行业动态 | 字节发表CLASI,同声传译智能体系统,媲美人类水平,超越商用产品
2024年08月16日 00:00
以下文章来源于灵度智能 ,作者灵度智能
“Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent”
在翻译领域,大模型超越人类水平已经不是新闻了。然而,大模型在同声传译方面依然是一个未被完全攻克的难题。
近日,字节跳动的研究人员推出了端到端同声传译智能体CLASI,其效果已接近专业人士的同声传译水平。CLASI依托于豆包大模型,同时具备了从外部获取知识的能力,最终形成了足以媲美人类水平的同声传译系统。

项目主页:https://byteresearchcla.github.io/clasi/
论文地址:https://byteresearchcla.github.io/clasi/technical_report.pdf
摘要
本文介绍了一种高质量、类人的同声传译系统CLASI,它采用了一种新颖的数据驱动读写策略来平衡翻译质量和延迟,并利用多模态检索模块来解决领域术语翻译的挑战。该系统支持错误容忍翻译,并通过VIP指标评估翻译质量,实验结果表明CLASI在真实场景中的表现优于其他系统。该系统的演示和人工标注测试集可在网站上获得。
简介
同步语音翻译(SiST)被认为是翻译领域最具挑战性的任务之一。传统的同声翻译方法通常采用级联系统,包括流自动语音识别(ASR)模型、标点符号模型和机器翻译(MT)模型。然而,这种级联系统经常遭受ASR模块的错误传播和延迟。
LLM在机器翻译和语音翻译方面取得巨大成功的激励下,我们建议使用LLM来完成SiST任务。我们确定了三个主要挑战。首先,将LLM整合到SiST中的一个关键挑战是读写策略,其中LLM需要为输入语音提供部分翻译。其次,要达到与人类相当的表现,需要理解和翻译llm无法从训练数据中学习的术语和不常见短语。最后,训练数据的稀缺性继续阻碍SiST任务的性能。
为了应对这些挑战,我们引入了我们的端到端方法,CLASI,一个跨语言代理,通过迭代地执行多个动作来完成同声传译。关于第一个挑战,我们模仿专业的人类口译员,学习他们通过句法边界(暂停、逗号、连词等)和上下文意义将完整句子分割成几个语义“块”的策略。为了使CLASI能够学习这样的策略,我们遵循数据驱动的策略学习过程,并邀请人类口译员注释现实世界的语音,其中包括分段的读写时间。从数据中,CLASI从人类那里学习了SiST的健壮读写策略。
