译学文献 | ChatGPT 应用于中国特色话语翻译的有效性研究

ChatGPT 应用于中国特色话语翻译的
有效性研究
作者简介
文旭,博士,西南大学外国语学院教授、博士生导师。主要研究领域: 认知语言学、语用学、认知翻译学等。
田亚灵,西南大学外国语学院硕士研究生。主要研究领域: 认知语言学、认知翻译学。
文献来源
文旭、田亚灵,(2024),ChatGPT 应用于中国特色话语翻译的有效性研究,《上海翻译》,175(2), 27-34。
欢迎在中国知网查阅下载本文!
摘要
随着中国综合国力的不断提升和国际交流的日益频繁,政治文献中“中国特色话语”翻译的准确性成为传播中国声音和塑造中国国际形象的关键因素。本研究以党的二十大报告为语料,聚焦ChatGPT生成的译文,并将其与市场上主流的三种机器翻译工具——Google翻译、有道翻译和DeepL翻译进行对比分析,旨在评估ChatGPT在政治文献翻译中的有效性。本研究首先使用BLEU和TER两种自动评估指标以量化翻译质量,然后进一步增加人工评估环节,以更全面地洞察其性能表现。结果显示,ChatGPT相对于其他三个翻译工具表现出一定的优势。然而,该模型在处理涉及意识形态、复杂结构、文化负载词、隐转喻等内容以及在翻译准确性上的局限性仍然明显。最后,本研究探讨了翻译在人工智能时代的未来发展趋势。翻译需要在整合现代技术、研究翻译伦理、深入跨文化研究、促进机器与人的协同工作等方面不断发展,以满足翻译实践新的需求,为塑造中国的国际形象提供更全面的支持。
关键词
ChatGPT;二十大报告;译文质量评估;
翻译学
01
引言
在当今数字化、全球化的时代,翻译不再是简单地将一种语言转化成另一种语言的过程。它不仅形成了认知翻译学这一基于认知科学的理论原则与研究工具和方法、深入分析翻译的本质和规律的翻译学分支学科(文旭,刘瑾,肖开容,2021),而且从国家文化软实力的战略高度讲,它已经成为文化交流和知识传播的关键环节。在这个背景下,人工智能的发展正深刻地塑造着翻译新貌。2023年3月15日,OpenAI宣布正式推出GPT-4,它是 OpenAI努力扩展深度学习的最新里程碑。ChatGPT语言模型的崛起,引领人工智能走向了新的发展阶段,为语言文化及翻译研究带来了巨大变革。“无论人们对于翻译的认识如何拓展,翻译质量总是一个不可忽视的问题,往往构成热点话题之一。”( 孙琳,2023:37) 将ChatGPT应用于政治文本翻译,不仅需要考虑语言问题,还需要考虑文化背景、政治语境等复杂要素,所以还需要进一步探究其翻译质量。在翻译的发展进程中,我们必须探讨其如何积极响应人工智能的最新发展,更好地满足全球化时代的翻译需求,同时也需要深入研究这些新技术的潜在风险,为翻译的发展提供建设性的意见。
近年来,ChatGPT应用于政治文本翻译仍处于起步阶段。胡开宝(2023)认为,党和政府一直高度重视对外宣传文献或外宣资料的翻译工作。因此,本研究采用基于GPT-4版本的最新ChatGPT模型,以“二十大报告”中的中国特色话语为例,将ChatGPT译文与其他机器翻译工具的译文进行对比分析,结合BLEU、TER等机器翻译自动测评方法,运用Python对译文BLEU值和TER值进行计算,最后辅以人工评审,旨在多方面、多角度评估该模型的翻译质量,分析其优势和局限,探究其能否助力我们讲好中国故事。本研究有望为将ChatGPT应用于重要政治文本翻译工作提供借鉴和启示,为翻译在人工智能时代的发展提供新的视角和方向。
02
相关研究
