技术科普 | 盘点2024年8款最佳自然语言处理工具
自然语言处理(NLP)工具能处理和分析以标准会话格式编写的文本或语音。因此,NLP技术的优势在于,用户无需输入代码或其他复杂的指令,就能与人工智能系统进行交互。
NLP工具会充分利用机器学习算法、语言规则和统计技术来实现这一点。NLP理解人类语言的能力使得人工智能以指数级的速度迅速发展。这些工具为有效利用它们的公司提供了显著的竞争优势。
本文从功能、优缺点和定价出发,为不同用户、企业和机构分析了8款最佳NLP工具。相信看完我们的介绍后,大家一定能找到最适合自己业务的NLP软件。
1. Gensim:最适合预算有限的项目

官方网站:https://pypi.org/project/gensim/
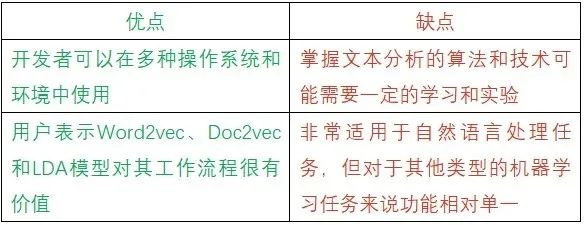
Gensim是一款专注于自然语言处理的开源Python库,可进行文档索引、相似性检索和无监督语义建模。它常用于分析纯文本(即原始的非结构化数字文本),提取文档的语义结构。该方案提供了实现各种机器学习模型的算法和工具,如潜在语义分析(LSA)、潜在狄利克雷分布(LDA)和word2vec模型。
Gensim还提供预训练的词嵌入模型,用于语义相似性、文本分类和聚类等任务。它运用增量式在线学习算法处理大量文本数据,无需将所有文本数据加载到内存训练,因此适用于分析大规模的网络文本数据集。
2. spaCy:最适合需要处理复杂数据的NLP任务

官方网站:https://spacy.io/
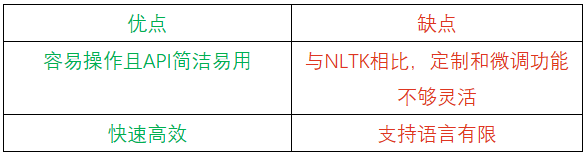
spaCy拥有快速高效的文本处理功能和简洁易用的API,因此成为大规模自然语言处理任务的首选。它的预训练模型可以快速执行各种自然语言处理任务,如分词、词性标注和依存句法分析。
SpaCy支持超过75种语言,并为25种语言提供84种预训练流水线(pipeline)。它利用多任务学习与基于变换器(Transformer)的预训练模型(如BERT),为处理NLP任务的用户提供最先进的工具。
3. IBM Watson:最适合处理高级文本分析任务

官方网站:https://www.ibm.com/watson
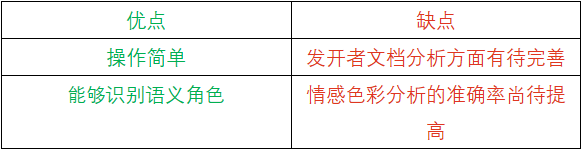
IBM Watson Natural Language Understanding(以下简称IBM Watson NLU)是托管在云平台的自然语言处理服务,能利用先进的人工智能和自然语言处理技术来分析和理解文本数据。它可以从非结构化文本中提取有意义的信息和元数据,如实体、关键字、情感、情绪和类别。IBM Watson NLU可用于各种应用程序,如社交媒体数据监控、客户反馈分析和内容分类。
4. Natural Language Toolkit:最适合教育工作者和研究人员使用

官方网站:https://www.nltk.org/
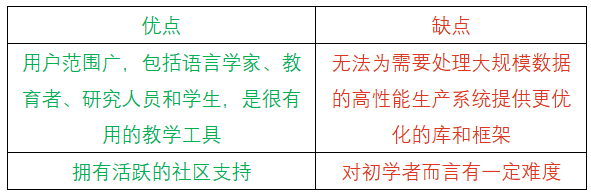
NLTK (全称为Natural Language Toolkit)是专为NLP研究和开发而设计的开源Python库,可用于分词、词性标注和命名实体识别等功能模块。此外,NLTK还提供50多个语料库的访问权限。
NLTK广泛运用于科研、教育和NLP应用构建等学术和工业领域,拥有庞大的用户群体。它提供多种文本数据处理和分析功能,适用于机器翻译等任务。
5. MonkeyLearn:最容易上手的文本分析工具

