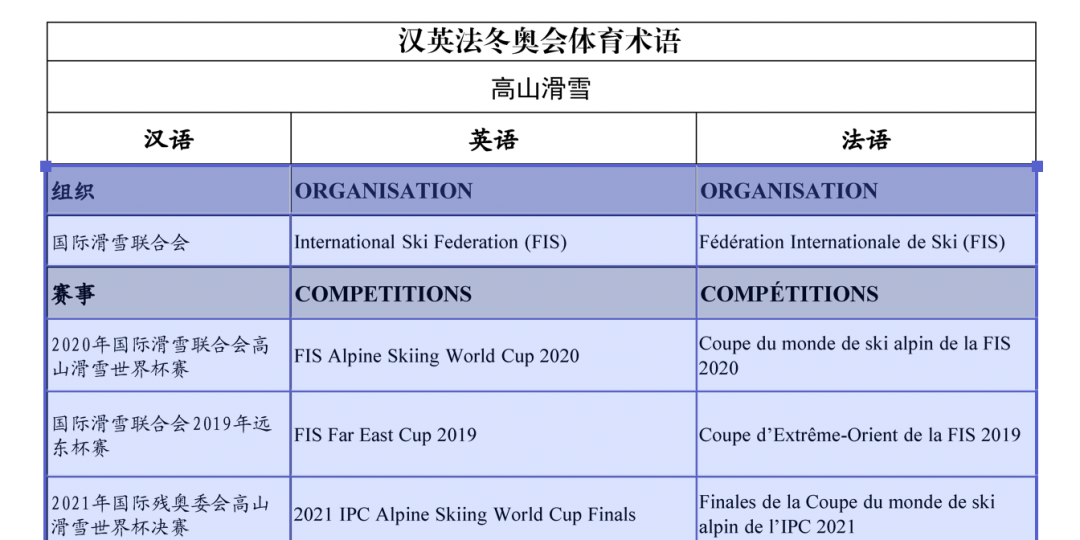
图1-16 拖动上边界
编辑后页面如图 1-17,图 1-18 所示,只保留了三语术语对照部分

图1-17 编辑后页面(1)
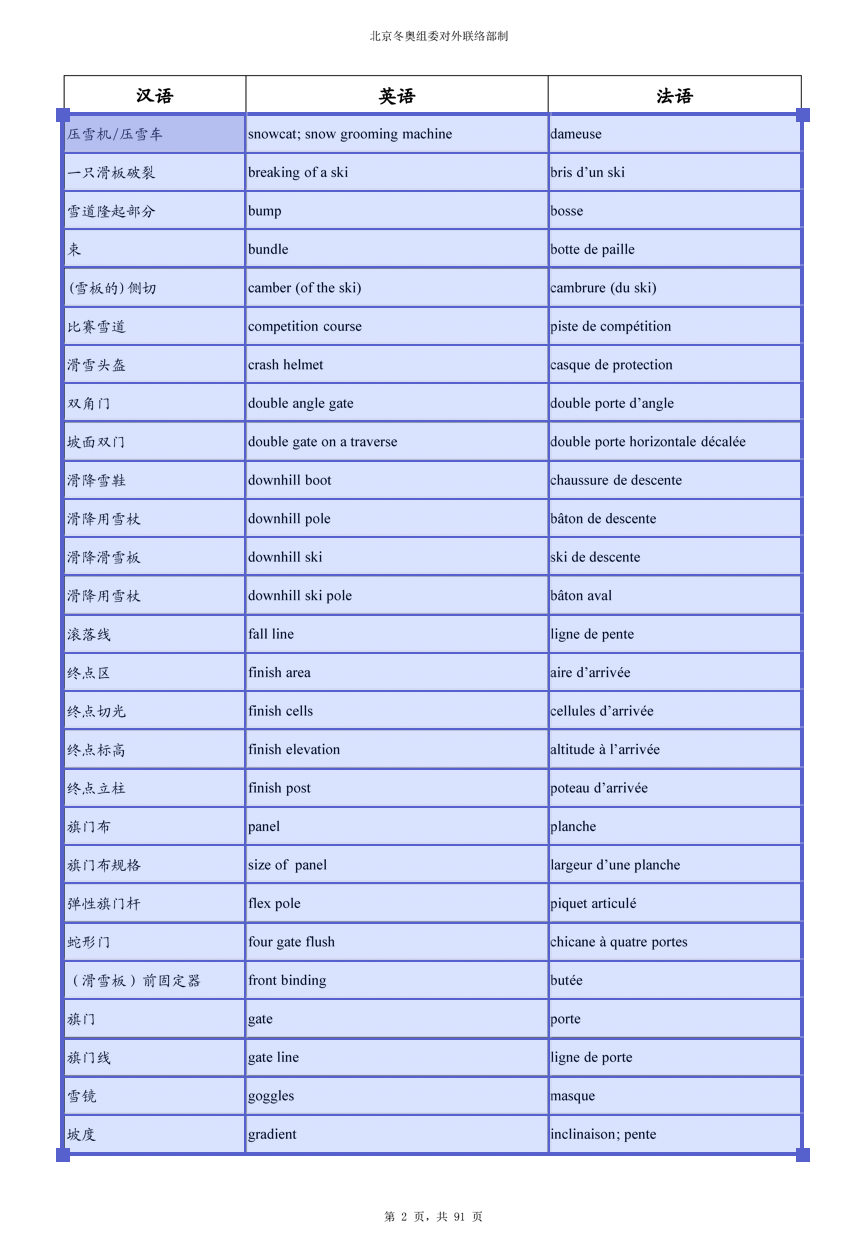