不少学者已经关注到ChatGPT给语言教学以及学术写作带来的机遇与挑战。Salvagno和Taccone (2023)认为,ChatGPT能够帮助作者整理材料、生成初稿和进行校对,但也可能会存在抄袭和不够准确的风险。Thorp(2023)明确表达了对ChatGPT应用于学术写作中的强烈担忧,认为ChatGPT不能成为作者。袁毓林(2023) 详细介绍了ChatGPT的技术原理、工程构架和相关实验,全面分析了ChatGPT在包括翻译领域在内的自然语言处理领域的发展潜力和局限性。
ChatGPT所提供的机译服务超越了普通机器翻译,因此它在翻译质量、校对能力和语句优化方面的表现应成为机器翻译和翻译学研究领域的新焦点。(耿芳,胡健,2023)作者发现聚焦ChatGPT与翻译的相关文献较少,且主要集中于以下两个方面: 第一个方面是基于BLEU、TER、CHRF等自动评价指标的翻译质量测评。Jiao等(2023) 对ChatGPT在翻译提示、多语言翻译与翻译稳健性三个方面的表现进行了评估,发现在三种不同风格的翻译提示中,“Please provide the [TGT] translation for these sentences”这一指令能够激发出最佳的机器翻译效果。杨锋昌(2023)使用 ChatGPT 对越南语法律文本进行翻译,通过与其他机器翻译和人工翻译结果进行对比,总结其优势与不足,在此基础上思考ChatGPT对译员的影响。王子云、毛毳(2023)以淄博陶瓷琉璃博物馆中英介绍文本为语料,采用BLEU值和TER值自动评估方法对ChatGPT及其他3种机器翻译工具的翻译性能和译文质量进行综合评估,并总结了可在陶瓷类文本汉英翻译领域中应用的优秀提示语。王和私、马柯昕(2023) 以医学文本为语料,将ChatGPT和常用的翻译工具进行对比,从词汇翻译的角度对其译文质量进行分析。第二个方面涉及到 ChatGPT 对语言和翻译所带来的优势和困境。王立非、李昭(2023) 强调了 ChatGPT 作为AIGC工具在加速智能翻译和语言服务时代到来方面的作用。他们提议增设行业相关课程,以实现从语言翻译教学到语言服务教学的转变,并培养译者的数字人文素养。朱光辉、王喜文(2023) 认为,ChatGPT这种AI运行模式可以为同声传译和多语言教学应用内容翻译提供支持。
以上研究分析了ChatGPT对翻译领域带来的巨大影响,但鲜有文章关注其应用于政治文本翻译的有效性,在中国进入新时代的大环境下,反思和探索新事物的宏观视野和理论体系也有待进一步发展。“要有效衡量译文质量的优劣就必须遵循一定的评价标准”( 王金铨,牛永一,2023:52) ,目前在测评ChatGPT 应用于翻译的有效性研究中,要么是文章作者自身对译文质量进行评析,要么是仅应用一种或两种机器测评方法,缺乏人工测评。王金铨、文秋芳(2010) 认为,不能单独使用BLEU来检测译文质量,要使用其他相似的测量工具互为补充。同时,因为机器测评过于死板,且只能反映译文的部分情况,复杂程度不同的翻译文本在机器测评中的分数相差很大,且不能对语义变量进行更深入的挖掘,所以还需要人工评阅作为补充。更为关键的是,目前学界广泛应用ChatGPT-3.5来测试其翻译水平。朱光辉、王喜文(2023) 提出,ChatGPT-3.5 是一个拥有1750亿参数的模型,而最新推出的GPT-4将是一个拥有超100万亿级别参数的大模型,一旦GPT-4实现 100 万亿参数规模,就意味着它将达到与人类大脑神经触点规模同等水平。ChatGPT-3.5和ChatGPT-4的各种能力存在巨大差距,在最新版本已经面世的情况下,应用 ChatGPT-3.5所做的测试,其结果恐怕缺乏一定的准确性和真实性。
03
研究设计
01 研究问题
本研究旨在讨论以下三个问题:第一,ChatGPT作为机器翻译工具,其生成的翻译结果质量如何?第二,ChatGPT是否有潜力替代人工译者在特定文本翻译中的功能?第三,在人工智能时代,翻译的未来发展方向如何?
