
语料库技术 | 特殊符号检索BCC语料库
北京语言大学语料库中心(BLCU Corpus Center,简称BCC)是以汉语为主、兼有英语和法语的在线语料库,是服务语言本体研究和语言应用研究的在线大数据系统。BCC语料库总字数约150 亿字,包括报刊(20亿)、文学(30亿)、微博(30亿)、科技(30亿)、综合(10亿)和古汉语(20亿)等多领域语料,可以全面反映当今社会语言生活的大规模语料库。BCC语料库具有数据量大、领域广和检索便捷等优点。
BCC主要包括三种类型语料: 多语种单语语料库、双语对齐语料库和深加工的树库。语料库检索内核是实现语料库系统的技术基础,采用基于后缀串的全文检索算法,并且支持通配符和离合模式匹配,BCC提供两种服务方式:在线检索和云调用。目前BCC以汉语为主,兼顾其他语种的语料,如英语、西班牙语、法语、德语、土耳其语等。
网址:https://bcc.blcu.edu.cn/
进入BCC汉语语料库官网页面后,使用者会看到如下图所示的的界面,该界面的上方菜单栏从左到右依次是:[词典] 检索功能版块、[汉语]检索功能版块、[登录] 键、[注册] 键、[帮助] 键;界面下方从左到右依次是[新闻]区、[搜索示例] 区、[下载] 区,以便使用者更好了解BCC语料库,更加高效地利用检索式搜索到所需内容。
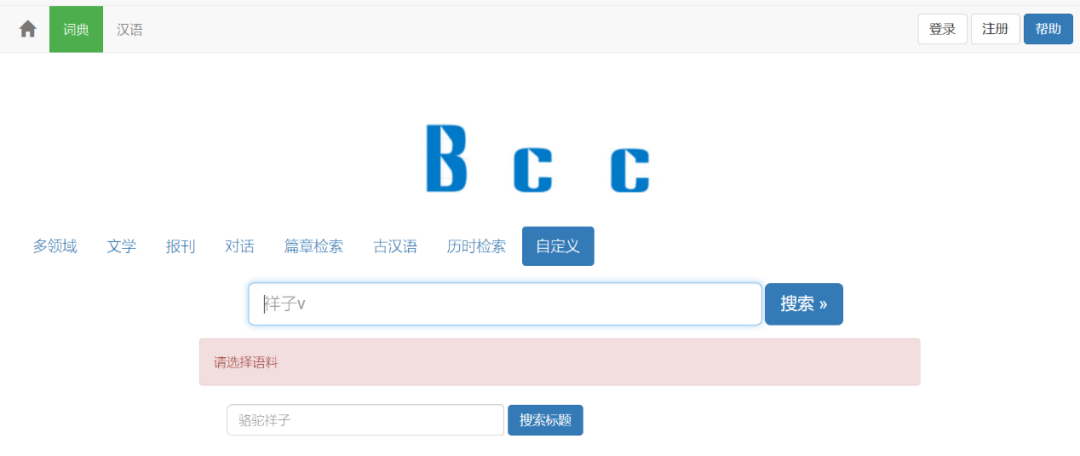
BCC界面
检索式可以是字串、词串、词性的组合而成的查询模式。使用者可以在检索式中使用特殊符号,方便快捷地检索目标内容。
1.1 词性列表
在自然语言处理中,中文词性标记规范是指对中文文本中的每个单词或符号赋予其对应的词性标签,如名词、动词、形容词等。这些标签列表可以帮助计算机更好地理解文本的含义和结构,从而进行更准确的信息提取、文本分类、句法分析等任务。
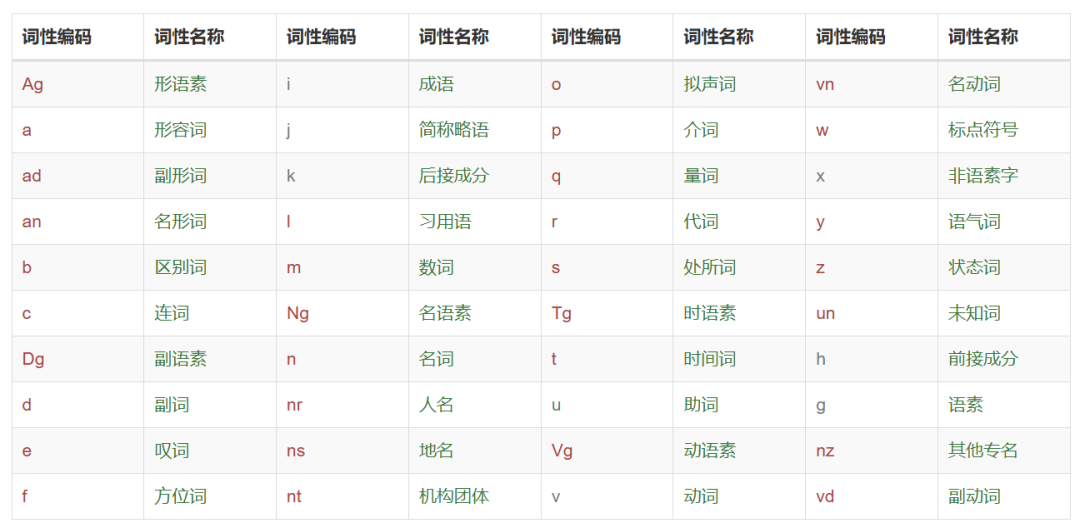
词性列表
1.2 特殊符号(空格)
与通常搜索引擎含义不同,在模式中,有歧义表达时,起到分割作用。在检索式中,输入的英文字符与词性符号一致时,计算机处理为词性,否则按普通英文串处理,如果有表达歧义时,用空格分开。此外在[]中多项内容之间也用空格隔开,另外出现/时候,可以用来表示词边界。
·举例:an与a n