图1-18 编辑后页面(2)
点击主页面上方导出
图1-19 导出
选择需要转化为的格式及其他所需选项,点击下一步
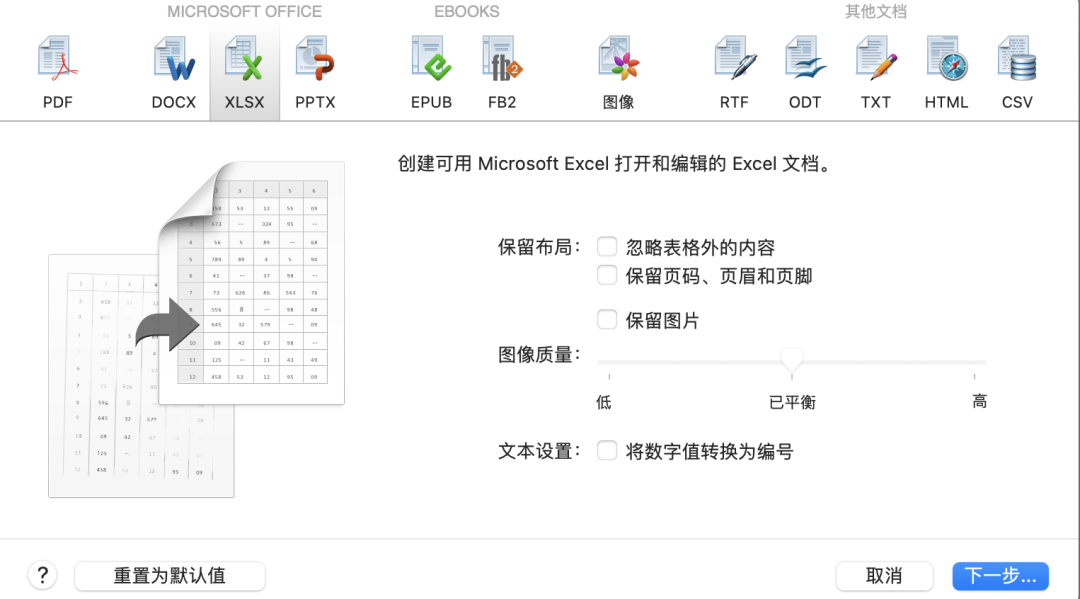
图1-20 转化格式选项页
保存设置选择为所有页面创建一个文档