对于第二个挑战,我们包括两个外部模块来增强我们的CLASI代理,一个存储术语和配对翻译的外部知识数据库,以及一个存储语音上下文的内存。我们提出了一种新的多模态检索增强生成(MM-RAG)过程。多模态检索器根据语音输入从外部数据库中提取知识。然后,从记忆中检索到的信息和上下文被附加到我们的LLM代理的提示中,通过上下文学习来增强翻译。
为了解决SiST任务的数据稀缺性,我们采用了三阶段训练方法:预训练、持续训练和微调。首先,我们的LLM和音频编码器是在我们的大型内部数据集上独立预训练的。然后,我们的模型使用数十亿个中等质量的合成语音翻译数据进行持续训练,旨在使语音和文本模式保持一致。我们还增加了多个任务来增强LLM的语境学习能力,以便更好地利用来自检索者和先前翻译的语境信息。最后,我们使用少量人工标注数据对模型进行微调,进一步模仿专业的人工口译员,提高鲁棒性和翻译质量。
CLASI
整体框架
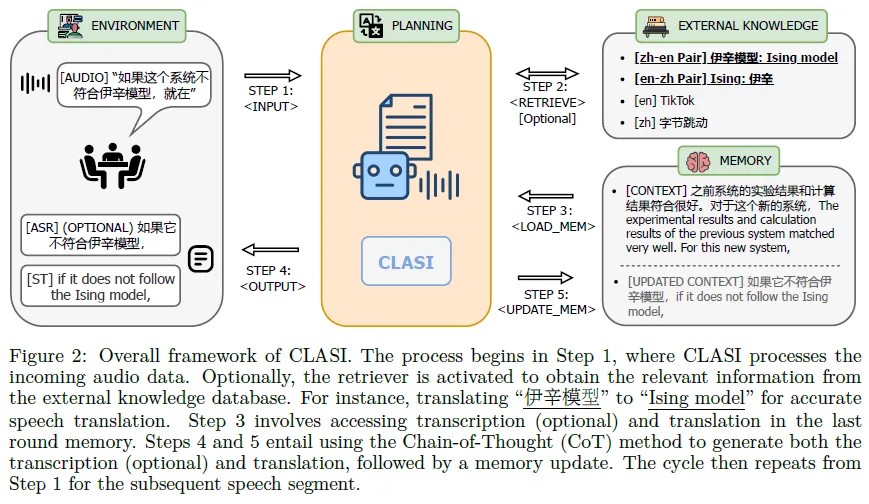
CLASI可以接收语音输入、指令、外部知识和上一轮的记忆作为上下文,通过输入、输出、检索、加载和更新记忆等五个操作来完成任务。CLASI可以存储先前的转录和翻译结果。在每一轮中,它读取语音输入,检索相关信息,加载上一轮的记忆,并生成转录和翻译结果。在需要输出转录时,它可以使用CoT来生成转录。下一轮的语音输入从上一轮的结束时间开始。 架构
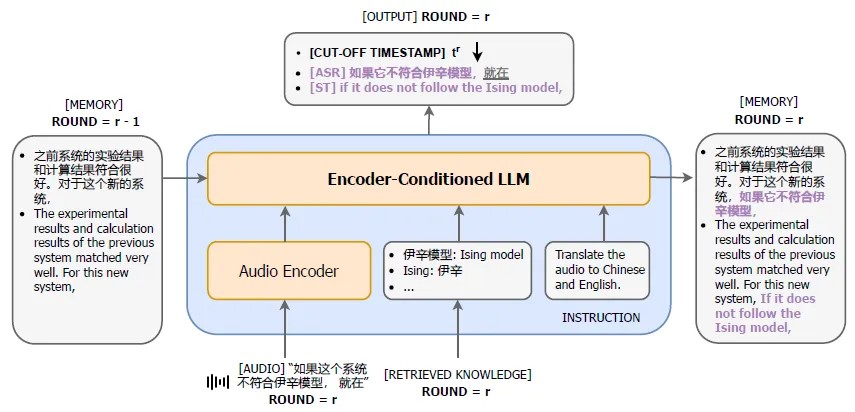
CLASI使用编码器-条件化LLM架构,其中音频编码器将输入语音流转换为一系列连续表示,LLM以语音表示、检索知识、历史翻译和指令作为提示序列来生成翻译结果。多模态检索器框架使用音频和文本编码器独立编码音频流和文本关键字,以增强对齐。
数据驱动读写策略:<输入>,<输出>
