
基于神经机器翻译的科技文本译后编辑模式研究


摘 要:神经网络(NNs)技术是当前机器翻译引擎的主流翻译算法。相较于统计机器翻译,以神经网络为基础的机器译文流畅度提升明显,但其在垂直领域的表现仍有待改善。本文以谷歌翻译、DeepL翻译、腾讯Transmart以及百度翻译四大互联网主流机器翻译平台为工具对科技类文本进行英汉翻译测试,经统计得出神经机器译文存在五种常见错误类型。结合机器翻译实例对错误译文归类分析,提出相应的译后编辑模式建议,以促进神经机器翻译系统有针对性地改进。
关键词:神经机器翻译;译后编辑;科技翻译

21世纪是高度信息化的时代,目前人们每天在互联网上传输的数据量已经超过整个19世纪的全部数据的总和(冯志伟,2011:13)。数据的指数级增长之下,传统人工翻译已经难以满足跨语言交流的翻译需求,机器翻译已成为当今译者工作的主要生产环境之一(赵涛,2021:100)。神经机器翻译(NMT)即以神经网络作为基础的机器翻译(单宇,2022:9),在翻译技术领域具有里程碑式的意义,其问世标志着机器翻译系统由统计技术阶段迈入了全新的神经网络阶段。百度、谷歌等国内外大型科技企业先后于2015年至2016年间推出NMT平台,目前已成为机器翻译平台的主流技术。
2.1 机器翻译
根据国际标准化组织(International Organization for Standardization,2017:1)的定义,机器翻译指使用计算机应用程序将文本或语音从一种自然语言自动翻译为另一种自然语言,其技术基础通常被划分为基于规则、基于统计和基于神经网络的三个算法阶段。当前广泛使用的基于神经网络的机器翻译主要包含编码器和解码器两部分,编码器通过神经网络变换将源语言表示成高维向量,再由解码器翻译成目标语言。