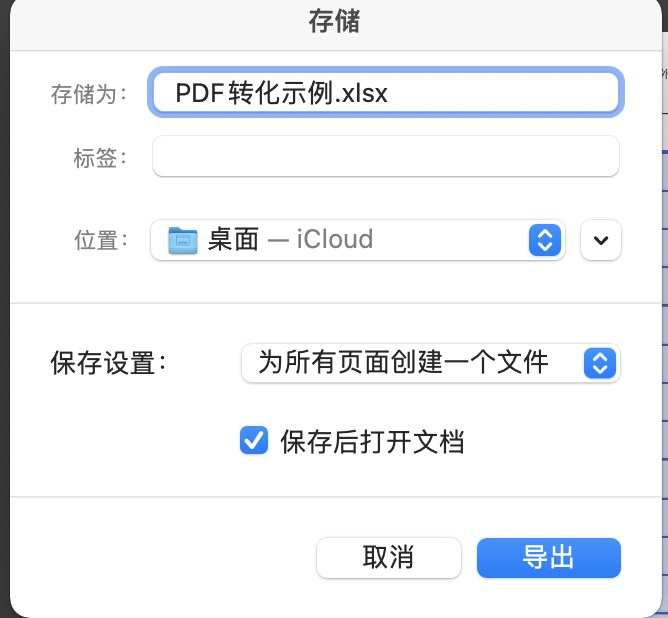
图1-21
导出结果如图 1-22
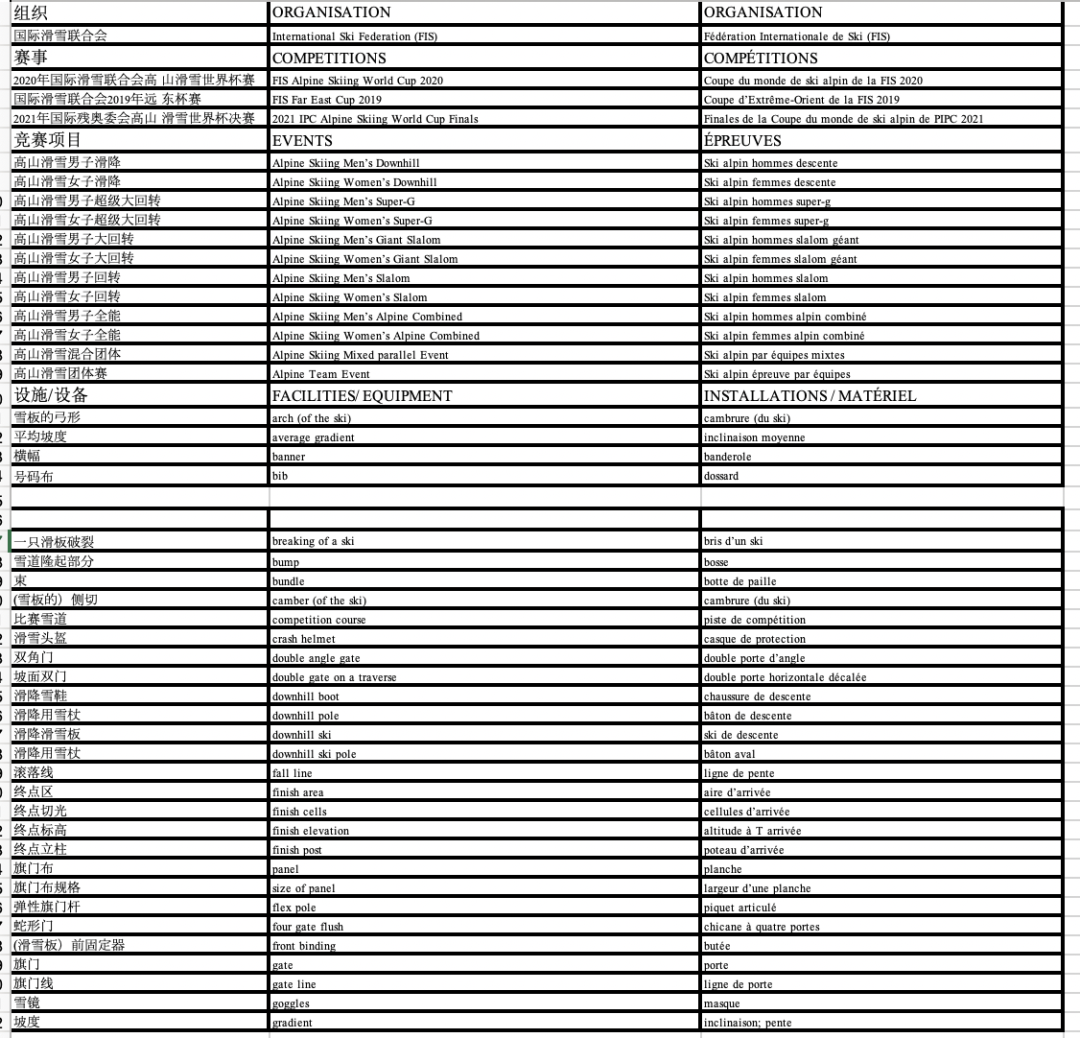
图1-22 excel中导出结果
此时发现图 1-22 的表格中存在空白行,可以使用 Excel 批量去除空白行。