译学文献 | 冯志伟:大语言模型时代的术语翻译
2024年10月04日 00:00
以下文章来源于中国科技术语 ,作者冯志伟

GPT系列产品的出现
2018年,OpenAI公司开发了“基于转换器的生成式预训练模型”,其英文术语是Generative Pre-trained Transformer,简称GPT-1。GPT-1的推出揭开了大语言模型(Large Language Model,LLM)研制的序幕。
GPT-1利用转换器模型(Transformer)的编码器(encoder)和解码器(decoder),从语言大数据中获取了丰富的词汇、语法和语义知识,在语言生成任务上达到了较高水平。
GPT-1使用Transformer进行训练,在训练过程中,使用海量的自然语言文本数据来学习单词的嵌入表示(word embedding expression)以及上下文之间的关系(context relation),形成知识表示(knowledge representation)。一旦训练完成,知识表示就被编码在神经网络的参数中,利用这些参数可以生成回答。当用户提出问题时,神经网络就根据已经学习到的知识,把答案反馈给用户。
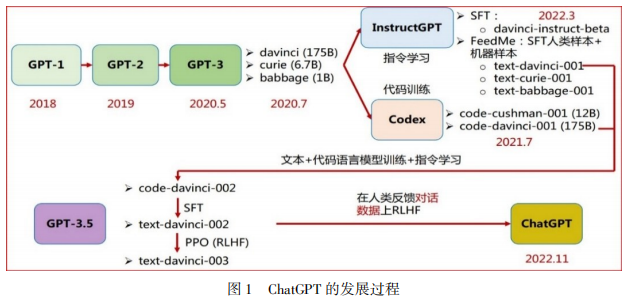
OpenAI公司分别于2018、2019年开发出了GPT-1和GPT-2,于2020年5月开发出了GPT-3,2020年7月研制了GPT-3中的davinci, curie, babbage三个模型,2022年3月研制了InstructGPT,进行文本和代码的语言模型训练,研制出GPT-3.5(如下图1所示)后接着进行有监督微调(Supervised Fine Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),之后于2022年11月推出ChatGPT。
ChatGPT的推出引起了史无前例的轰动。成千上万的用户从不同角度对它进行了应用体验。ChatGPT在2022年11月30日推出仅5天时,注册用户就超过百万;推出两个月的时候,月活跃用户超过1亿。短视频社交媒体平台TikTok月活跃用户超过1亿用了9个月时间,推特(Twitter)月活跃用户超过1亿用了90个月时间,ChatGPT打破了历史记录,遥遥领先,引起了全球网民的广泛关注,在大语言模型时代掀起了一场波澜壮阔、史无前例的海啸[1]。
ChatGPT是一种对话场景优化语言模型(optimizing language models for dialogue)。ChatGPT比GPT-3更进一步,进化到具备执行自然语言指令的能力,用户不必给出示例,只要使用自然语言给出指令,ChatGPT就可以理解用户的意图。例如,用户只要直接用自然语言告诉ChatGPT把某个英语单词译成法语,ChatGPT就可以执行并给出翻译结果。ChatGPT可以根据上下文提示,自动理解并执行各类任务,不必更新模型的参数或架构。
ChatGPT利用Transformer模型,从语言大数据中获取丰富的语言知识,在语言生成任务上达到了相当高的水平,成为了大语言模型时代最重要的神经网络模型。
ChatGPT的训练语料高达100亿个句子,包含约5000亿个词元(token)。ChatGPT通过使用大量训练数据来模拟人的语言行为,生成人类可以理解的文本,并根据上下文语境提供恰当的回答,甚至还能做句法分析和语义分析,帮助用户调试计算机程序,写计算机程序代码,做数学题,而且能够通过人类反馈的信息,不断改善生成的功能,达到很强的自然语言生成能力。ChatGPT的训练参数越来越多,性能越来越好。
2023年3月17日, Open AI发布GPT-4。GPT-4 具有强大的识图能力,文字输入限制由3千词提升至 2.5 万词,回答问题的准确度显著提高,能够生成歌词、创意文本,改变文本的写作风格,甚至还具有自动翻译能力。2023年11月7日,OpenAI举行开发日(DevDay),宣布了GPT-4的一次大升级,推出了GPT-4 Turbo,引起了全世界的密切关注。
我们把这些不同阶段的GPT统称为GPTs系列。GPTs系列的成功具有划时代的里程碑意义,是大语言模型时代最伟大的成果之一,足以载入人工智能发展史册。我们已经进入了大语言模型时代(Era of Large Language Model)。
术语是人类的科技知识在自然语言中的结晶。在大语言模型的发展过程中,出现了大量表示新技术、新概念的术语。这些术语一般首先使用英语表达。中国人在使用这些术语的时候,有必要把这些新术语翻译成汉语,实现术语的民族化,以便广大中国用户使用。2017年以前,在深度学习和神经网络发展时期,不少英文术语即被翻译成了汉语(见表1)。这样的术语翻译,便于中国用户理解和使用,受到欢迎。