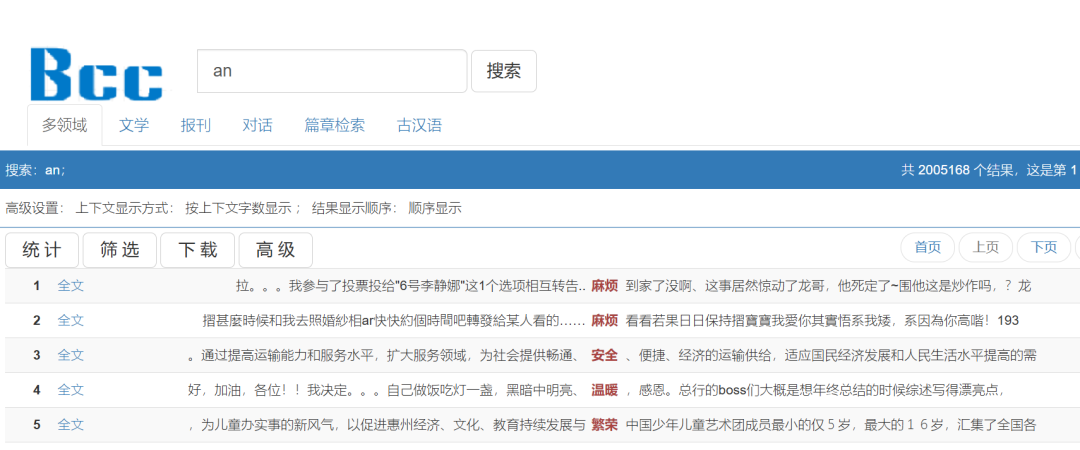
检索an
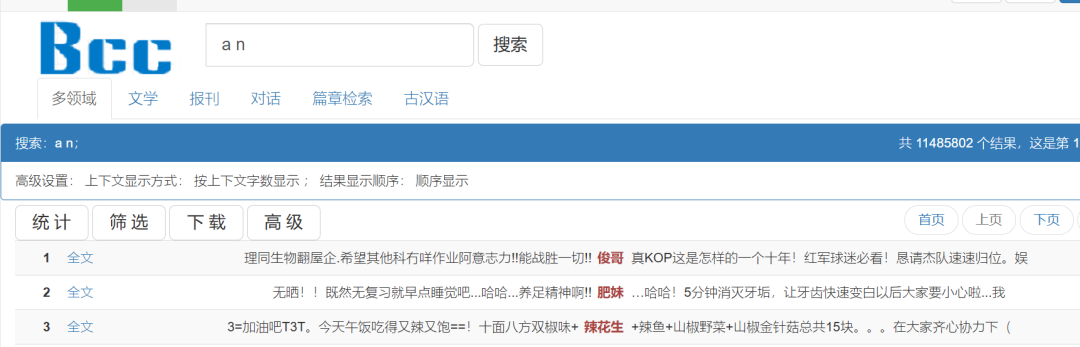
检索a n
按词性理解,检索an为搜索名形词,检索a n则为搜索“形容词+名词”。
1.3 特殊符号*
一般情况下,检索式表示连续的语言片段,如果需要查找离合情况时,需要用特殊符号*,形式为A*B,表示查找A的后面离合出现B的单句。
·举例:洗*澡
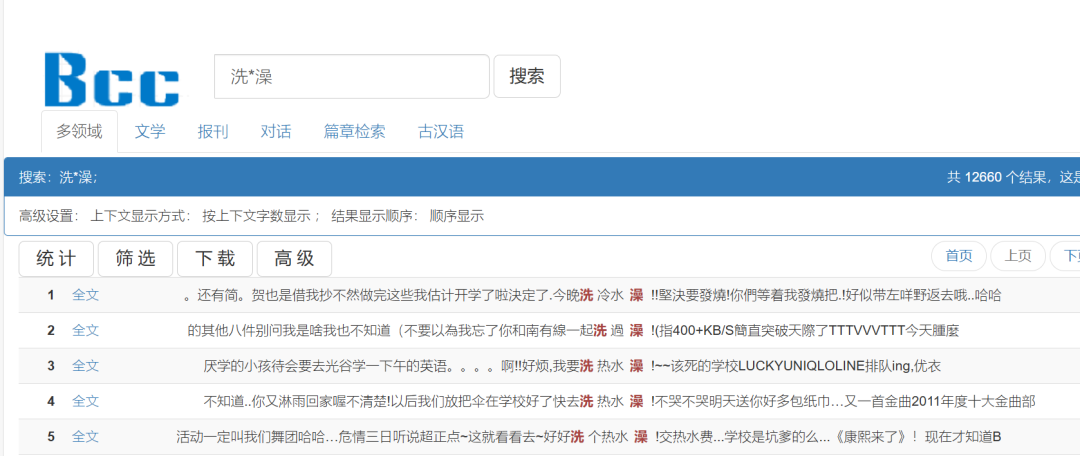
检索洗*澡
表示检索“洗澡”离合出现的情况,可查找到诸如“洗热水澡”、“洗凉水澡”等搭配。
1.4 特殊符号[]
特殊符号[]指进行“或”关系的查询,括号内是多个词串或词性,多个词串或词性之间需用空格隔离。注意,[]内不可只为一个,必须大于等于一个词性。
·举例:v[起来 上来]
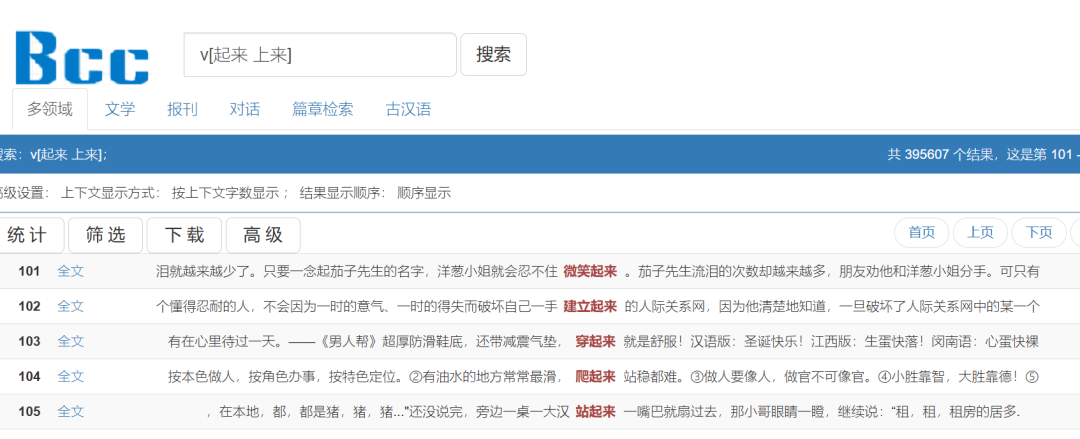
检索v[起来 上来]
表示检索动词后面接着“起来”或者“上来”的短语,查找到“穿起来”、“站起来”等。
1.5 特殊符号.