F5 键打开定位窗口,选择定位条件
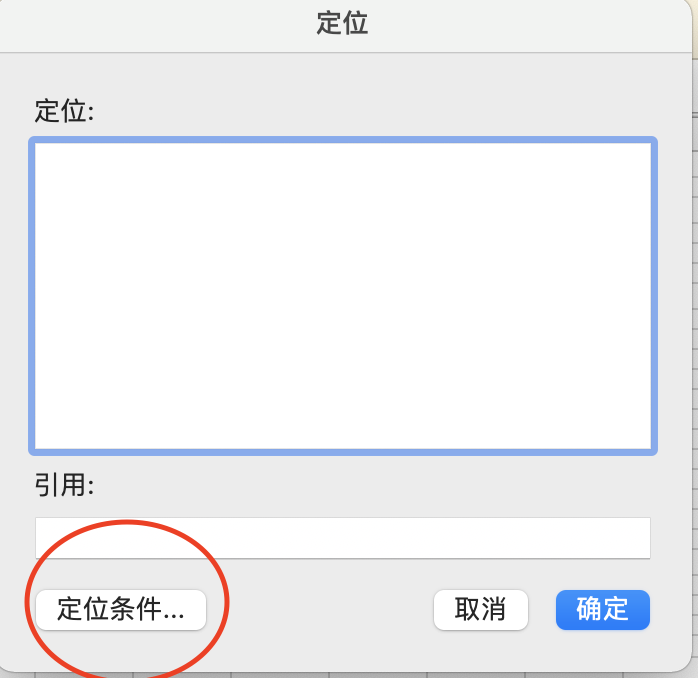
图1-23 定位条件页
点击空值,确定
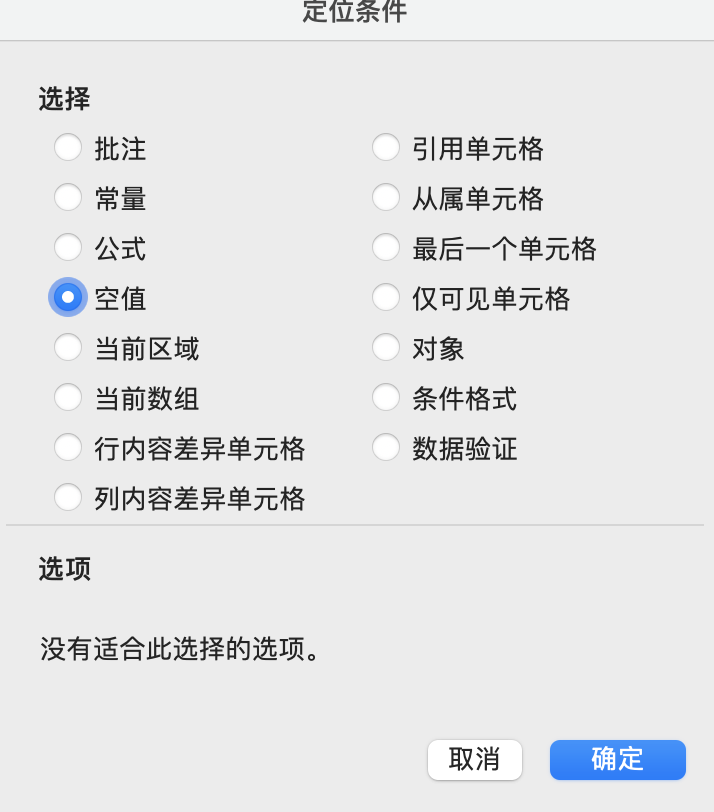
图1-24 定位条件选项
