
基于自然语言处理的领域分类(1/2)
自然语言处理自动领域分类教程:从数据预处理到人工神经网络的训练和评估。
今天,在互联网和各种组织数据库中有大量的文本数据,其中绝大多数不是以易于访问的方式构建的。自然语言处理(NLP)可用于理解非结构化数据集合,从而实现重要决策过程的自动化,否则需要投入大量时间和精力才能手动实现。
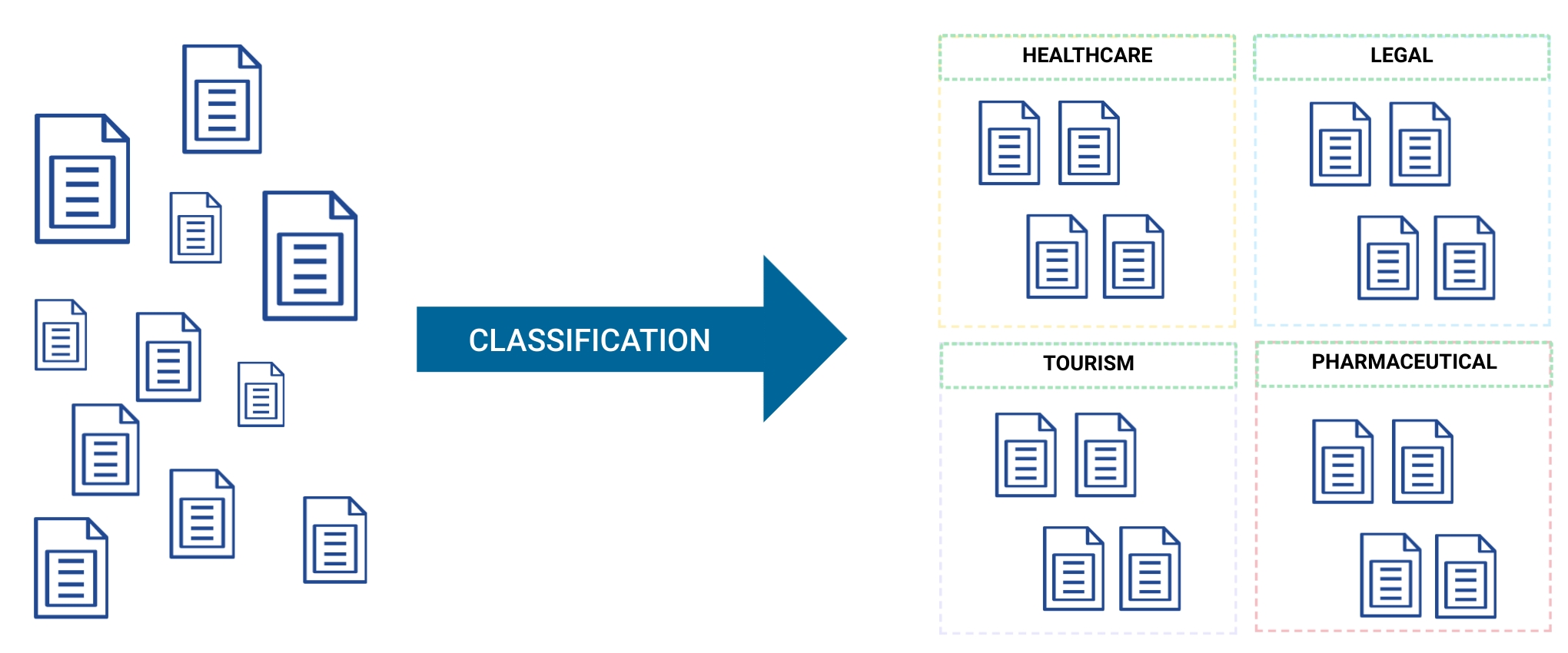
在本文中,我们讨论了NLP用于构建文本数据的一种方式。领域分类,也称为主题标签或主题标识,是一种文本分类方法,用于为各种类型和长度的文档分配文档领域或类别标签。“领域”或“类别”可以理解为对话领域、行业的特定部分,甚至是特定的文本类型,这取决于应用程序。例如,文本数据库可能包含与法律领域,医疗保健,酒店业等领域相关的文档。各组织以这种方式组织其数据,以使单个文档更容易访问,相关信息的检索更有效。
本文附有一个实践教程它引导读者完成从数据预处理到人工神经网络的训练和评估的构建领域分类管道的整个过程。只要具备Python编程语言的基本知识,任何人都可以使用本教程最终在句子层面的领域标注任务中达到约84%的准确率,通过使用BBC新闻数据集了解句子嵌入,一种越来越流行的数字文本表示方法。
应用
自动文本分类方法,如领域分类,使数据所有者能够以可扩展和可复制的方式构建他们的数据,这不仅意味着大量的文档可以在很短的时间内自动排序,而且分类标准可以在更长的时间内保持一致。此外,文本分类方法允许企业获得关于其工具或服务性能的有价值的实时知识,从而实现更好、更准确的决策。
例如,领域分类算法可用于按主题组织非结构化数据库中的文档。这为各种更深入、更具体的应用开辟了道路,这些应用可以包括从分析在线论坛的当前趋势到为机器翻译(MT)系统选择正确类型的训练数据的任何内容。
其他文本分类任务包括自然语言处理问题,如垃圾邮件过滤,情感分析和语言识别,所有这些都有一个共同的基本挑战,即必须理解书面文档中的结构、语言和语义线索,才能成功地为它们分配正确的类别标签。领域识别,以及上面列出的相关任务,为广泛的NLP解决方案提供了基础。