特殊符号.用于表示汉字或者符号,且一个.表示一个汉字或符号。
·举例:一.不.
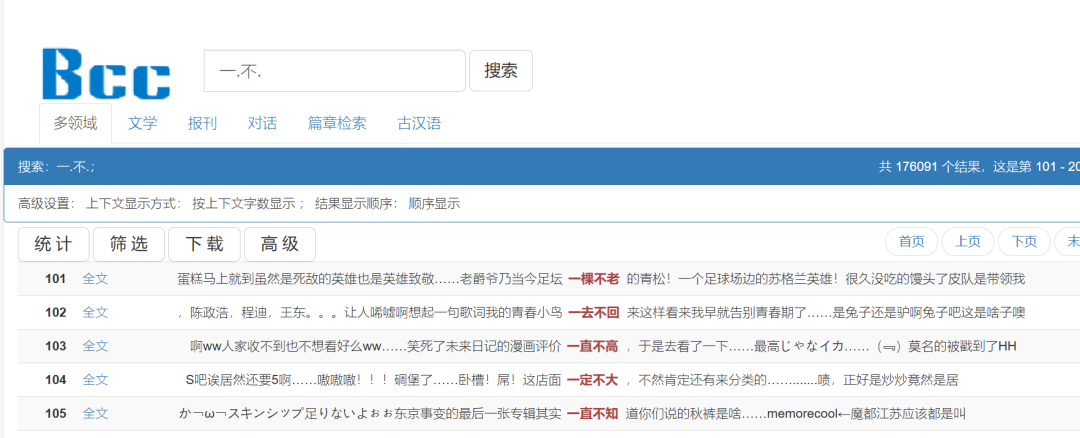
检索一.不.
检索含有“一”、“不”且两者之间包含有一个汉字,“不”后包含一个汉字的所有词组。
1.6 特殊符号/
特殊符号/可对词或者词性约束查询,即限制/号前的连续串是具有某种词性的词。多数时候和特殊符号.一块使用。
·举例:./d
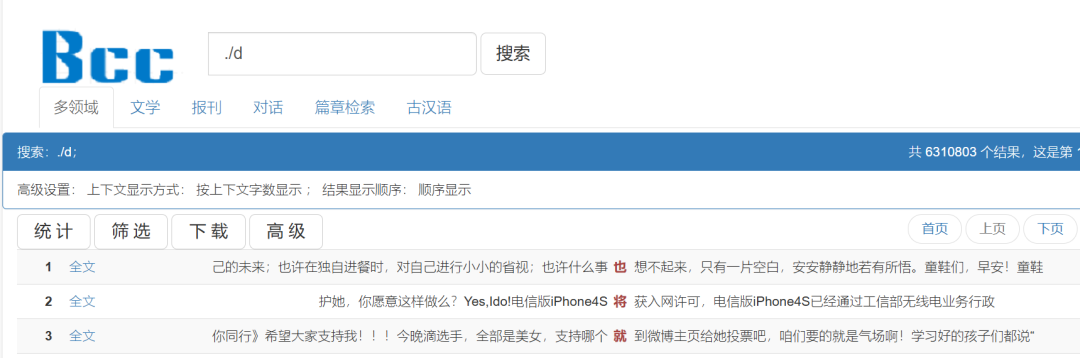
检索./d
表示检索一个表示副词的汉字,例如“也”、“就”等词。
1.7 特殊符号~
特殊符号~表示一个词,可用于检索词组离合情况。
·例如:吃~饭
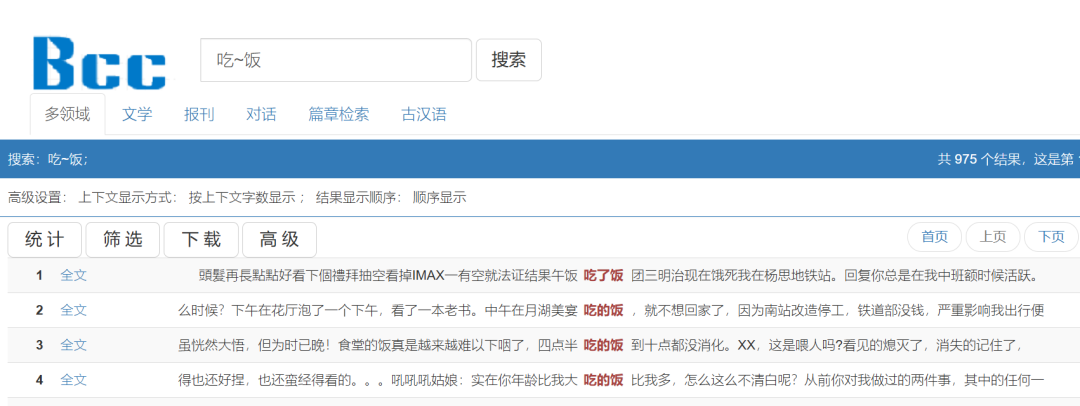
检索吃~饭
表示检索“吃+一个词+饭”。
1.8 特殊符号@
特殊符号@表示一个词性,在搜索反馈中和~没有差异,但在统计功能中将以词性为分类进行统计。
·例如:去@
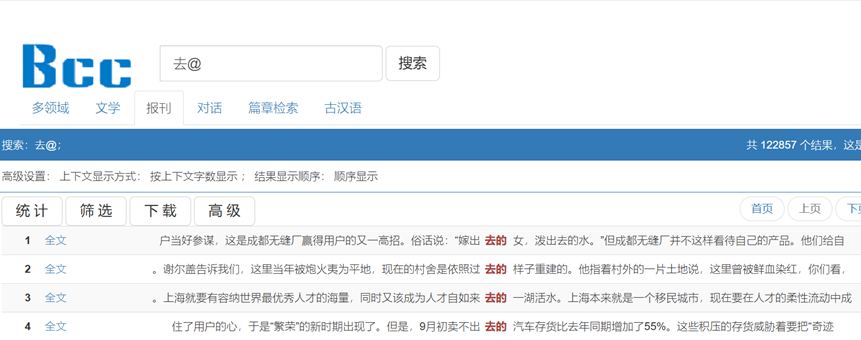
检索去@
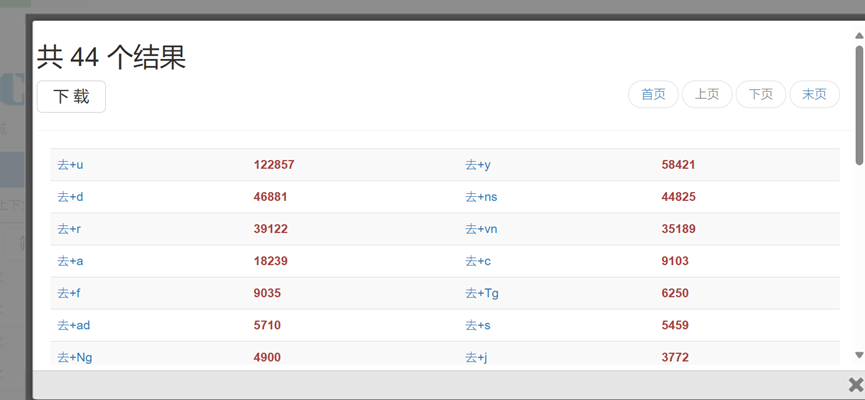
去@统计结果
表示“去”加一系列词,并在统计时系统按照@所代表词的词性进行归并统计,如“去+a”表示“去+形容词”,共有18239例。
1.9 特殊符号w
特殊符号w表示标点符号。
·举例:w跑*步
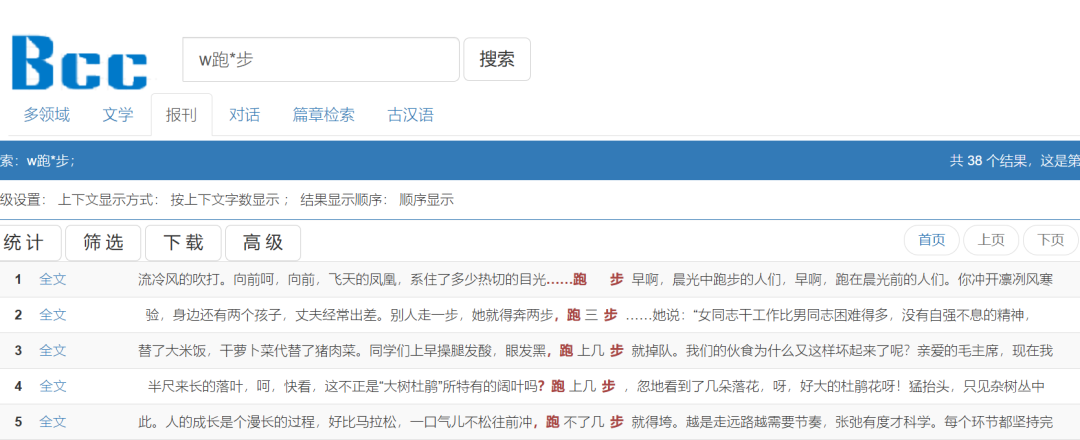
