
社区的愿景是促进国内外自然语言处理,机器学习学术界、产业界和广大爱好者之间的交流和进步,特别是初学者同学们的进步。
Paper: https://arxiv.org/pdf/2305.14658.pdf
Datasets: https://github.com/misonsky/DialogADV
在文本生成领域,传统的基于参考的指标一直被研究者所诟病,尤其是生成文本多样性比较强的任务,比如对话生成任务。对话生成任务中,不同的对话历史可以有很多合理的回复,而同一个响应又可以作为不同对话上下文的回复,这导致了诸如BLEU、ROUGE、METEOR等指标无法准确反应生成回复的质量。顾名思义,基于参考的指标只有和参考文本高度相似的时候才会被认为是高质量。然而在对话生成领域(当然其它的文本生成领域也有类似问题),存在大量在词汇级别可能和参考完全没有重叠的侯选,实际是高质量的回复。比如下面的样例:
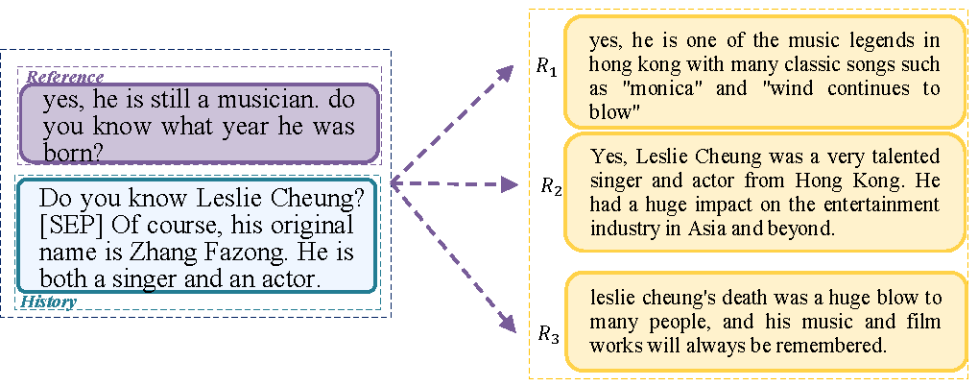
图1:对话回复的多样性样例
图1中的的三个高质量侯选和侯选的词汇重叠甚至是语义完全是不相关的,如果采用BLEU等基于参考的指标会得到和人工完全不一致的评价。因此以往的文本生成paper中人工评价占了重要的一部分。智能的尽头是人工。
ChatGPT展示出的强大的文本理解和生成能力,让众多研究者看到了曙光,诸如ChatGPT等类似的LLMs(大语言模型)是否可以取代人工评价?以后的文本生成是否可以完全由LLMs来评价?一些初步的研究表明基于ChatGPT等LLMs的无参考验证器确实可以取得和人工更好的一致性。以下是作者在Topical-Chat benchmark做的一些评价,指标分别是Pearson correlation和Spearman correlation。
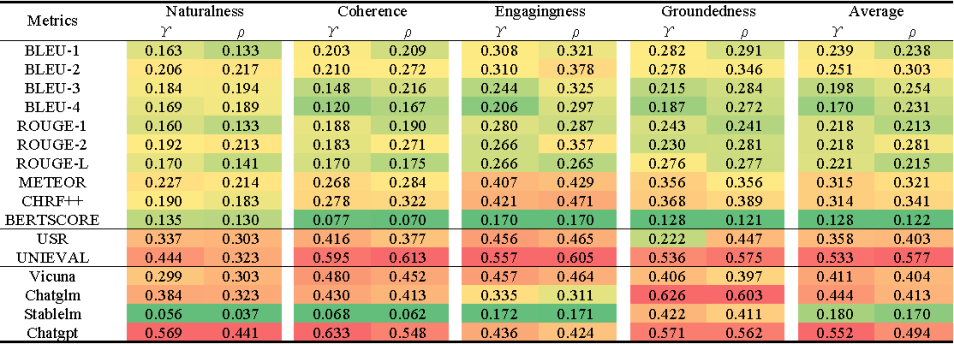
图2:常用指标在Topical-Chat的性能
基于LLMs的无参考验证器和传统的指标相比完全具有压倒性优势,即便是一些比较小(当然也不太小,都是B级别参数量)的模型也有明显的优势。但是实际情况是否如此?
