
ChatGPT与语料数据处理工作坊圆满结束!课程中,袁煜老师介绍了语言模型的发展历程,通过Python实操演练,带大家夯实了语料数据处理的基础。王均松老师则通过讲解丰富的翻译案例,深入浅出地讲解了三种ChatGPT优化译前编辑的方法。郭镇博士则为大家揭示了技术前沿操作,将ChatGPT与Python和R语言无缝联动,使得即使编程基础有限,也能实现语料库建设。李梦飞则展示了如何在语料检索与数据分析中充分发挥大语言模型的力量。
现在,就跟随小编一起回顾本期工作坊的精彩亮点吧~
ChatGPT在翻译数据挖掘中的实践应用——袁煜
首先,袁老师为大家科普了语言模型的发展历程和工作原理:第一代Ngram语言模型、第二代神经网络语言模型(包括word2vec和transformers预训练语言模型)、第三代大语言模型(以ChatGPT为代表),并对前两代的不足之处和大语言模型的先进之处进行了对比分析。课程后半部分,袁老师带领大家亲自动手,使用Python进行口译质量评估实操。他逐一解释了每块代码的含义,确保大家能够理解并掌握这些关键概念。

(科普ChatGPT模型的背后原理)
ChatGPT在机器翻译译前编辑中的应用探索——王均松
首先,王老师介绍了机器翻译译前编辑的研究背景。接着,王老师深入阐述了译前编辑原理,从词汇、句子、语篇三个层面进行说明,并以中英对照的论文摘要中的翻译问题为例,展示了非常实用的人工译前编辑策略,包括删除词汇、切分句子、调整语序等关键技巧。在梳理了译前编辑常用技巧与经典案例后,王老师提出了三种利用ChatGPT辅助译前编辑的方法:基于提示/指令、基于样例学习、指令+学习。王老师通过大量的案例测试,为大家呈现了如何善用大语言模型的强大力量,来优化原文,解决翻译中难题,最终提升机器翻译质量。

(基于样例学习的译前编辑方法介绍)
ChatGPT赋能单语与平行语料库建设与实操——郭镇
首先,郭镇博士简要概述了翻译语料选择与元信息标注,为大家初步普及了基本概念。随后,郭博士分享了anaconda的安装、操作视频。接下来,他演示了ChatGPT辅助语料批量处理,分享了一些prompt,展示了如何实现ChatGPT与Python的联动,如何使用ChatGPT辅助代码编写,报错返回ChatGPT修改方法。课程后半部分,郭博士使用anaconda带领大家实操文本清洗、对齐语料、词性标注等,以建设中英双语对齐的语料库。最后,郭博士介绍了ChatGPT辅助语料数据图形化,如何编写R语言实现语料数据图形化。他强调了在没有十分强大编程基础的情况下,也可以运用ChatGPT辅助大家进行语料库建设。

(ChatGPT+Python可执行操作)
大语言模型(LLM)在语料标注与数据分析中的实践与应用——李梦飞
课程开篇,李老师先科普了大语言模型原理,评估了主流大语言模型在语言研究中的应用,举例了复旦大学LLMEVAL-2中文大语言模型评测、CLiB中文大模型能力评测榜单,设计多维立体prompt测试集,通过量化打分对各种大语言模型进行比较。接着,李老师讲了大语言模型在语料检索与分析中的应用,如何利用ChatGPT从标注到检索和提取一站式完成,辅助语言数据统计分析。
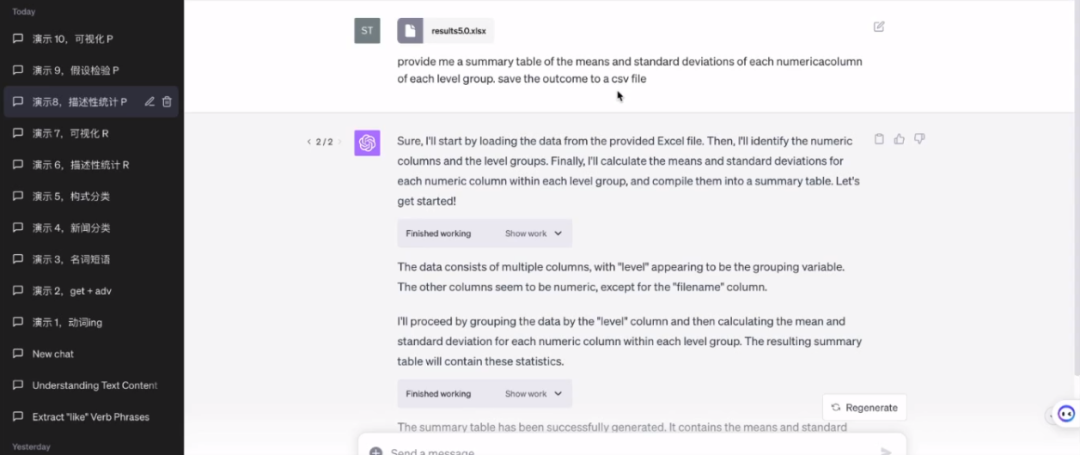
(ChatGPT辅助描述性统计)
师生互动
课程内容之外,群内也有老师进行了细致答疑

(anaconda安装指导)
(助教答疑)
感谢各位师友的认真学习~
期待未来更多深入地交流~
欲知课程更多内容,点击下方课程传送门~