检索w跑*步
表示搜索“跑”前带有标点符号,并和“步”字组成短语的句子片段,如“,跑三步”,对句式可以定界。
利用单个特殊符号组合使用,可以提高搜索效率,准确查找目标词组。
·举例:老./n
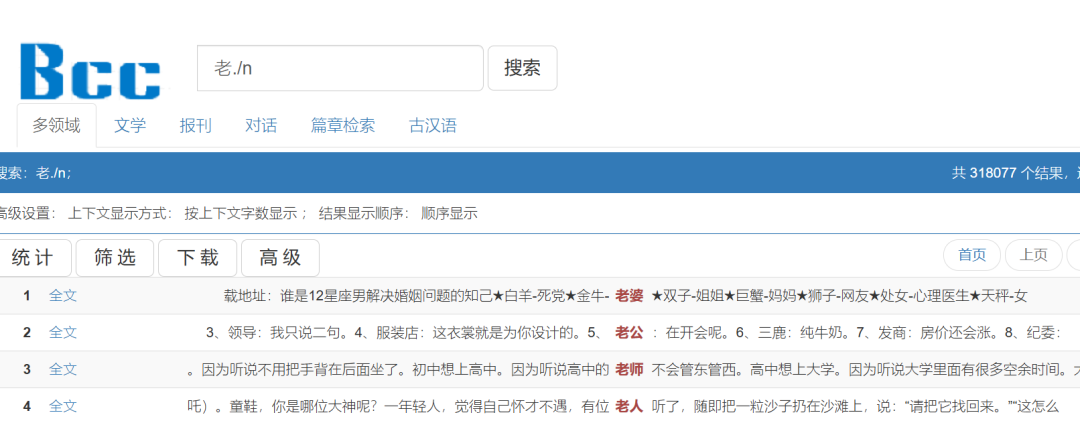
检索老./n
表示搜索以“老”字为开头,后接一个名词汉字的词语构式。
·举例:..性/n [n v a]
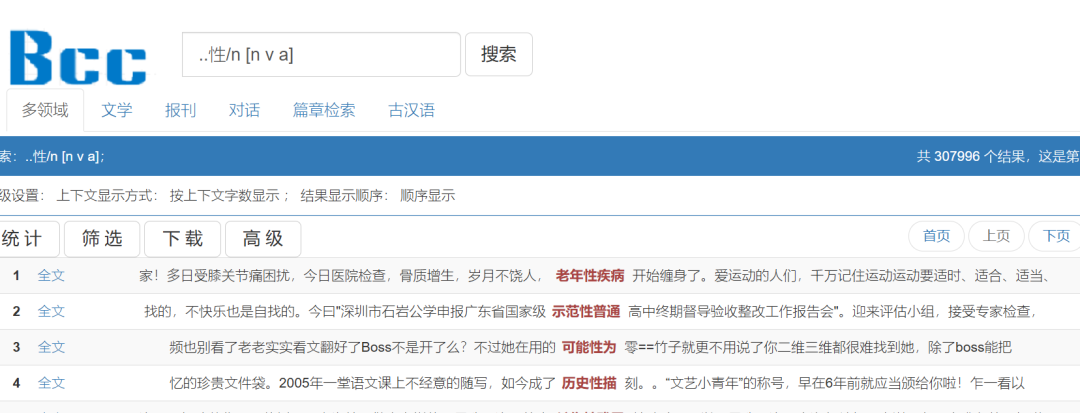
检索..性/n [n v a]
表示检索以“性”为结尾的双音节名词。
高级检索式在基本检索式的基础上增加了条件语句或输出语句。语句之间用“;”隔开,写在基本检索式后的“{ }”中,形如:
Query{condition1;condition2;…}
其中Query表示基本检索式;{ }中的内容为限制语句,其中condition表示对检索内容进行条件限定。
此外,检索式中被限定的部分需要用( )括起来,一个检索式中被限定的成分只能有两处,即只能出现2个( )。根据( )出现的顺序,使用$符号和序号指代该部分内容,在{ }中进行指称。即$1表示第一个( )中出现的内容,$2表示第二个中的内容。
最后,可以通过内容限制([])长度限制(len)、次数限制(count)等操作符,来控制搜索目标特殊范围。
·举例:爱(v)不(v){$1=$2;len($1)=1}