神经网络机器翻译自2014年兴起,其译文质量在近几年实现飞跃,翻译流畅度在某些语种上甚至超越了基于统计的机器翻译方法。在专业领域上,基于充分的训练语料,其译文准确率可达75%,新闻文本可达70%左右(宗成庆,2020:2)。凭借速度优势,机器翻译在商业领域很受欢迎,主流神经翻译系统字数上限内的译文生成时间普遍在一分钟之内,相较于人工翻译更加高效。
2.2 机器翻译的缺陷
尽管机器翻译在某些领域已具备一定水平,但由于缺乏对语境和文体风格的解码识别能力,翻译系统无法像人工译者一样解读作者的写作用意,只能适用于客观性较强的文本。
2.3 机器翻译译后编辑
译后编辑是指编辑和更正机器翻译的结果,其目的是检查机器翻译的准确性和可理解性,改进文本,提高文本可读性。在达成尽可能保留机器翻译结果的共识之下,根据翻译结果的目的和客户要求,译后编辑可分为深度译后编辑(full post-editing, or FRE)和轻度译后编辑(light post-editing, or LPE)。
本部分选择科技类文本进行英译汉测试,分别用谷歌翻译、DeepL翻译、腾讯Transmart以及百度翻译四类翻译平台对筛选并处理后的语料进行翻译测试,讨论常见错误类型并提出相应译后编辑模式建议。
3.1 译前处理
译前处理包括材料选取、文本转换、语料对齐等一系列准备工作。本文从《经济学人》(The Economist)科技板块选择测试语料,统一格式并删除冗余信息后,将文本分别输入机器翻译测试系统,使用Excel表格将输出译文与原文进行人工对齐,在经过对比分析后统计常见错误类型。