官方网站:https://www.medallia.com/platform/text-analytics/?utm_campaign=monkeylearnmigration
MonkeyLearn为企业和个人提供多种基于机器学习技术的文本分析工具。用户可以借此构建、训练和部署自定义文本分析模型,从数据中提取有价值的信息。该平台为常见的文本分析任务(如情感分析、实体识别和关键词提取)提供预训练模型,并根据特定需求构建自定义模型。
用户可以在多个第三方应用程序中接入MonkeyLearn的API,如自动化工具Zapier, Excel和客户服务平台Zendesk,或用户自己的平台。
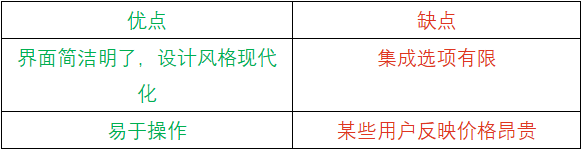
6. TextBlob:最适合NLP项目的初始原型设计

官方网站:https://textblob.readthedocs.io/en/dev/
TextBlob是基于NLTK和Pattern的Python库,应用于常见NLP任务,如词性标注、名词短语提取、情感分析、文本分类、机器翻译等。
虽然这款工具非常适合NLP项目的原型设计,但它继承了NLTK性能较低的缺点,可能不适合企业用于大规模生产。另一方面,易于操作是TextBlob的主要优势——越来越多的初学者正启动AI新项目,因此TextBlob的用户群体可能会增加。
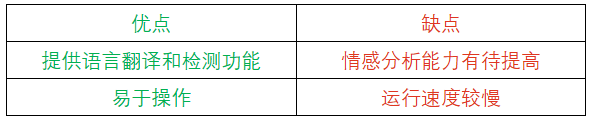
7. Stanford Core NLP:最适合用于信息抽取

官方网站:https://stanfordnlp.github.io/CoreNLP/
Stanford Core NLP基于Java编写,可以分析各种编程语言的文本,这意味着它适用于许多开发人员。Stanford Core NLP提供了一系列自然语言分析工具,以获取文本信息,如词性标注、命名实体识别、情感和文本分析、句法分析、依存句法分析和短语分析。其可扩展性强、速度快,适于处理复杂任务。
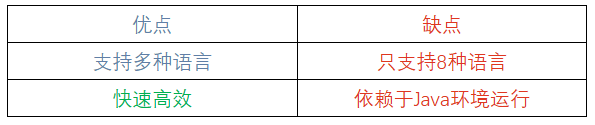
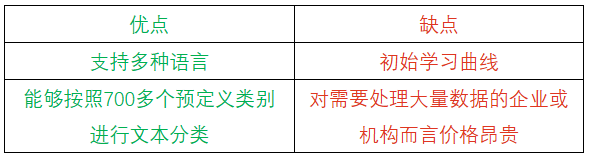
8. Google Cloud Natural Language API:最适合从文本数据中挖掘深层见解

官方网站:https://cloud.google.com/natural-language
Google Cloud Natural Language API是谷歌提供的、基于云的自然语言处理API接口,可帮助开发人员使用机器学习算法从非结构化文本中提取信息。该API接口可用于文本的情感分析、实体识别和语法分析,以及文本归类。
它允许用户使用谷歌的预训练模型AutoML Natural Language来构建自定义机器学习模型,还可利用谷歌的高级问答和语言理解技术来帮助完成自然语言处理任务。
|
编程语言和接口类型 |
是否开源 |
许可证 |
价格 |
|
|
Gensim |
Python |
是 |
LGPL |
免费 |
|
spaCy |
Python |
是 |
MIT |
免费 |
|
IBM Watson |
多种类型 |
否 |
Proprietary |
每个项目起价 0.003 美元 |
|
Natural Language Toolkit |
Python |
是 |
Apache 2.0 |
免费 |
|
MonkeyLearn |
API接口 |
否 |
Proprietary |
299美元/月 |
|
TextBlob |
Python |
是 |
MIT |
免费 |
|
Stanford Core NLP |
Java |
是 |
GPL |
免费 |
|
Google Cloud Natural Language API |
多种类型 |
否 |
Proprietary |
按具体任务量定价 |
在选择自然语言处理工具时,要考虑特定任务需求、数据复杂程度、准确度要求和性能,以及预算和技术优势。我们需要的NLP解决方案应既能解决当前的问题,又能适应技术发展和满足业务需求增长。
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