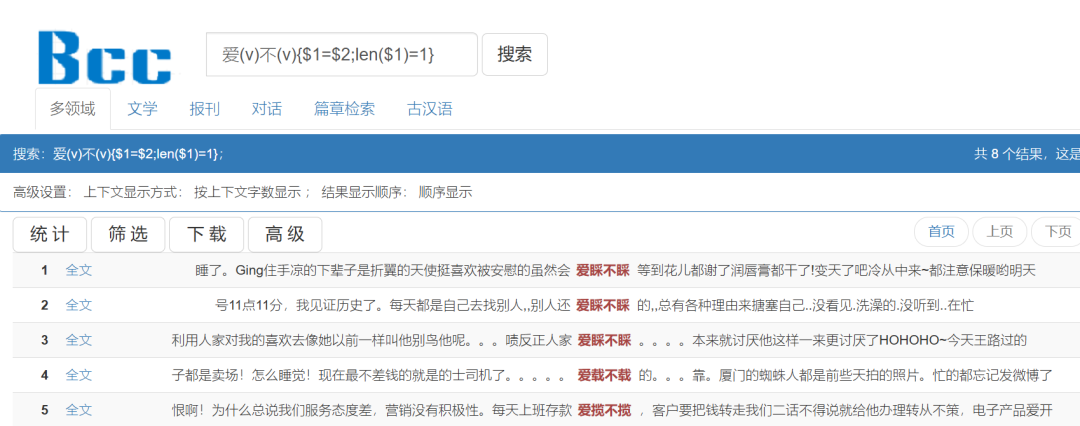
检索爱(v)不(v){$1=$2;len($1)=1}
表示“爱+动词+爱+动词”的结构,按“( )”出现的顺序,两个动词可分别由“$1”“$2”取得,“{ }”中的限定条件表示前后两个动词相同。即以“爱”为第一个字,第二个字为一个动词,再以“不”为第三个字,第四个字动词且和第二个字相同的短语。
·举例:(a)的(n){len($1)=3}
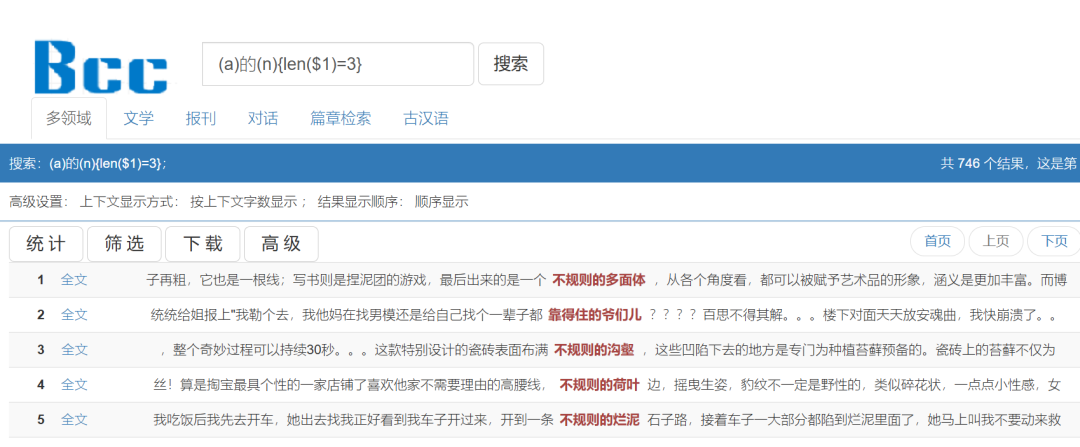
检索(a)的(n){len($1)=3}
表示“形容词+的+名词”的结构,且第一个括号中的形容词限定为三个汉字。
BCC语料库除了有多语种单语语料库、双语对齐语料库可用于验证词汇的搭配组合的典型性,发现合适的搭配词汇外,还在 [下载] 区域还增设有树库资源、法语资源、HSK资源、以及汉语资源等,如下图所示。
下载界面
北语句法结构树库主要基于块依存图、意合图理论,并为其提供大规模、多领域的语言结构数据,而短语结构树是缺省结构、句间结构的基础,因此北语句法结构树库的构建以短语结构标注为基础,分级分层、逐步完成缺省结构、句间结构标注。短语结构树构建具体说来就是:通过区分句内短语、语气成分、连接成分,标注句子基本骨架,初步构建浅层句法分析树库,同时为缺省结构、句间结构标注打下基础。
CCFT数据下载界面