CLASI通过等待完整的语义块来模仿它们的策略。给定部分语音,CLASI只生成输入语音的完整块的翻译。该模型使用分段语音数据进行训练来学习这种能力。在数学上,给定源音频x1:M,我们将其翻译分成一系列n个“块”y 1:n,并得到相应的对{(x t j:t j+1, y j} nj=1,其中x t j:t j+1和y j表示音频的第j段和相应的翻译。对于训练,我们的目标是输出所有完整的分段翻译和给定随机部分输入音频x 1:t 通过训练,CLASI学习生成输入语音的截止时间。此外,目标函数使CLASI在开始翻译之前等待适当的时间,因为LLM在“认为”当前语音流不包含完整的语音块时将不输出任何内容。
背景信息:<LOAD_MEM>和<UPDATE_MEM>
记忆存储了前几轮的翻译和转录,用于确定已翻译和未翻译部分,帮助CLASI做出读写决策并输出翻译结果。同时,理解人类语音通常需要上下文,以避免多义性在不同语境下导致不同的翻译结果。CLASI需要能够检索长篇演讲的上下文,根据不同语境做出适当的翻译。在每轮中,将前几轮的翻译传递给LLM作为提示,生成新的翻译后更新存储到记忆中。 多模态检索增强生成:<检索>
本文介绍了一种新的方法,将外部数据库与语音翻译模型相结合,以提高专业术语的准确性。该方法使用多模式检索增强生成过程,从数据库中检索相关术语,并将其与上下文信息结合,以提高翻译的准确性和连贯性。该方法比传统的替换方法更有效,可以根据上下文选择正确的翻译,并利用源语言和目标语言的单语文本进行翻译。
多阶段训练
CLASI的训练过程分为三个阶段:预训练、多任务持续训练和多任务监督微调。首先,LLM和音频编码器分别使用大量的内部语音和文本数据进行预训练。接下来,使用大量的语音-文本配对数据来对齐音频和文本模态,建立跨模态多任务的基本能力。最后,使用少量的人工标注数据对CLASI代理进行微调,以模仿专业人类口译员的翻译行为。这个多阶段的训练过程使得学习效率高,只需要少量的人工标注数据。
预训练
CLASI包括两个独立预训练的模型:LLM和音频编码器。LLM使用解码器-只变压器架构,首先在大量单语和双语文本数据上进行交叉熵损失的预训练,然后在指令跟随数据上进行微调。音频编码器则使用经典的预训练-微调范式,在大量与语音相关的数据上进行预训练。这两个模型的预训练为后续阶段提供了坚实的基础。
多任务持续训练
训练任务包括自动语音识别、语音翻译和文本翻译。为了解决同声传译数据稀缺的问题,作者提出了一种合成数据的方法,包括离线语音翻译数据和基于语义块的流式语音翻译数据。作者还提出了一种VIP评估指标来评估合成数据的质量。 多任务有监督微调
