
1. 术语识别:
2. 术语应用
泛指在术语数据库或术语系统中进行术语的搜索、识别和编辑等功能。在创建术语库的时候,通常会明确术语库的使用对象、使用范围、语言对、术语结构、设计字段、定义层级结构以及项目其他属性等信息。在翻译的时候,系统可以自动识别译文中的相应的术语,并根据设置的规则,相应地插入到译文区。用户也可以在单独的一个或多个术语库中进行串行或并行搜索,快速找到所需要的专业术语。用户也可针对某个术语或批量的术语进行术语编辑操作,比如,修改术语状态、标记术语级别、删除术语信息等。
1. 创建术语库
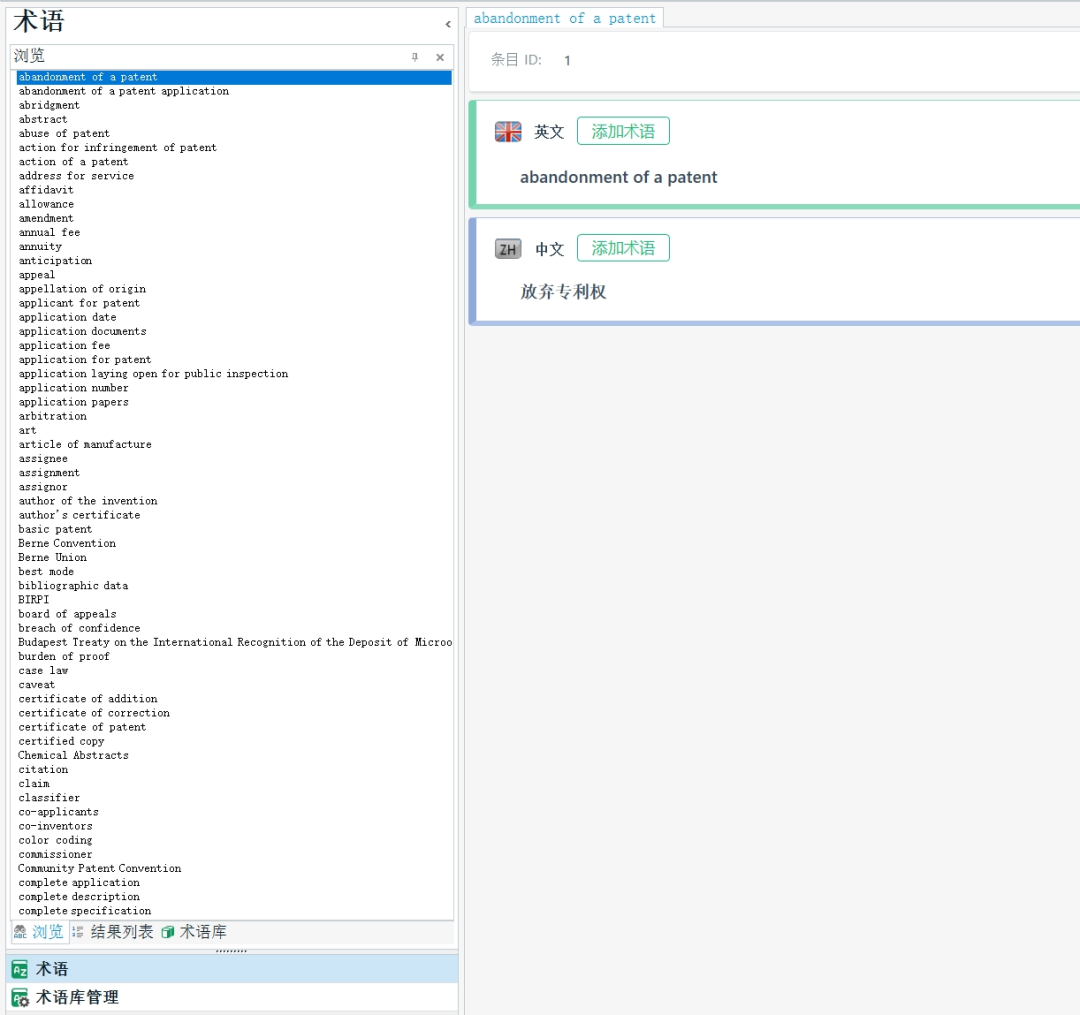
图1 专利术语库
2. 导入术语库
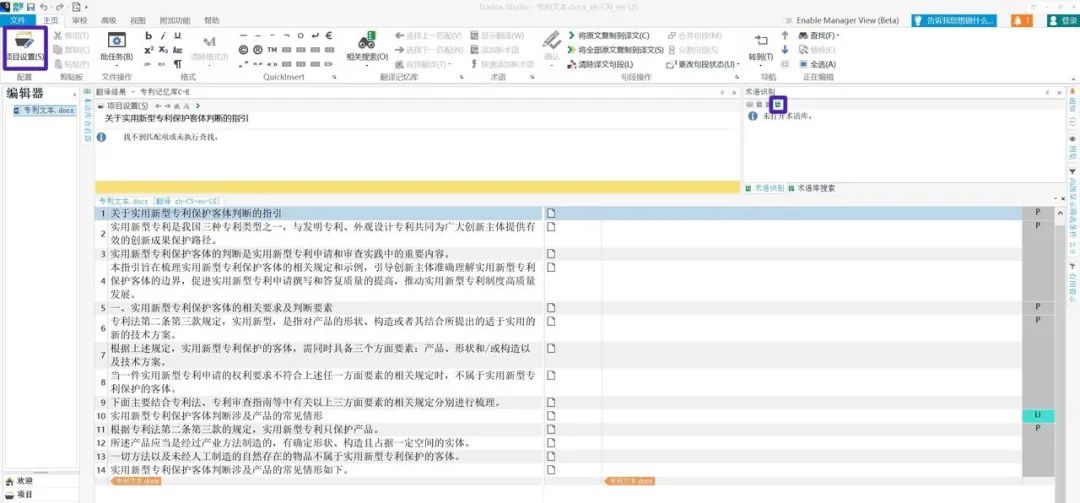
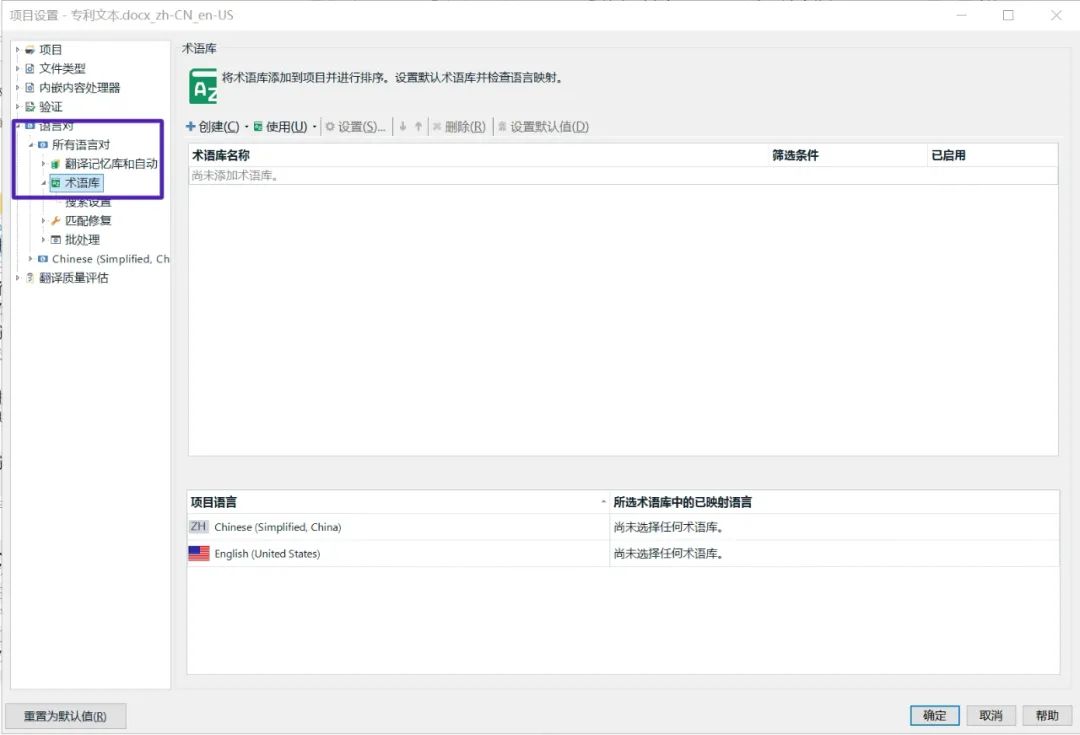
点击[使用],选择[基于文件的MultiTerm术语库]

3. 在实例中识别及应用术语
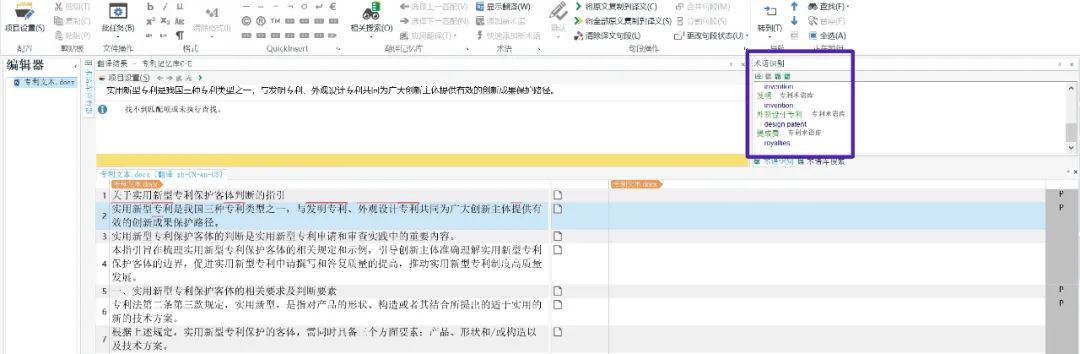