02 文本选择
文本选自二十大报告,蕴含着丰富的中国特色话语,是中国独有的语言表达形式。通过对二十大报告中中国特色话语的定性研究,发现其主要有以下几个特征:
第一,语言结构工整。在词汇层面,二十大报告中的中国特色话语大量使用四字结构,表意精确、言简意赅,在句子层面多用并列结构和排比结构。第二,文化内涵深厚。二十大报告作为国外了解中国的重要窗口,其用语文化内涵深厚也在意料之中。第三,政治思想深邃。朱义华(2017)认为,在国家层面的外宣翻译中通常需要重视国家利益、政治观点和意识形态等因素,这反映出外宣翻译具有显著的政治特性。二十大报告对国内外重大事件作出了精确、权威的判断和论述。第四,时代特色鲜明。党的二十大提出了一系列新观点、新论断、新思想、新战略、新要求,语言与时俱进,富有时代特色。第五,政治隐转喻丰富。“从实际的操作层面看,隐喻之所以在政治话语中具有重要的地位,是因为隐喻能以特定的模式框架政治议题,设定议题解决的方向,从而提供阐释框架以影响政治决策。”(文旭,2014:13)政治隐喻深植于中国传统文化和价值观,不仅能激发情感、引导意识形态,还是讲好中国故事、传播好中国声音的关键。而转喻与翻译作为转喻的应用研究,将概念转喻理论应用在翻译理论与实践之中,这种理论与实践的有机结合大有可为。(魏在江,2021)二十大报告中大量使用政治隐转喻。
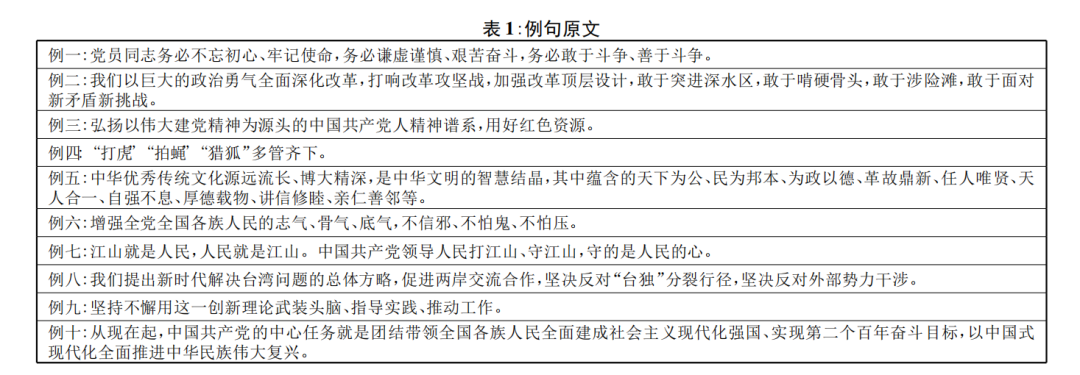
根据以上特点,本文在二十大报告中有针对性地选取10个例句,共获取中文文本459个字符,参考英文译文419个字符。所选例句原文如表1:
03 研究方法
BLEU(Bilingual Evaluation Under Study)是一种广泛使用的机器翻译评估指标。(Papineni et al.,2002)这个指标通过与人工翻译进行比较来评估机器翻译的质量。BLEU的评分机制主要基于n-gram精度,即检查机器翻译中的n-gram在参考译文中出现的频率。其得分通常在0到1之间,数值越高,表明译文质量越好。该指标具有简单、计算速度快等优点。尽管有局限性,BLEU仍然是业界最常用的机器翻译评估指标之一。
TER(Translation Edit Rate)是另一种用于评估机器翻译质量的指标。与BLEU不同,TER是一种基于编辑距离的指标。简而言之,TER量化了将机器翻译结果变为与参考翻译完全一样所需要的最小编辑操作的数量。得分通常在0到1之间,数值越高意味着质量越低,可以更准确地捕获到细微的译文差异。(Snover et al.,2006)总体而言,TER是一个有用的补充指标。通过结合两种不同的指标来评价机器译文的各个方面,可以实现对机器译文质量更加全面、精确的评估。
与此同时,作者通过问卷的形式,将10个例句在4种翻译工具中所产生的译文发送给翻译专业资深教师,在不知道译文来源的情况下对译文质量进行评分,计算10个例句的整体得分情况并进行分析,从而多方面、多角度评估该模型的翻译质量。
04 研究过程
ChatGPT的使用和“prompt”息息相关,不同的“prompt”会产生不同的结果。因此,在测试时为避免出现不同的翻译结果,我们需要统一提示语以尽量确保测试结果的效度和信度。其他翻译工具无需考虑此问题,输入源文本会自动生成目标语文本。
