技术科普 | 适用于语言学习的大语言模型汇总
这些模型可以从多个维度帮助语言学习者: 1.提供即时反馈:大语言模型可以对学习者的句子进行语法和语义分析,提供即时纠正和建议,帮助学习者提高语言的准确性。 2.对话练习:学习者可以与模型进行对话练习,模拟真实交流环境,增强口语. 3.词汇扩展:模型可以根据学习者的需求,提供丰富的词汇和表达方式,帮助学习者扩展词汇量。 4.阅读理解:大语言模型可以生成多种难度级别的阅读材料,并根据学习者的理解水平提出问题和解释难点。 5.写作辅助:学习者可以利用大语言模型进行写作练习,模型可以帮助润色文章,纠正语法错误,提供更地道的表达方式。
以下是一些在语言学习领域表现突出的大语言模型汇总。
1. GPT-4
GPT-4(Generative Pre-trained Transformer 4)是OpenAI开发的一种大型语言模型。它基于Transformer架构,通过在大规模文本数据上进行预训练,能够生成高质量的自然语言文本,完成多种语言任务,如翻译、摘要、对话和文本生成。

GPT4对许多公司都开放了接口,导致代理众多,有的收费极其不合理。有条件的话推荐去OpenAI官网使用,如若不方便,也可以通过微软公司旗下的Copilot使用。
2. Google BERT
BERT(Bidirectional Encoder Representations from Transformers)是Google开发的一种预训练语言模型。它采用双向Transformer架构,通过在大规模语料库上进行无监督预训练,捕捉上下文中的深层语义关系。
由Google提出的基于变换器的双向编码器表示技术(Bidirectional Encoder Representations from Transformers,BERT)是用于自然语言处理(NLP)的预训练技术。2018年,雅各布·德夫林和同事创建并发布了BERT。2020年的一项文献调查得出结论:“在一年多的时间里,BERT已经成为NLP实验中无处不在的基线”,有关分析和改进此模型的研究出版物超过150篇。
最初的以英语为主的BERT发布时提供两种类型的预训练模型:(1)BERTBASE模型,一个12层,768维,12个自注意头(self attention head),110M参数的神经网络结构;(2)BERTLARGE模型,一个24层,1024维,16个自注意头,340M参数的神经网络结构。两者的训练语料都是BooksCorpus以及英语维基百科语料,单词量分别是8亿以及25亿。
Google在github上开源了许多训练好的BERT模型,学习者经过简单学习就可以使用。
这里附上两篇教程。
https://www.cnblogs.com/zackstang/p/15387549.html
https://blog.csdn.net/qq_27496129/article/details/137501648
3. Claude 3.5
Claude 3.5是由Anthropic开发的一款人工智能对话模型,是Claude系列的最新版本。以法国启蒙思想家克洛德·阿德里安·赫尔维修命名,Claude 3.5旨在提供更为自然和有效的交互体验。相比前代版本,Claude 3.5在理解上下文、生成更连贯的回答以及处理复杂问题方面有了显著的提升。它在多个领域具备广泛的应用潜力,包括客户服务、内容创作、教育支持和编程辅助等。作为一个高度先进的对话系统,Claude 3.5展现了在语言理解和生成技术上的前沿能力。
4.Gemini1.5
Gemini(前称:Bard)是由Google开发的生成式人工智能聊天机器人。它基于同名的Gemini系列大型语言模型。是应对OpenAI公司开发的ChatGPT的崛起而开发的。2023年3月在部分国家和地区推出,2023年5月扩展到更多国家。2024年2月8日更名为Gemini。
Gemini1.5的架构改进使其能够对大型信息集执行复杂的分析。无论是深入研究阿波罗11号任务的复杂细节或者解析无声电影,Gemini1.5均展示了无与伦比的解决问题的能力。
Gemini1.5Pro在Google先进的TPUv1.5上开发,已在多种数据集上进行了训练,涵盖各个领域,包括多模式和多语言内容。这种广泛的训练基础与基于类人数据的微调相结合,确保Gemini1.5Pro的输出更贴近人类。
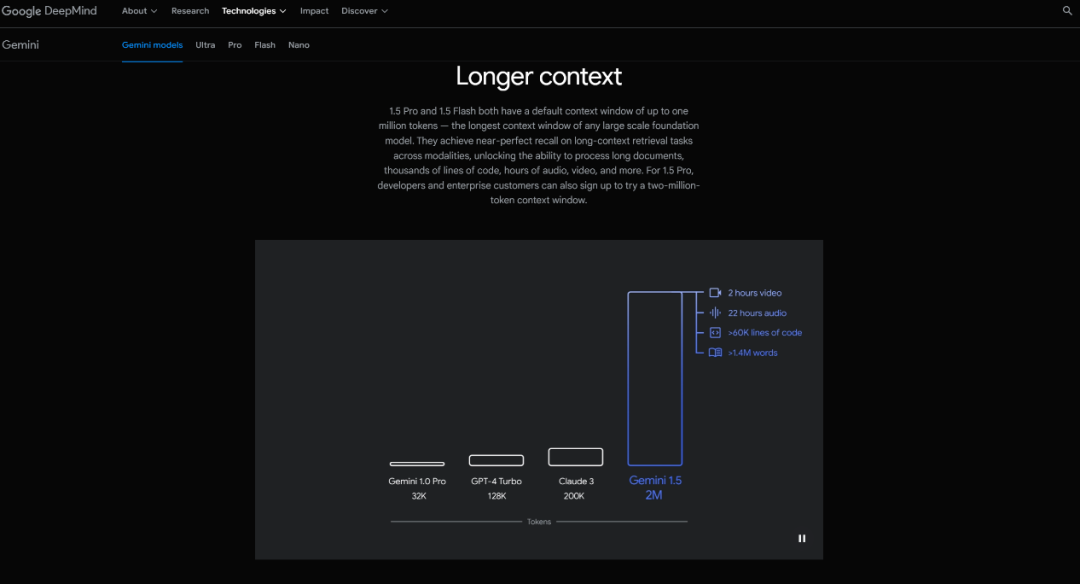
(目前Gemini在长文本的处理方面遥遥领先。)
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