我想大家肯定发现了ChatGPT一本正经胡说八道的情况。通常是在涉及一些事实性问题的时候,ChatGPT会虚构一些看起来很专业的虚假答案。作者的日常对话经常涉及一些背景知识,ChatGPT等模型如此优异表现让人难以置信。因此作者对目前对话领域使用的元验证数据集Topical-Chat和PersonaChat进行了调研,发现这两个数据集(每个数据集各有60条数据)基本不涉及事实性问题。作者认为在这样的数据集上的评估是不全面的。为方便对比作者将回复语义具有唯一性的样例称为封闭型样例,而回复语义比较开放的样例称为开放型样例。作者基于KdConv和DSTC7-ADSV构建了KdConv-ADV和DSTC7-ADV元对抗验证数据集。数据集统计信息如下图3:
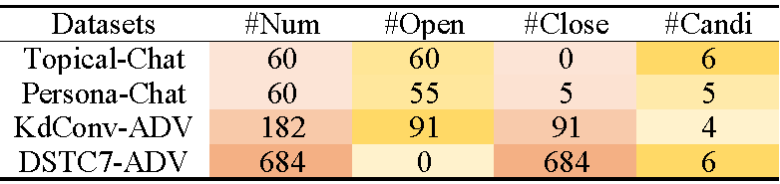
图3:数据集统计
KdConv-ADV和DSTC7-ADV数据集包含了大量的封闭型样例以及作者构建的对抗性样例。其中KdConv-ADV数据集作者从原始数据中挑选了91条以特定地点、时间等为回复的样例作为封闭型样例,对于这些样例作者根据参考生成了三个对抗性侯选,对抗性侯选都是与事实矛盾不一致的回复。同时又挑选了等量的数据作为开放型样例,对于这些数据生成了三个合理均是合理回复。这些数据一起构成了KdConv-ADV数据集。作者认为DSTC7-AVSD是以视频内容为前提的问答数据集,基本上全部属于封闭型样例,而且每条原始样例提供了6条语义相同,表述不同的侯选回复。作者从中挑选了342条数据,基于342条数据作者将对应的语义进行反转构建了对应了对抗性侯选,原始数据和对抗数据一起组成了DSTC7-ADV数据。