在“prompt”相同的情况下,我们对比了ChatGPT-4与其他三个机器翻译工具所产出的译文质量,包括Google翻译、有道翻译以及DeepL翻译。我们首先对比分析ChatGPT-4与其他三种机器翻译工具在处理二十大报告中“中国特色话语”的BLEU值和TER值,再结合人工评估,综合评判ChatGPT-4的翻译质量。这不仅能从定量的角度了解各个工具的表现,还能从定性的角度补充这些量化指标可能忽视的细节。这样的多角度、多层次的评估方法更可能揭示出ChatGPT-4的优缺点,进一步推动机器翻译技术的发展和优化。
04
研究结果与分析
本文以“Please provide the [TGT] translation for these sentences”作为ChatGPT的翻译提示语来获得译文,然后将ChatGPT生成的译文与其他三种主流机器翻译工具译文进行对比,并分别计算了它们的BLEU分数和TER分数。
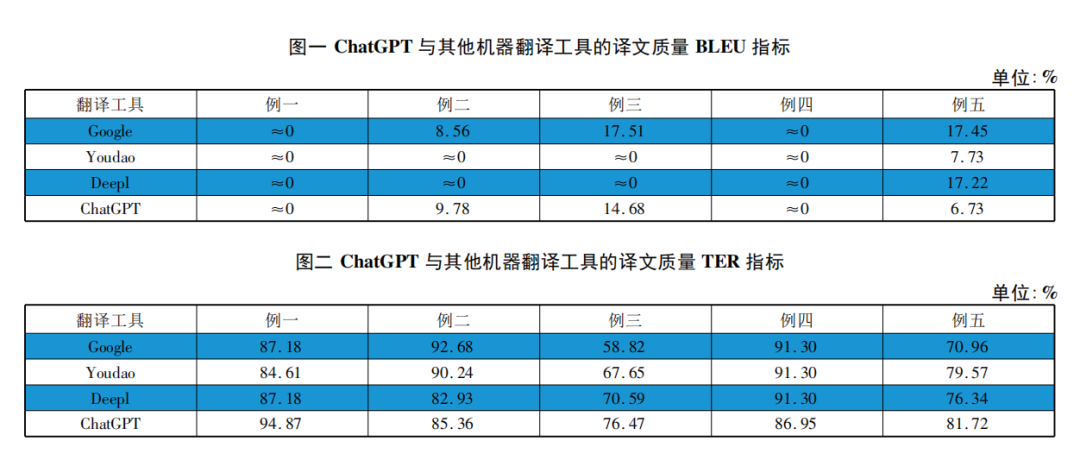
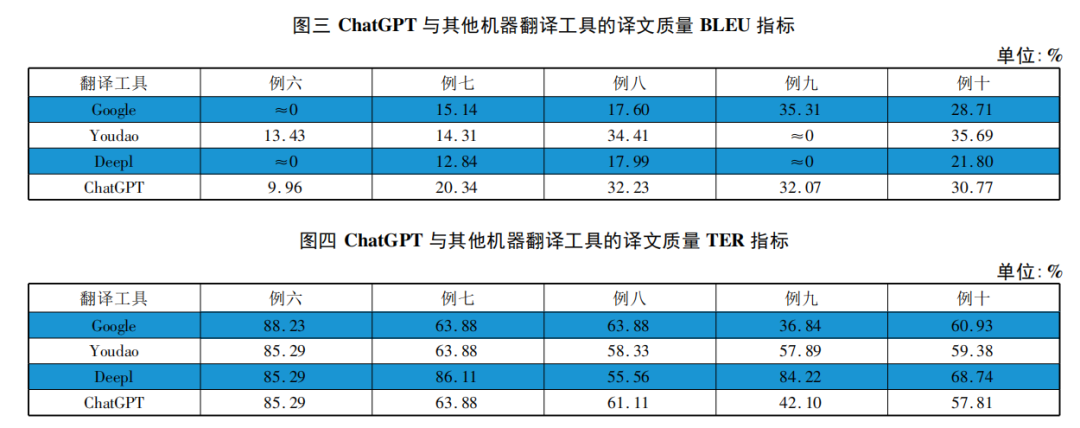
经过Python计算,所选10个例子的BLEU值及TER值结果如图一、图二、图三、图四所示。
我们拟从以下三个方面对四种翻译工具在BLEU值测评中的表现进行初步分析:
(1)整体充分性和流畅性。周成彬、刘忠宝(2022)认为,一个翻译工具生成译文的BLEU值如果达到31.4%,就表明该译文质量良好,达到了机器翻译的基本要求。依据图一和图三所示数据,我们计算了10个例句译文的BLEU值。统计分析显示,ChatGPT的平均BLEU值最高,为15.66%;Google翻译次之,平均BLEU值为14.03%;有道翻译平均BLEU值为10.56%;DeepL翻译的平均BLEU值最低,为6.99%。这些数据表明,在译文的充分性和流畅性方面,四种机器翻译工具的翻译质量均未达到机器翻译的良好效果,在充分表达原意和语言自然流畅方面都还有很大的提升空间。但从四种翻译工具内部对比看,ChatGPT的翻译质量相对最优,其生成的翻译与参考译文的匹配度相对最高。
(2)高质量翻译频次。对图一、图三数据进一步分析计算,我们发现在四种机器翻译工具中,ChatGPT译文在具有较高BLEU值(超过31.4%)的频次虽然和有道翻译相同,均为2次,但ChatGPT生成的例十译文的BLEU值为30.77%,也接近31.4%,而Google翻译为1次,DeepL翻译为0次。从高质量翻译出现频次这一评判指标来看,仍然是ChatGPT表现相对更优。
(3)“托底”能力。值得注意的是,各种翻译工具的译文均出现了BLEU值约等于0%的情况,这意味着机器翻译的输出与人工生成的参考翻译差异极大,几乎没有相似之处,所以我们还应该关注各翻译工具的“托底”能力。BLEU值约等于0%的频次越多,说明该翻译工具的翻译质量越不稳定,“托底”能力就越差。经过计算,ChatGPT各译文的BLEU值为0%的频次最少,为2次,Google翻译为3次,有道翻译为5次,DeepL翻译为6次。这进一步证实了ChatGPT相对优越的性能。