Excel 会将空白部分自动标灰并选中
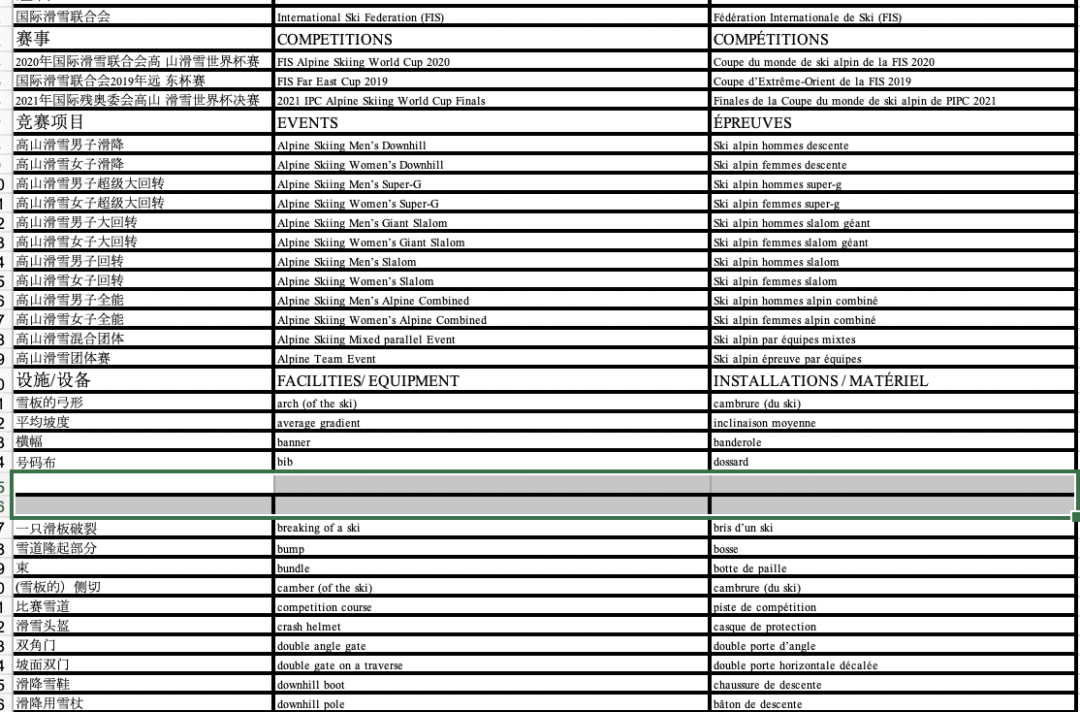
图1-25 选择定位后Excel表格自动标灰
鼠标右键选择删除整行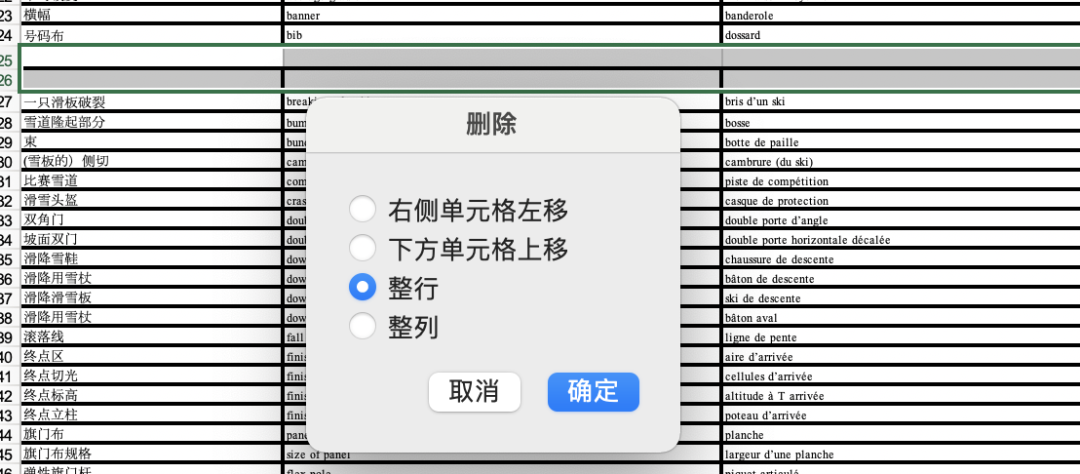
图1-26 删除空行