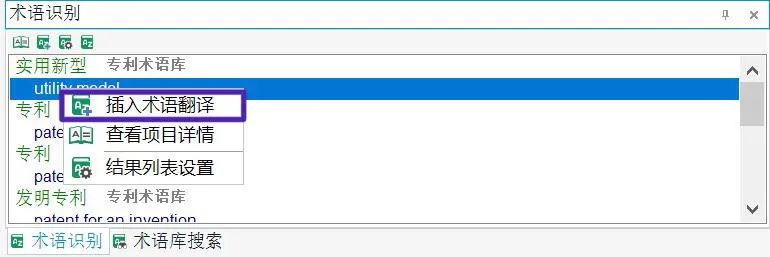
右键点击术语译文,选择[插入术语翻译],如图6所示,
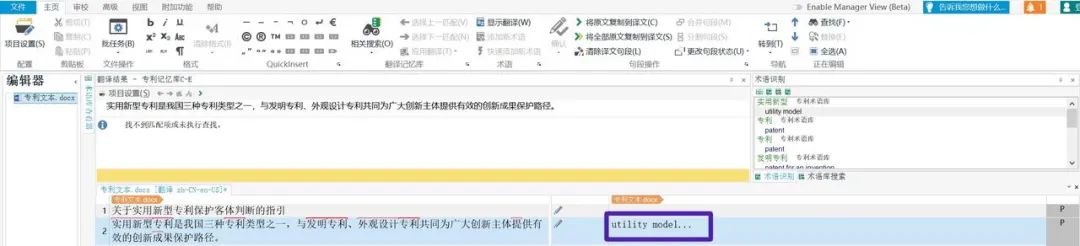
即可将术语的译文插入译文框内,如图7所示
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
原创来源:北外CAT课程展示-蒋伊凡
推文编辑:蒋伊凡