四种翻译工具译文的BLEU值均较高的几个例句为例八和例十,而四种翻译工具译文在例一、例四的BLEU值都几乎趋近于0%。其中原因有待探析。例一译文的BLEU值趋近于0%,其多用并列结构以及四字动宾词语,言简意赅,表意精确。例四多用隐喻,用“虎”“狐”“蝇”来代指各级贪官污吏,机器翻译几乎无法识别这些带有中国特色的概念隐喻。例八译文的BLEU值较高,其几乎没有文化负载词,讨论话题也较为简单。同样,译文BLEU值较高的例十为结构简单、语言平实的长句。值得注意的是,尽管BLEU是一个有用的指标,但它并不能完全捕捉翻译所有的复杂性和细微差别。因此,一个低BLEU分数(包括0%)不一定总是意味着完全无用或不准确的翻译。BLEU主要用于评估整体系统性能,而不是单个翻译实例。此次测试证明,结构简单的长句更具有整体系统性,因此,长句的BLEU值较高。
学界对于TER(Translation Edit Rate)的标准并不是固定的。通常来说,TER的值越低,表示机器翻译质量越高。然而,译文的TER值为多少可以被认定为质量“不错”,学界仍未有定论。TER值被定义为使机器译文与参考译文完全匹配所需的最小编辑次数,数值越高说明机器翻译的质量越差。就图二、图四来看,在TER指标上,四种翻译工具平均数值均高于70%,DeepL翻译数值最高,为78.83%,其次为ChatGPT和有道翻译,数值分别为73.56%和73.81%,而Google翻译数值最低,为71.47%。政治文本的译文要求准确传达源语文本信息,同时确保翻译文本在目标语言中具有流畅性和可理解性,TER平均值超过70%,明显不能说其为“良好”的翻译。这些数据表明,在译文词汇和语法的准确性上,四种机器翻译工具的翻译质量均未达到机器翻译的“良好”效果,但对比四种翻译工具,Google翻译的表现最为出色,紧随其后的是ChatGPT,而有道翻译和DeepL翻译在这方面表现略为逊色。
总体而言,在政治文本中“中国特色话语”的汉英翻译任务中,ChatGPT在多个评价指标上均与其他主流机器翻译工具相当,甚至略有优势,但仍未达到颠覆性的水平,特别是在处理含有特定文化负载词、结构复杂的短语以及识别隐转喻时,现有的机器翻译工具,包括ChatGPT,都存在明显的局限性。
BLEU值和TER值提供了一种量化的方式来评估翻译质量,人工评阅可以更准确地捕捉到译文的准确性、语言风格、文化适应性等其他难以量化的方面。两者应结合使用,以获得更全面的翻译质量评估。本次实验邀请了两位翻译方向的资深教授进行人工评阅,评阅结果分别如图五、图六所示。
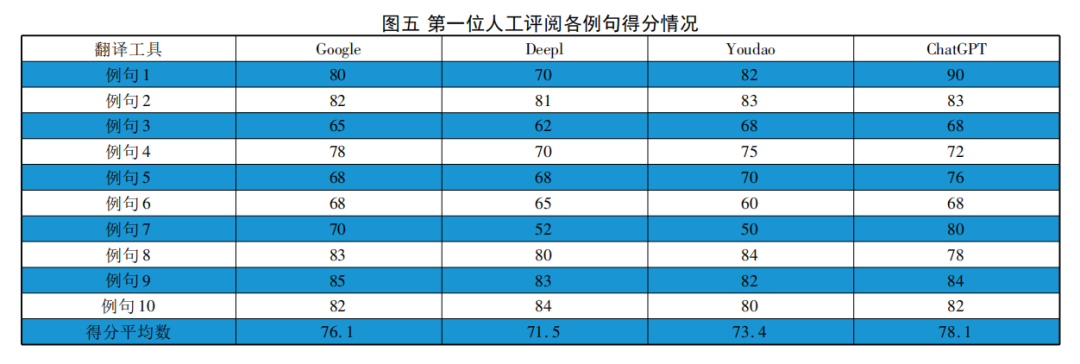
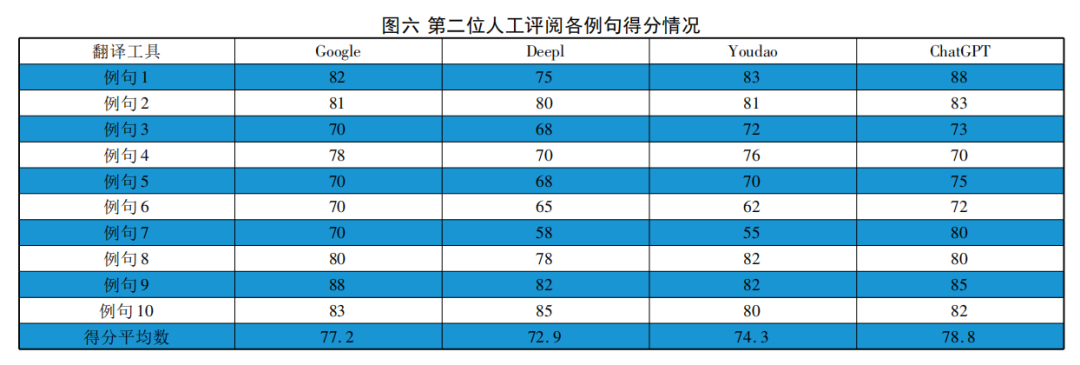
从第一位人工评阅的数据来看,ChatGPT译文的平均数为78.1,高于Google翻译(76.1)、有道翻译(73.4)和DeepL翻译(71.5)。从第二位人工评阅的数据来看,ChatGPT译文的平均数为78.8,同样高于Google翻译(77.2)、有道翻译(74.3)和DeepL翻译(72.9)。尽管两组数据存在细微差异,但四种翻译工具的有效性排名保持一致。这些数据表明,在未知译文来源的情况下,两位人工评审均认为,ChatGPT在该翻译任务中的表现相对最佳,其次是Google翻译和有道翻译,而DeepL翻译则表现最差。
ChatGPT为何在人工评阅中的分数位居第一?我们对四种翻译工具的译文进行了进一步分析,发现两位评审一致认为,ChatGPT在隐转喻识别、句子结构、文化敏感度、词语准确性四个方面的表现均优于其他翻译工具。