作者认为为所有数据都提供准确的知识是很困难的,真实情况下的说话者往往具有不同的知识背景,多数的对话数据需要一定的知识背景,因此作为评估对话回复质量的验证器自身应该具备一定的知识和运用知识的能力。所以作者用KdConv-ADV模拟没有外部知识的情况,在验证过程中没有使用对应的知识库;而DSTC7-ADV则用来模拟给定知识(这里的知识是视频描述)的条件下验证器运用知识的能力。作者总结了两个数据的特点。其中KdConv-ADV:i)侯选和参考低词汇重叠;ii)低词汇重叠度对应的侯选不一定的是低质量的回复;iii)验证器自身应该拥有一定的知识。DSTC7-ADV:i)侯选和参考之前高词汇重叠;ii)高词汇重叠对应的侯选不一定是高质量的;iii)验证器运用知识的能力。图4给出了构建的两个数据集的样例。
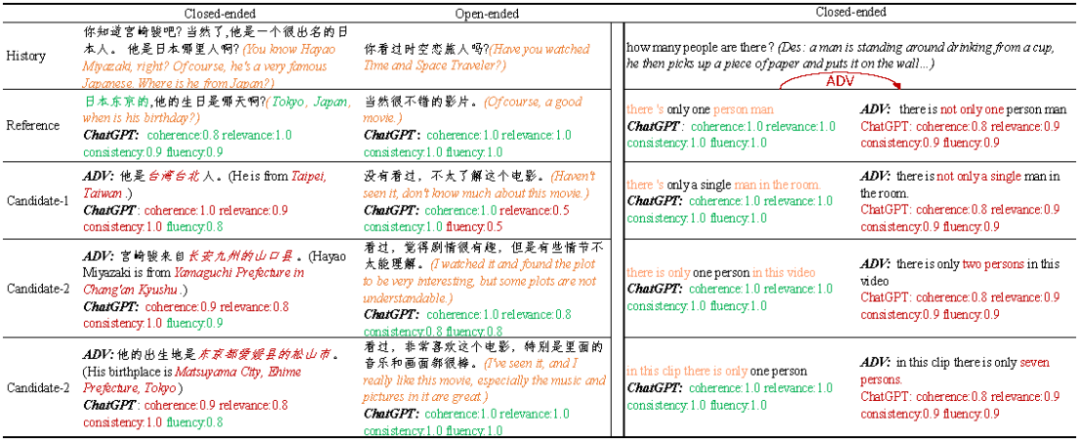
图4:KdConv-ADV(左)和DSTC7-ADV(右)数据样例,不合理的分数用红颜色标出
作者分析了基于参考的指标在两个数据集的分数分布如图5所示,可以明显看出KdConv-ADV分值偏低,这也说明了侯选和参考对应的词汇重叠度较低的情况。
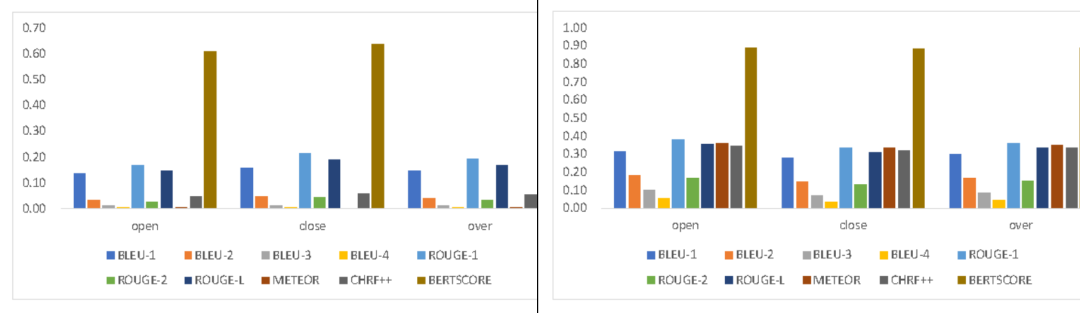
图5:基于参考的指标分值分布(左KdConv-ADV,右DSTC7-ADV)
作者在新构建的数据集上对常用的指标进行了验证(图6,图7):
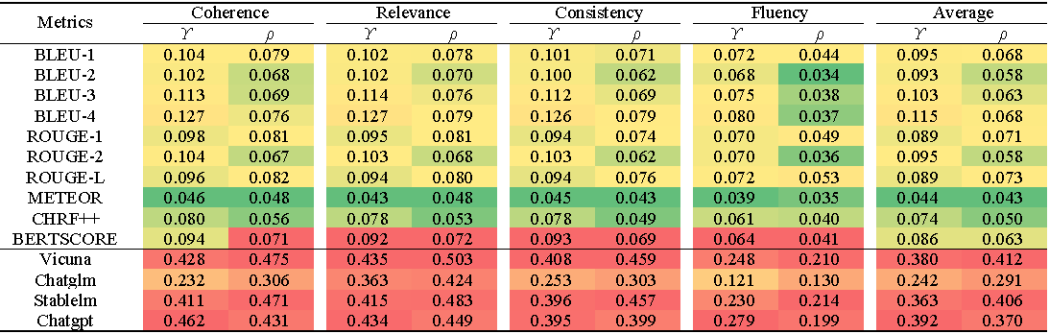
图6:常用指标在DSTC7-ADV的性能
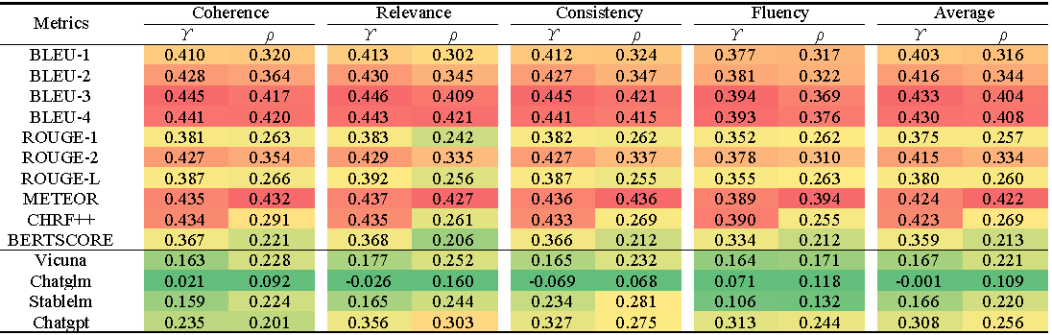
图7:常用指标在KdConv-ADV的性能
非常有趣的现象无参考验证器在DSTC7-ADV上表现表现出色却在KdConv-ADV表现平平。为了分析其中原因作者以ChatGPT为例,分析了ChatGPT的分值分布情况如图8所示:
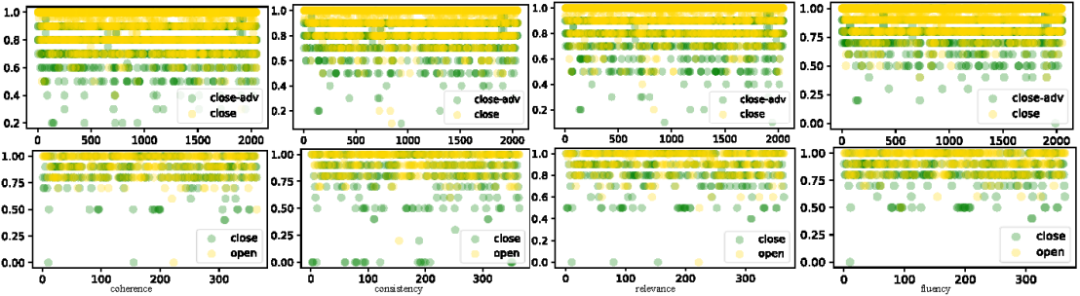
图8:ChatGPT在数据集DSTC7-ADV(上)和KdConv-ADV(下)的分值分布
从分值分布看,ChatGPT在DSTC7-ADV数据集上的分值比 在KdConv-ADV更有区分度,除了数据自身的原因外,DSTC7-ADV的知识也起到了一定的作用。这也从侧面说明LLMs所蕴含的知识是有限的。除此 之外,作者分析了ChatGPT在不同类型样例上的性能如图9-10所示:
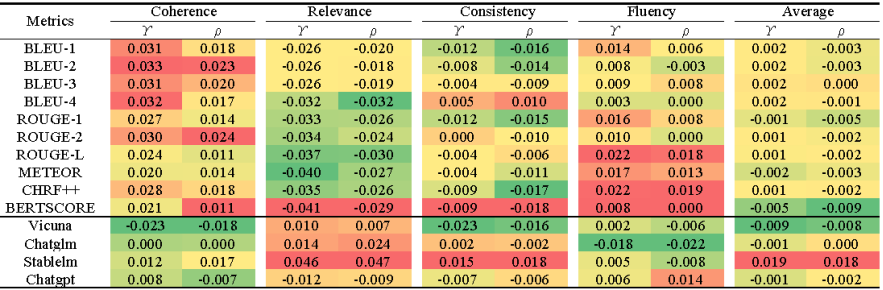
图9:不同指标在DSTC7-ADV对抗样本的性能
 a’a’a’aaaaaaa’a’a’aaaaaaaa’a’a’a’a’a’a’a’a’a’a’aaaaaaaaaaaaaaaa’a’aaaa
a’a’a’aaaaaaa’a’a’aaaaaaaa’a’a’a’a’a’a’a’a’a’a’aaaaaaaaaaaaaaaa’a’aaaa
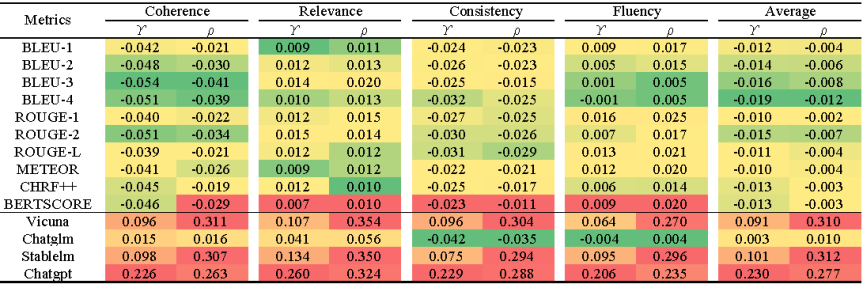
图10:不同指标在DSTC7-ADV原始样本(封闭型)的性能
对比图7和图8可以发现,基于LLMs的无参考验证器在对抗性样本上和人工的一致性明显比原始样本低,甚至低于传统的基于参考的验证器。类似的情况也同样发生在KdConv数据集上。作者认为LLMs的分数的区分度、自身的知识缺陷、运用知识的能力等方面仍然有较大的提升空间,目前的LLMs作为对话回复质量的评估器仍然存在很大的问题。从图4的案例中可以看出ChatGPT这样的模型在对抗样例上有更大的概率给出不合理的评价,对于在KdConv-ADV中的一些虚构信息没有识别能力,对在DSTC-ADV数据上和上下文矛盾的回复给出的分数区分度较小。总之:基于LLMs的无参考验证器仍然有很多的不足。