2017年6月,谷歌公司在其论文《注意力就是你们所需要的一切》(Attention Is All You Need)[2]中提出了一个完全基于注意力机制的预训练语言模型Transformer,该模型抛弃了在此之前的其他采用注意力机制的模型所保留的循环神经网络结构与卷积神经网络结构,核心部分完全使用注意力机制。Transformer是完全基于注意力机制的模型,在各项任务的完成和性能发挥方面表现优异,因此成为自然语言理解和机器翻译的重要基准模型。
由于大语言模型的研究和发展极快,大量新出现的术语来不及翻译成汉语,专业领域内部及专业人员之间,经常直接使用英语术语。Transformer这个新术语便是如此,到目前为止没有确定的广为认可的中文译词。Transformer一词具有多重含义:变压器、变形金刚、转换器等,但是人们觉得这些都不能表达Transformer在人工智能领域的确切含义,当下只好直接使用transformer这个英文术语[3]。
2019年,谷歌公司研制了Bidirectional Encoder Representations from Transformer,即“基于Transformer的双向编码器表示”,到目前为止也未有恰当的中文翻译,而是直接使用其英文缩写BERT。
与此同时,大语言模型领域还有若干新出现的产品及技术术语,都没有翻译为中文,业内普遍使用其英文原文(见表2)。就连最近公布的“汉语盘点2023”,直接把英文术语ChatGPT作为汉语热词公布,将其称为“国际词(如图2)。


以上情况说明,我们在提倡术语民族化的同时,术语的国际化也渐行其道,而且逐渐步入主流。
20世纪80年代,周有光先生在“文化传播和术语翻译”[4]一文中指出,在科学技术领域,可以直接使用外文术语而不翻译成汉语,实现术语的国际化。他似乎预见到了今天术语国际化的这种局面,指出:“在高层次的专家中,术语国际化不仅是可能的,而且是必要的。在一般科技工作者中间,术语民族化有容易学习的好处。” “中国如果明确地和认真地实行科技双语言政策,一方面可以保持术语民族化的传统,使大众科技工作者比较容易吸收科技知识,另一方面可以为术语国际化准备必要条件,使专业科技研究者迎头赶上迅猛发展的信息化时代。” 周有光先生的这些预见,今天正在一步一步地变成现实。在术语审定工作中,我们是不是有必要认真考虑周有光先生的这些预见呢?
大语言模型对术语学研究提出了严峻的挑战。计算机把文本中的语言符号转化为向量,读了亿万个“词元”(token),只要根据上下文对于下一个“词元”的预测来调整参数,就可以生成符合语法且逻辑通顺的文本。可见构成新文本的脉络就潜藏在大规模的文本数据之中,这样的脉络的实质是什么?怎样发现这种脉络?怎样使用这种脉络?其中包含着众多的术语学问题,应当引起我们的密切关注。
大语言模型为术语学发展提供了一个千载难逢的好机会,新时代的术语学研究应当面对这些问题,从而把术语学推进到一个崭新的阶段。


END
