译学文献 | 词汇表大小对大语言模型的影响
2024年07月27日 00:00
以下文章来源于大模型多模态论文解读 ,作者hanscalZheng
大型语言模型(LLMs)中词汇量大小对于模型扩展规律的有哪些影响呢,之前的研究往往集中于模型参数数量和训练数据量,而忽略了词汇表大小的角色。论文中研究人员探索了三种评估最优词汇量的方法:基于计算力的IsoFLOPs分析、导数估算及损失函数参数拟合,这三种方法均表明,最优词汇量取决于计算资源,而且大模型应匹配大词汇量。现有的许多LLMs所使用的词汇量过小,例如,Llama2-70B模型的理想词汇量应为216K,远超其实际的32K。通过实验验证,当模型在不同计算预算下采用预测的最优词汇量时,其下游任务的表现普遍优于常用词汇量大小。例如,将词汇量从标准的32K增加到43K,就能在同等的计算量下,模型在ARC-Challenge上的性能从29.1提升至32.0。
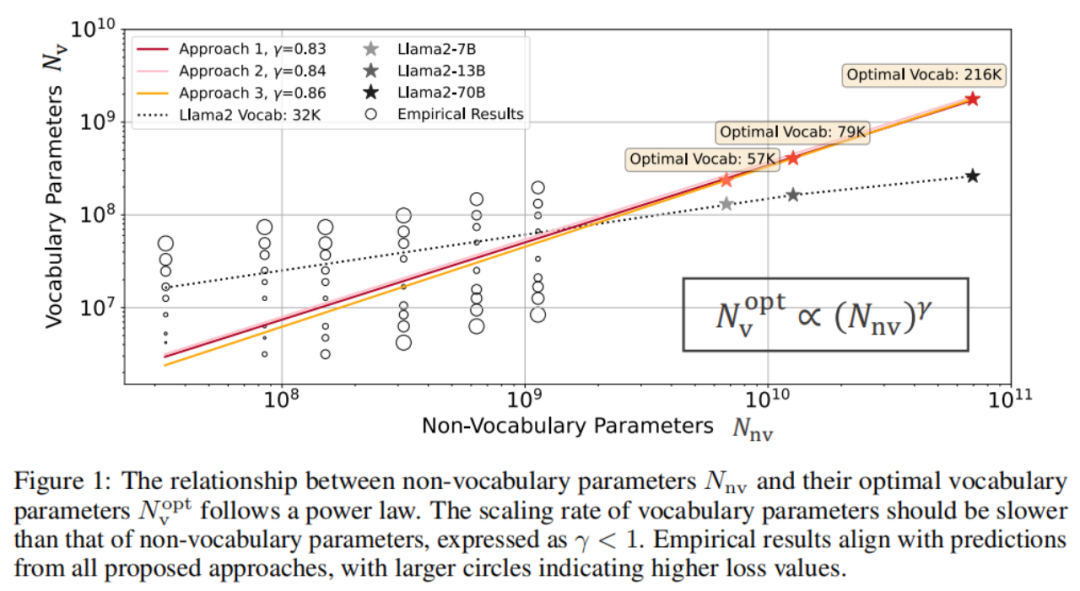
1 三种预测计算最优词汇量的方法
-
通过IsoFLOPs分析估计幂律:
-
(1)定义模型组:研究者定义了六个模型组,其中非词汇参数数量Nnv从3300万到11亿3千万不等。在每个组内,只改变词汇量V,从4000到96000不等,所有模型都在相同的FLOPs预算下进行评估。
-
(2)评估与选择:使用固定的数据集评估模型的归一化损失。从每种FLOPs预算下选取最小损失的点,这些点代表了计算最优的参数分配。
-
(3)假设与拟合:基于先前的研究,假设最优的词汇参数Nv与FLOPsC满足幂律关系,就像非词汇参数和训练数据量一样。通过这种方法,研究者可以直接回答:在特定的计算预算下,非词汇参数、词汇参数和训练数据的最佳分配比例。
2. 基于导数的估计:
-
(1)原理:这种方法利用导数来估计在不同词汇量下模型性能的变化率,从而找到最佳词汇量的转折点。
-
(2)应用:通过计算损失函数关于词汇量变化的导数,研究者可以识别出词汇量增加带来的边际效益递减点,即超出这一点继续增加词汇量对性能提升的贡献不大。
3. 损失函数的参数拟合:
-
(1)功能:该方法直接构建一个参数化的函数,用于预测不同属性如模型参数数量、词汇量和训练数据量对模型损失的影响。
-
(2)操作:通过对损失函数的参数拟合,研究者可以量化词汇量、非词汇参数数量和训练数据量对模型性能的具体贡献,进而推断出最优的词汇量配置。
2 增长策略
在大型语言模型的优化过程中发现,词汇量与非词汇参数间存在幂律关系,这意味着随着模型规模的增大,理想的词汇量也会增加,但其增长率相较于非词汇参数更为缓慢。这种现象背后的理念在于,一旦模型具备了足够丰富的嵌入空间,通过扩大词汇量来进一步增强对文本多样性的理解变得尤为重要;然而,达到一定阈值后,重点应转向非词汇参数的扩展,以深入学习语言的复杂语法和语义结构。这种平衡增长策略确保了模型性能的高效提升,避免了资源的不合理分配。
3 结语
在大型语言模型中,平衡模型参数、词汇量与训练数据的规模对于实现高效能和经济性的模型扩展至关重要。论文重点研究了大型语言模型中词汇量大小对模型扩展规律的影响,发现更大规模的模型应配备更庞大的词汇量以优化性能,并通过实验验证了这一观点,指出当前许多大型语言模型所使用的词汇量实际上偏小。
论文题目:Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
论文链接:https://arxiv.org/abs/2407.13623
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
转载来源:大模型多模态论文解读
转载编辑:张煊