(1)隐转喻识别。例二中,“啃硬骨头”这一表达是一个隐喻,指“难以解决的困难”。Google翻译、有道翻译和DeepL翻译在处理这一表达时,都没有识别它的隐喻意义,直接采用了字面直译的方法,将其翻译成了“gnaw hard bones” “crack hard bones”和“gnawed on hard bones”。这三种翻译都未能准确把握该表达的含义。相比之下,ChatGPT识别了“啃硬骨头”的隐喻用法,将其翻译成了“tackle tough issues”,更加准确地传达了中文成语的意思。例七中,“江山”二字被用来转喻“国家”。有道翻译、DeepL翻译均未成功识别该转喻,同样直接采用了直译的方法,将其译为“The river”“The rivers and mountains”。
(2)句子结构。在例一中,ChatGPT将整个句子译为:“Party comrades must never forget their initial commitment and always keep their mission in mind; they must be humble and cautious,work hard and struggle; they must be brave in fighting and skilled at struggling.” ChatGPT巧妙地分割了原句,用三个分句准确全面地表达了源语文本的意思并添加了主语“They”来指代“党员同志们”。三个分句的句式结构相似,具有排比的效果,朗朗上口,使读者易于接受和理解。
(3)文化敏感度。在例五中,“天下为公”这一成语出自《礼记·礼运篇》,表达了一个理想的大同社会观念,带有浓厚的中国传统文化意蕴。有道翻译和DeepL翻译仅进行了字面翻译,将其译为“the world for the public”和“the world is for the public”,没有理解“公”字的文化内涵,只是简单地完成了字对字翻译。而Google翻译的译文“the world as the public”更是反映出其对中国传统文化的敏感度不高,甚至在多音字的识别和判断上也出现了问题。相比而言,ChatGPT将其翻译成“the world is forall”,较好地传达了“天下”的资源和权力应该属于全体人民这个内涵。
(4)词语准确性。对例七中“打江山”这个动词词组,有道翻译和DeepL翻译直接采用字面翻译,将其译为“fight and defend the country”和“fight the rivers and mountains”,没有准确表达汉语“打江山”的实际含义。“打”在这里不是与“江山”这一实体概念争斗的意思,而应理解成为国家奋斗。相比之下,ChatGPT将其翻译成“fighting for the country”更好地传达了源语文本的含义。而Google翻译的表现则更为差劲,将“打”翻译成“Conquer”,完全曲解了“打”在这个词组中的意思,也严重歪曲了中国共产党为了中华民族崛起、为了中国人民站起来所做的付出与牺牲。
05
挑战与风险
01 意识形态风险