最终成果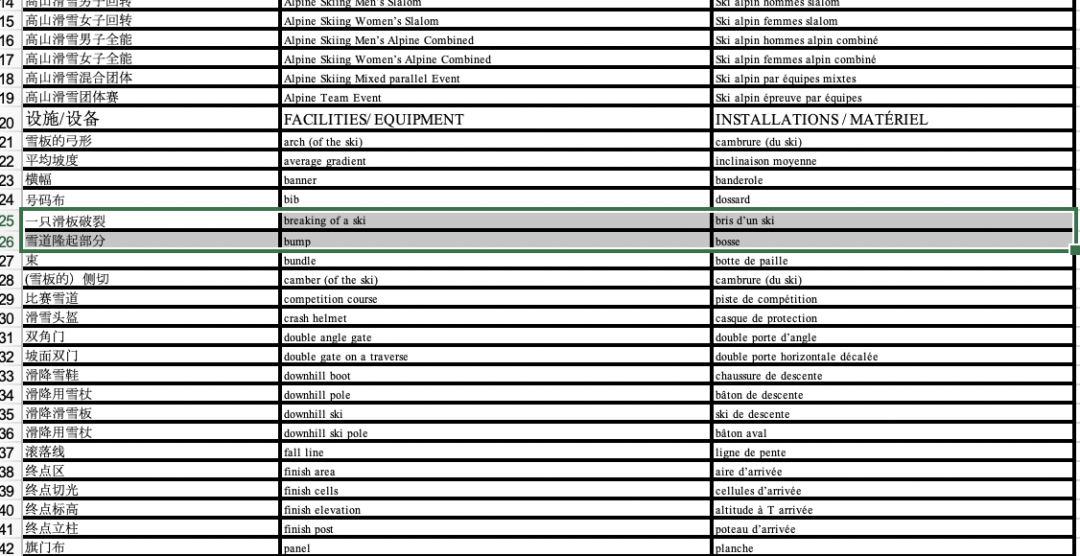
图1-27 Excel中的最终成果
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
原创来源:北外CAT课程展示-章瑶
推文编辑:李丹