北京语言大学法汉指称链条平行语料库是一个共时标注语料库,由北京语言大学中法语言文化对比交流中心开发,受国家社会科学基金资助(项目批准号19BYY014),由五种体裁的文本构成:文学、政论、新闻、科技文和官方文件,共计约150万字左右。其中不同体裁的文本在整个语料库中所占比重基本相当以保证语料库的平衡性。每种文本都选用了以法语为源语言的文本。
目前,CCFT标注了罗曼罗兰的小说《约翰克里斯多夫–卷一》(傅雷)约11万字,巴尔扎克的小说《欧也妮与葛朗台》(李恒基)约18万字, 卢梭的《论人类不平等起源》(李常山)约20万字, 以及科技文汉法对照教材《现代近距离放射治疗实用手册–第一卷》(Marinello Ginette著、潘基建译)约13万字。主要标注了文本中的代词回指链条(包括法语中的关系代词、主有代词、指示代词等,以及中文的零回指及其它回指代词),其中《欧也妮与葛朗台》还标注了名词回指。

《自然语言结构计算BCC语料库》
本书详细介绍了BCC语料库的内容、建设过程、检索功能、查询语言、编程语言及如何使用自定义BCC语料库的全过程,可谓是BCC语料库的“生平传记”。BCC语料库的开发者之一——荀恩东教授除了在此书中不留余力地指导使用BCC语料库交互式查询语言、脚本式编程语言应用外,还涉及语料库建设的技术,涵盖了语料库的建设过程中的多项新技术,语料库的建设与使用方法的目前认知的全部领域等,旨在以BCC创建过程为例,读者可以借此学习搭建属于自己的语料库。
