
代码分享
# 导入必要的库
from nltk.corpus import PlaintextCorpusReader # 导入PlaintextCorpusReader 用于读取文本语料库
import nltk # 导入 Natural Language Toolkit(nltk)库,用于自然语言处理任务
# 指定语料库的根目录,即包含文本文件的文件夹路径
corpus_root = r"D:学习语料库中国政治文本语料库"
# 创建 PlaintextCorpusReader 对象,指定语料库的根目录和要读取的文件列表
corpora = PlaintextCorpusReader(corpus_root, ['jiang selected 1.txt'])
# 获取语料库中的文件标识符(文件名),这里只有一个文件 'jiang selected 1.txt'
corpora.fileids()
# 创建一个空列表 'pairs',用于存储条件-事件对
pairs = [(field, word)
for field in corpora.fileids() # 遍历语料库中的文件标识符
for word in [word.lower() for word in corpora.words(field)]] # 遍历文件中的每个单词,将单词转换为小写
# 使用 nltk 库中的 ConditionalFreqDist 创建条件频率分布对象 'cfd'
cfd = nltk.ConditionalFreqDist(pairs)
# 定义要分析的文本文件名
corpus_text = ['jiang selected 1.txt']
# 定义要统计的情态动词列表
count_word = ['can', 'could', 'may', 'might', 'must', 'will', 'shall', 'should']
# 使用 cfd.plot() 方法绘制条件频率分布图
# conditions 参数指定要绘制的条件(文本文件名),samples 参数指定要统计的事件(情态动词)
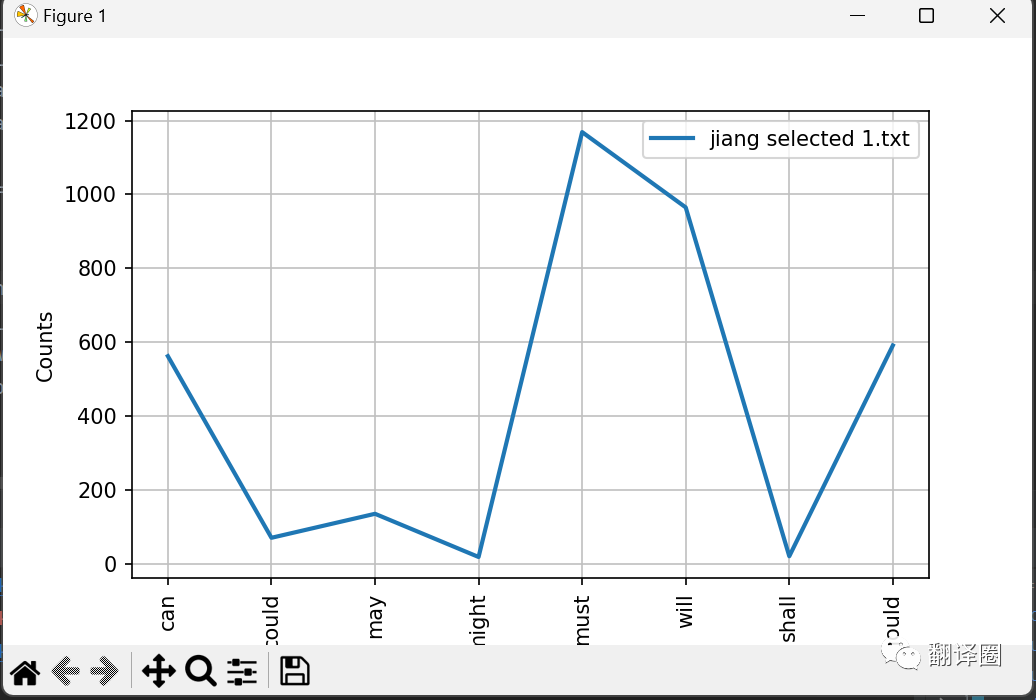
cfd.plot(conditions=corpus_text, samples=count_word)
运行结果如下:
每日啃一段代码,日积月累,我们可以跨越这条鸿沟,若是还未入门Python,可加入我们的微信公众号“翻译圈”粉丝群免费获取《第一本书Python》,快速入门!
往期代码合集可在公众号后台回复代码分享或者加入粉丝群获取,粉丝群还有其它资源哦!

参考书藉:Python语言数据分析 管新潮 著
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
原文作者:吴志雄
推文编辑:吴志雄
