机器翻译译后编辑 | A short guide to post-editing 书籍推介 1
A short guide to post-editing
书籍推介

中文译名:译后编辑指南
作者:Jean Nitzke, Silvia Hansen-Schirra
ISBN:978-3-96110-333-1
DOI:10.5281/zenodo.564689
出版社:Language Science Press
网址:https://langsci-press.org/catalog/book/319
译后编辑(Post-editing)已经成为专业译者的既定任务。原始的机器翻译结果可以帮助译后编辑者加快翻译过程,让客户享有更多利润和较低成本。然而,专业的译后编辑者需要掌握机器翻译和译后编辑的基本知识,来评估译后编辑任务并作出正确的决策。

01
什么是译后编辑?
译后编辑(PE)“是由人工译者根据特定的指导方针和质量标准对原始的机器翻译结果进行校正”(奥布莱恩, 2011: 197-198)。
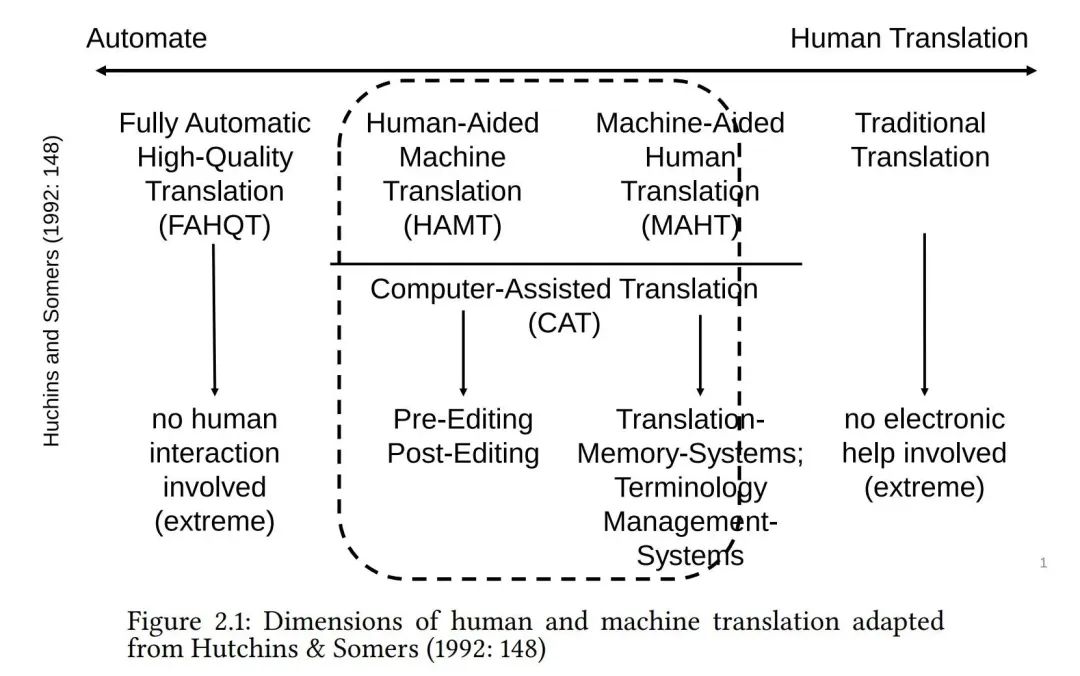
02
译后编辑为翻译研究带来新视角
从研究的角度来看,译后编辑“是人工译者和机器相遇的领域——也是机器翻译和翻译科学这两个学科相遇的领域”(库洛等, 2014: 35)。因此,译后编辑的跨学科研究也很有趣。
首先,我们想说明译后编辑基础理论研究的一些初步途径。由于认知和语用层面的结合,关联理论方法似乎是适合用于描述译后编辑现象的理论。译后编辑者是经过训练的专业人员,能够在目标语境中编辑机器翻译输出来弥合语言之间的交际鸿沟。这项任务是以源文本、预期接受者、目标文化和译后编辑纲要相关的充分决策为基础。
在认知层面,关联理论认为应考虑在有效且成功的交际下,用最少的努力编辑机器翻译结果。阿尔维斯等人(2016)从关联理论层面对译后编辑进行了讨论。
然而,这就意味着读者需要投入更多的认知努力,因为目标文本在语言和/或风格上并不完美。卡尔和舍费尔(2019)将关联理论与噪声信道模型相结合,从理论上探讨译后编辑。他们提出了一个“模型,其中[关联理论]通过增加关联原则建立的刺激、语境和诠释之间的因果关系的约束条件来补充‘噪声译者信道’。”(卡尔、舍费尔, 2019: 60)
03
机器翻译基本方法

不同的方法将翻译过程自动化。在此,我们将讨论基于规则的、统计和神经机器翻译的优缺点,以及他们在译后编辑工作流中的可用性。
以上是本书一至三章的主要内容,请继续关注该系列后续连载~
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
翻译技术教育与研究——机器翻译译后编辑专题组致力于普及机器翻译译后编辑(MTPE)相关知识,追踪国内外机器翻译译后编辑教学与研究动态!