在翻译应用中,像ChatGPT这样的自然语言处理模型可能带来意识形态风险。这些模型基于大量文本数据进行训练,可能含有原作者的观点和偏见。同时,人为审查或修改翻译内容也可能引入偏见,具体取决于审查者的观点和价值取向。另一个潜在问题是,这些模型的预训练语料库主要来自西方社会和文化,容易引入西方中心主义的偏见。张华平等(2023)对ChatGPT的中文性能和使用风险进行了测评,其中就提到了认知战风险。我们仍然不能保证它能脱离训练语料中的偏见,也不能保证不引入标注人员的价值观。我们可以发现,ChatGPT把例八中的“台湾问题”译成了“Taiwan issue”。徐梅江(2003)认为,“台湾问题”应译为“the question of Taiwan”或“the Taiwan question”,绝对不可译为“the issue of Taiwan”或“the Taiwan issue”。因为“issue”最突出的含义是“存在争议和待解决的问题”,而台湾问题属于中国内政,坚持祖国完整统一是毋庸置疑的原则,不容任何国家和外部势力的干涉。
值得注意的是,国内网易公司开发的有道翻译和德国公司开发的DeepL将“台湾问题”译为“Tai-wan question”。因此,在使用ChatGPT或类似模型进行翻译时,用户和开发者都需要保持警惕。我们需要深入了解模型的潜在偏见,并采取措施来减少这些风险,比如审查翻译结果、使用多个翻译工具进行对比,或者寻求专业译者帮助,以确保翻译的准确性和中立性。此外,开发者也应当致力于改进这些模型,以减少偏见并提高翻译质量。总之,在自然语言处理和机器翻译领域,需要认真管理和处理意识形态风险,以确保翻译结果尽可能准确、中立。
02 文化差异挑战
ChatGPT在翻译“中国特色话语”时,面临着文化元素和传统价值观等方面的挑战,虽然ChatGPT对于部分例子的文化负载词处理得当,但整体来看,其对文化负载词的适应性尚不充分。例如,ChatGPT将第三例中的“红色资源”翻译为“Red resources”。事实上,红色资源孕育于中国革命、建设和改革历史发展过程中,又在社会主义现代化建设和改革开放的实践中不断创造出新时代精神。ChatGPT局限于字面翻译,仅将其视为颜色和资源的组合,未能捕捉其中包含的革命历史和社会主义精神的重要内涵。这导致翻译结果缺乏深度和文化内涵,限制了更丰富的理解和跨文化沟通的机会。
再如,例五中的“天人合一”是中国古代哲学中关于自然和人之间关系的一种观点,天人合一说力求探索天与人的相通之处,以求彼此的和谐统一,“天”在这里指的是“自然”,“合一”指的是“人与自然和谐相处”,最好译为“promoting harmony between humanity and nature”。ChatGPT将其译为“the unity of heaven and man”,将“天”译为“heaven”,将“合一”译为“unity”。可以看出,ChatGPT的基础逻辑仍然受限于西方叙事框架。
这些问题表明,在处理“中国特色话语”时,ChatGPT尚不能全面理解其中的文化背景和内涵,而这对于准确翻译和传达信息至关重要,ChatGPT需要建立更深入的文化理解和文本分析能力,以提升翻译的质量和准确性。
03 准确性挑战