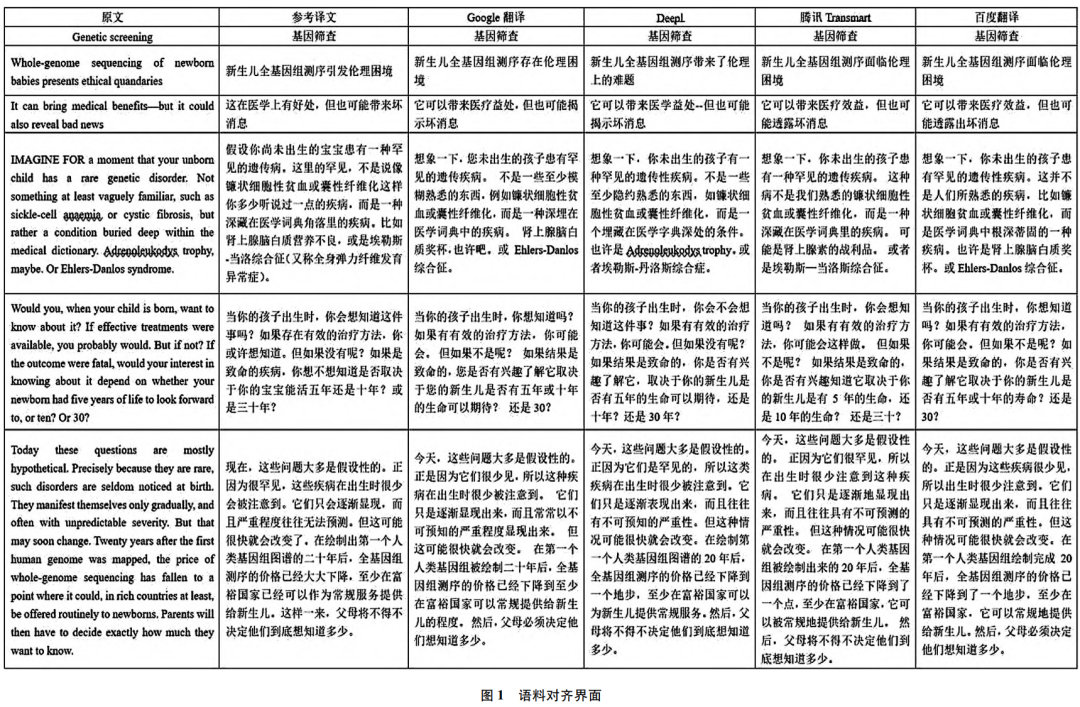
3.2 常见错误类型分析
文献将机器译文在科技类文本上的常见错误类型分为词类错误、句法错误、回译错误、双关错误、数字符号错误五大类(见表1),由具体实例分别加以说明(受篇幅限制,此处不再赘述,需要参阅者可自行下载原文),并提出相应的译后编辑模式(见表2)。
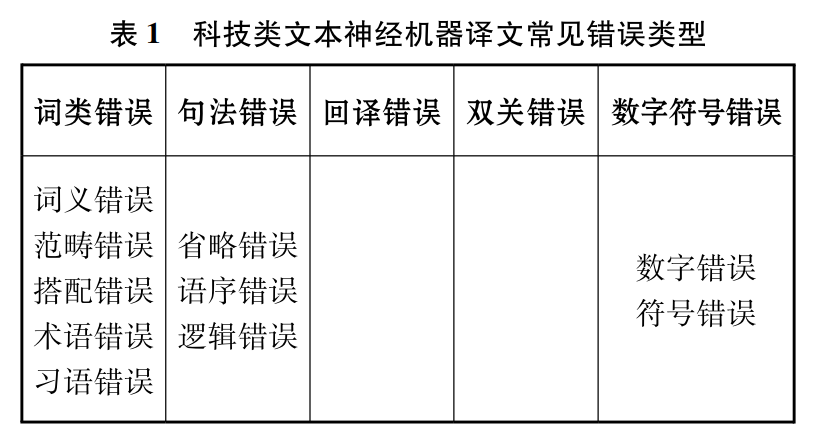
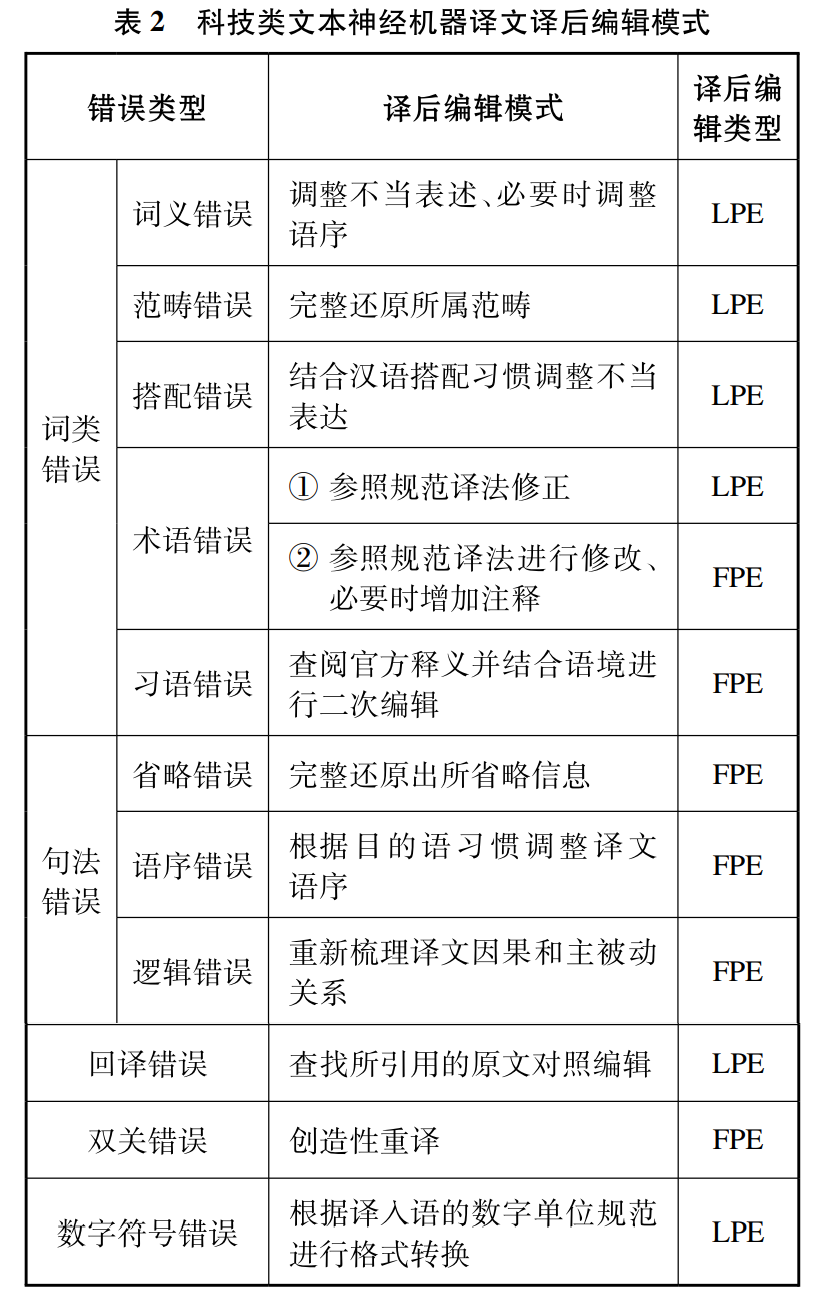
本文使用四类当前市面主流的神经机器翻译平台对科技类文本进行英译汉测试,归纳常见错误类型,并提出相应译后编辑建议。基于神经网络模型的神经机器翻译系统虽然极大提高了译文流畅度,但其错误类型却更加难以预测,这类错误隐藏在流畅的行文中,加大了译后编辑的难度(贾艳芳、孙三军, 2022:18)。译者在利用翻译技术时不仅要做好译前准备,还需提升自身语言敏感度。神经机器翻译平台应合理利用权威术语库资源,并根据各项语料参数生成备选译文,以提高机器翻译的准确度和采用率,最大化发挥技术为语言服务带来的优势。由于机器翻译实践中的文本风格复杂多变,错误类型难以穷尽,故本文所总结的误译情况具有一定局限性。
参考文献略,欢迎点击“阅读原文”进入知网查阅该文章。
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
翻译技术教育与研究——机器翻译译后编辑专题组致力于普及机器翻译译后编辑(MTPE)相关知识,追踪国内外机器翻译译后编辑教学与研究动态!
推文编辑:赵恩婷 王晨谕
