
2023年堪称AI发展元年,在一年的光景里,AI从文字生成向视频、动画、音乐、游戏等多领域蓬勃发展。在即将到来的2024年,相信Ai图像生成工具会为我们带来更多惊喜。
此外,有几个重要的AI工具更新:
-
Video Poet:VideoPoet – Google Research

近期,Google推出了强大的零样本视频生成模型Video Poet。在和市面上主流模型的对比中,该工具可以生成更为逼真的视频。从Video Poet提供的演示动画可以看出,无论输入任何文本提示,都可以生成炫酷的动画效果。
Video-to-audio则更加强大,也是Poet独有的功能。我们可以要求Poet根据生成的视频输出对应的音频。和其他视频生成模型不同的是,Poet引入了多模态功能,可以实现视频风格化、音频生成、视频延伸等功能。
Visual narratives则是在原始提示词后方加入特效提示词,不但可以延伸视频,还能添加炫酷的视觉效果。此外,Poet还可以在保持视频结构的前提下理论上实现无限延长。
Video editing功能可以在保持视频主体特征的前提下,通过修改提示词的方法改变物体的动作和姿势。Interactive video editing,也叫做交互式视频编辑,可以精确控制视频的运动类型。
Images 2 video功能无需像pika, runway一样调整镜头和方向,输入提示词即可控制视频的运动方式。
零样本风格化功能可以通过文本提示的方法,改变视频的风格,无需加载额外的模型。
目前,POET还在研发中,不过根据Google的特点,一个新的模型从研发到推出,往往需要花费很长的时间。
-
文本控制动画生成模型:https://pi-animator.github.io/

近期,上海人工智能实验室推出了一个名为PIA的模型,可以通过文本提示词控制图像中人物的动作,并转换为视频。在参考图的基础上,输入文本提示就可以改变人物的表情和图像的背景。此外,输入不同的提示词,我们还可以控制背景动画的运动幅度。该工具的推出将会让动画制作变得更简单。
-
Leonardo新功能:AI Art Generator – Create Art, Images & More | Leonardo AI
本周,Leonardo向部分用户开放了motion beta功能,该功能可以把图像转换为动态视频,解支持360度旋转。如果你是高级用户,就可以提前试用该功能。
-
StreamDiffusion:GitHub – cumulo-autumn/StreamDiffusion: StreamDiffusion: A Pipeline-Level Solution for Real-Time Interactive Generation
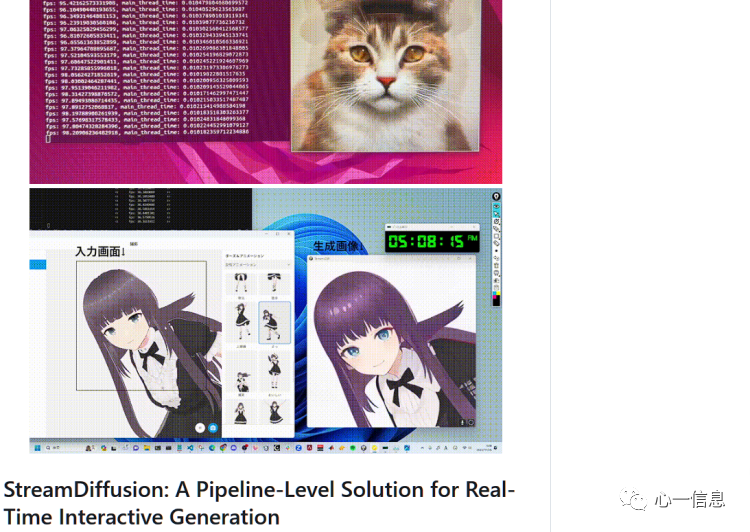
本周,StreamDiffusion正式开源,该项目可以实现每秒100 FPS的图像生成速度。StreamDiffusion不但具备超高速的实时图像生成能力,还可以把直播内容实时转换为各种风格的视频。连接上VR设备或者摄像头,就可以实时生成动画。
-
DreamTuner:DreamTuner (dreamtuner-diffusion.github.io)
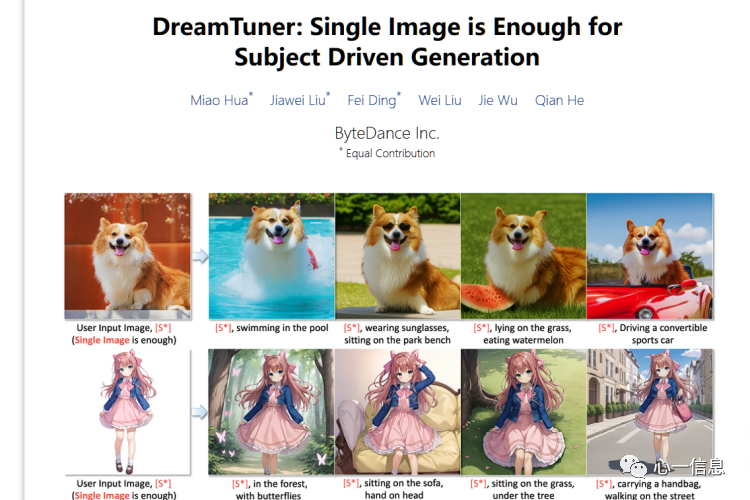
字节跳动在近期发布的DreamTuner工具可以解决生成角色一致性的问题。仅需要一张参考图,DreamTuner就能生成不同表情、不同场景的图像。除了动漫作品,DreamTuner对真实图像的处理也有不错的表现。在和controlnet结合后,还能生成连续稳定的动作。不过,该项目目前还没有开源。
-
Suno新动作:Suno AI

上周,Suno宣布和微软合作,在copliot中添加音乐生成插件。中国用户可以登录到copliot,切换到美国节点,就可以开启该插件。
此外,Suno的官网也完成了升级,新界面充满了科技感。登录到Suno的后台,点击左侧的make holiday song,就可以自动生成两首圣诞主题的音乐,无需添加提示词。如果想要自定义歌词,还可以切换到Custom模式,输入歌词和流派,在即可生成歌曲。
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
转载来源:心一信息
转载编辑:李丹