方法
域分类可以手动或自动执行。然而,由于手动文本分类需要专家进行密集的劳动,因此在大数据时代不再适用,我们在本文的剩余部分重点关注自动方法。
领域识别是自然语言处理的一个子领域,自然语言处理是语言学和信息技术的交叉学科。它的目的是利用计算机科学的工具,主要是机器学习(ML)和人工智能(AI),了解人类语言。
文本分类算法通常分为三个不同的类别:基于规则的系统、机器学习模型和混合方法。基于规则的系统在NLP的早期特别流行,它利用精心设计的语言规则和试探法,这些规则和试探法能够识别特定文档语言中的模式,基于这些模式可以应用域标签。他们经常依靠精心制作的单词表来帮助确定给定文本的主题;例如,考虑一下航空类别,可能包含“飞机”、“高度”和“雷达”等词。然而,尽管这种算法在确定一段文本的领域方面表现得相当好,并且它们的内部工作易于理解,但是它们需要相当多的领域专业知识和相当多的努力来创建和维护。

然而,该领域目前由机器学习系统主导,而不是主要基于手动准备的语言规则的应用。这些系统可以进一步分为三大类,即监督系统、非监督系统和半监督系统。
监督机器学习算法从数据点集合及其相应标签之间的关联中学习。例如,通过向模型显示来自各种类别的数千甚至数百万个示例并采用许多可用学习机制中的一种,可以训练ML系统正确识别新闻文章的主题。无论是基于特意选择的特征,如单词袋表示或tf-idf向量,还是模型自己发现的数据特征,它们都能够在预测以前看不见的文本的标签时应用学到的“知识”。监督学习机制包括朴素贝叶斯算法、支持向量机、神经网络和深度学习。
相比之下,当训练集不包含任何标签时,可以使用无监督系统,因此模型必须基本上仅基于它遇到的数据的内部特征进行学习。文本分类中流行的聚类算法就属于这一类。另一方面,半监督ML算法从标记和未标记训练数据的组合中学习关联。
许多领域分类方法采用手工规则和机器学习技术的组合,这使它们成为可靠和灵活的数据增强工具。这些方法通常被称为混合系统。
(机器翻译,轻度译后编辑,仅供参考)
编辑:胡跃