ChatGPT在翻译过程中的准确性仍有待提升,虽然其翻译准确性较之其他翻译工具略有优势,在部分例句翻译中的表现也可圈可点,但仍然会出现翻译不准确、错误识别隐转喻或词汇选择不当等问题。例如,例六中的“不怕鬼”。魏在江(2019)认为,用事物代性质这种转喻特性在成语中极为普遍,尤其是在由名词组合而成的成语中。笔者认为,事物代性质这一概念转喻不仅在成语中极为普遍,在单个字词中也经常出现。“鬼”,其古字形像为人身大头的怪物,在中文语境中“鬼”也多指骇人的异物,其特征非常鲜明。在这里用“鬼”转指“恐吓”“威胁”,属于事物代性质的概念转喻用法。ChatGPT无法识别这一转喻,直接译出其本体,将其译为“not fear ghosts”。
再如例四中的“打虎”。“打虎”即“打老虎”,指的是严肃惩处位高权重的腐败分子,主要侧重点为惩罚,所以“打”字,是“打掉”“打败”的意思,而ChatGPT将其译为“Fighting”。“Fight”强调的是过程,且隐含着对抗双方势均力敌的意思。可以看出,ChatGPT在词汇理解的精准度上同样存在问题。
06
结语
对四种主要的机器翻译工具进行综合评估之后,本研究发现,从定量研究角度看,ChatGPT在“二十大报告”文本的汉英翻译任务中表现较为优异。从人工评阅角度来看,ChatGPT对部分内容的表现也优于市面上主流的翻译工具。这表明ChatGPT已经在现有的机器翻译工具中具备一定的竞争力。
在译后编辑的应用场景中,ChatGPT有潜力作为一个高效的预处理工具,提供更高质量的初始译文,提升整体翻译效率和质量。然而,该模型在处理涉及意识形态、复杂结构、文化负载词、隐转喻识别等内容以及在翻译准确性方面的限制性仍然明显,离“良好”的翻译标准还相差很远。
总体而言,ChatGPT还未对传统人工翻译或现行机器翻译工具造成根本性变革。特别在处理政治敏感度高的文本时,人工翻译的角色依然关键。随着ChatGPT模型的不断优化,它在机器翻译领域将具有广泛的应用潜力,但在许多专业和关键的翻译任务中,人工译者和机器翻译相结合的方法依然是最佳选择。
在人工智能时代,尤其是在面对ChatGPT等自然语言处理技术时,翻译应加强以下方面的建设与发展:(1)技术整合,整合现代技术以提高翻译效率和精确度;(2)伦理研究,专注研究翻译伦理问题,特别是与机器翻译和自动化工具相关的伦理挑战,以确保合法和道德的翻译实践;(3)跨文化研究,深入研究文化差异和语言多样性,以更好地应对多语言和多文化环境中的翻译需求;(4)人机协作,研究如何实现机器与人的协同工作,以提高翻译质量,例如机器翻译与人工编辑的融合方式探究;(5)教育创新,黄友义(2010)认为翻译市场需要更多专业性的翻译技术人才,以满足不断增长的需求,我们需更新翻译教育和培训,使学生和专业人士能够熟练掌握现代翻译技术;(6)技术研究,积极研究现代翻译技术的潜力和限制,推动技术的改进;(7)翻译理论,“计算机科学、人工智能、脑科学、认知神经科学的发展进一步推动了语言学视角的翻译理论的发展,机器翻译已不再是神话,但要使机器人像人一样顺利翻译,还有很长的一段路要走”(文旭,肖开容,2019:2),我们要继续加强认知翻译学理论与实践的探索,揭示“人类”翻译的认知过程,从而反哺并指导机器翻译的发展;(8)塑造中国话语体系,傅敬民(2023)提出,新时代的中国翻译教育,应以丰厚的中国传统翻译文化精髓为底蕴,我们要加强翻译教育中的中国元素,通过翻译强化中国在国际话语体系中的地位,帮助传播中国文化和中国声音。
由于篇幅所限,参考文献及注释已省略。
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除
