数字人文 | 数字人文项目介绍与启示(一)Let them speak
1、 BLackLab
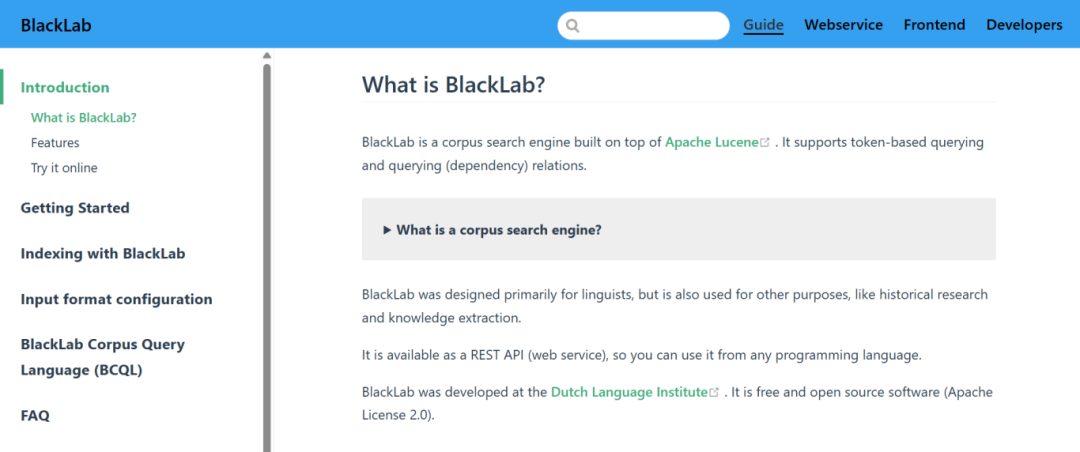
图1 BlackLab官网首页
1. 为带注释的文本编制索引,以便您可以搜索特定的标题或词性。
2. 易于使用、有据可查的 REST API。
3. 快速且可扩展:在几秒钟内找到大型语料库中的复杂模式。
4. 使用内置格式或编写配置文件为数据编制索引。
5. 使用强大的 BlackLab 语料库查询语言搜索复杂模式
6. 在跨度内搜索,例如,在句子末尾找到包含塔的命名实体。
7. 搜索(依赖关系)关系,以在文本中找到特定的(树形)结构。(v4 中的新功能)
8. 捕获相匹配的部分。
9. 根据许多条件对结果集进行分组和排序,例如匹配项之前的文本。
10. 突出显示文档中的命中和命中的关键字在上下文 (KWIC) 视图中的命中。
2、Mongo数据库
图2 MongoDB官网首页
参考资料:
1. Let Them Talk官网https://lts.fortunoff.library.yale.edu/about
2. 中国社会科学院语言研究所http://ling.cass.cn/ziyuan/jikannianjian/2022/202403/t20240306_5737175.html
3. React Radux官网https://react-redux.js.org/
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