例如,在本书中的第七章——个性化语料库的构建中,荀恩东教授分别从数据准备、索引构建、语料库使用三个重要板块出发,让不论是学语言还是学技术的读者都能看得懂、用得会,进而有章可循地得出数据信息、数据预处理、硬件基础、预备文件、构建索引、启动服务、网络使用、离线使用的语料库构建工作流,每个环节还搭配有操作代码和推荐使用软件。
随着计算机技术的发展,语料库在语言本体研究、语言教学和自然语言处理研究和应用中发挥着越来越重要的作用。学习BCC语料库,不仅能帮助使用者验证术语的准确性,发现词汇搭配的典型性,有效避免了主观推断,从而显著提高了翻译质量。此外,在母语汉语写作本身,能检查拿不准的句型、检查词汇是否属于“生造”,还可以在我们灵感不足或积累匮乏时为下一步的遣词造句提供提示。最重要的是,学习利用检索式检索BCC语料库,能掌握基本的正则化表达逻辑规律,为带给广大读者一种全新的视野,从计算的视角透视语言。其实,BCC汉语语料库作为丰富且又成功的语言资源库,其应用范围非常广泛,不应局限于为语言学家和翻译学家提供大量的语言实例,用于研究语言的形态、语法、语义和语用,还可以为自然语言处理NLP算法的训练和测试提供数据,特别是在词性标注、命名实体识别、句法分析、情感分析等任务中。BCC语料库可以是个应用技术检索学习语言的工具,但更可以是个借鉴技术创建学习语言的范例。
参考资料
-
BCC汉语语料库官网–帮助栏
-
荀恩东.《自然语言结构计算BCC语料库》[M]. 北京: 人民邮电出版社, 2023:176-192.
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