通过在多任务连续训练阶段后对人工注释的流式语音数据进行微调,可以提高模型在SiST任务上的翻译质量,并增强其对语音障碍的鲁棒性。同时,使用专业人员提供的高质量注释数据,可以使模型更好地适应人工解释者的分割方法,并识别和翻译上下文中的专业术语,从而增强其上下文感知能力。
多模态检索器训练
训练时,从语音转录中随机选择单词作为正样本,从不同句子中选择负样本,以区分相关和无关信息。使用二元交叉熵损失函数来优化模型性能。评估时,使用内部检索开发集来测试检索器的有效性。每个样本包括一个短音频片段和音频中提到的术语。术语是指特定关键词,如名称、位置、缩写和领域特定词汇。
实验
评估基准
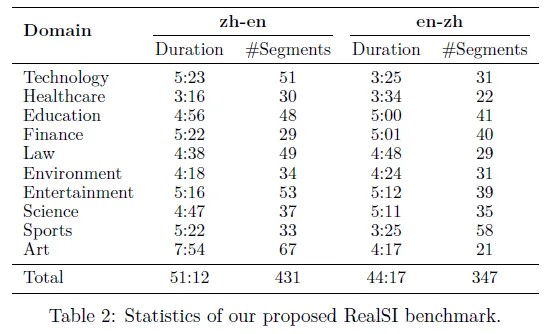
当前流行的几种机器翻译评估基准的缺点,包括语音来源不真实、评估数据集的手动分割可能会高估实际应用中的性能等。为了解决这些问题,作者提出了一个新的基准数据集RealSI,包括10个流行领域的自然语言语音,不需要手动分割,适用于中英文翻译。
基线
本文比较了CLASI和开源的SiST模型SeamlessStreaming以及几个商业系统的翻译质量。商业系统通常采用重写策略来提高翻译质量,但这可能会影响用户体验。本文使用了一个通用的外部知识库进行评估,以避免不公平比较。
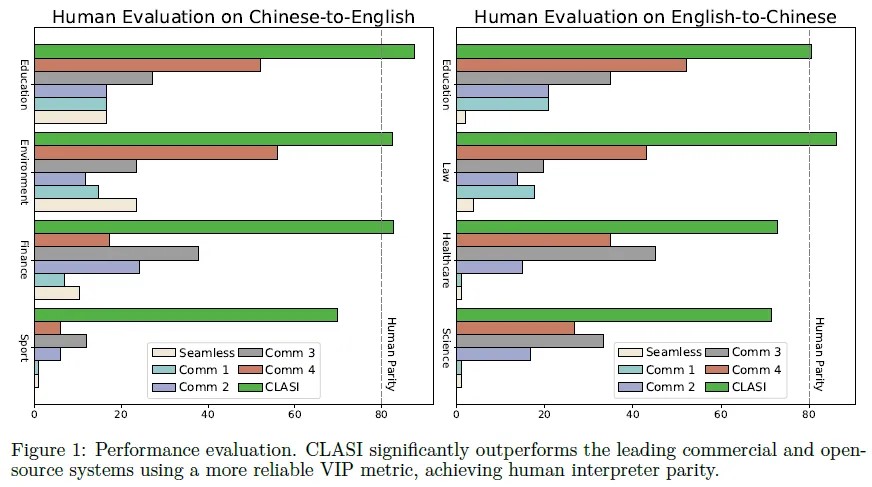
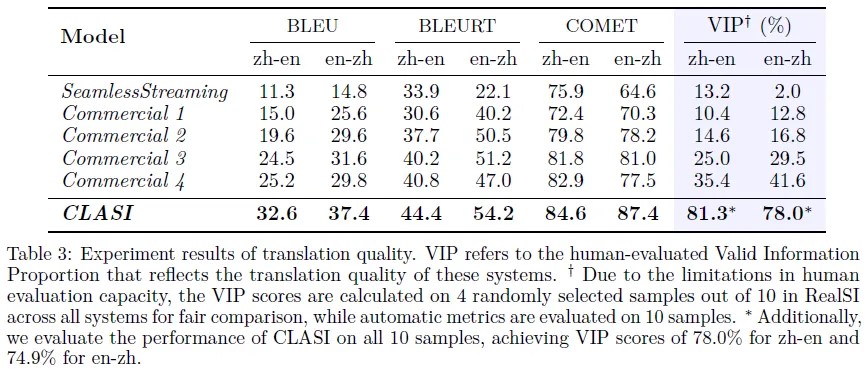
翻译质量
与其他基线模型相比,CLASI在VIP评估指标上表现出色,可实现实时语音的高质量翻译,具有实际应用价值。同时,作者指出现有的自动评估指标可能无法完全反映翻译质量,需要结合人工评估指标进行综合评估。
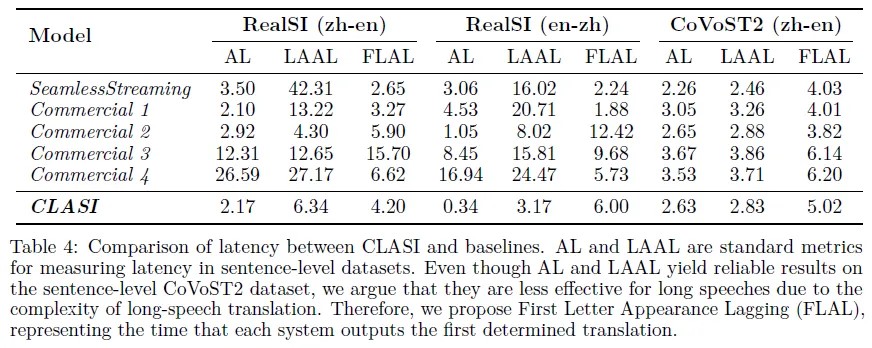
延迟
同声传译系统的延迟的指标,包括平均滞后(AL)、长度自适应平均滞后(LAAL)和首字母出现滞后(FLAL)。作者发现,对于段落级别的同声传译系统,现有的AL和LAAL指标并不适用,FLAL是更可靠和稳定的指标。作者还进行了用户调查,发现用户更注重翻译质量而非延迟。作者认为需要更精细的指标来评估长篇演讲的同声传译系统的延迟。
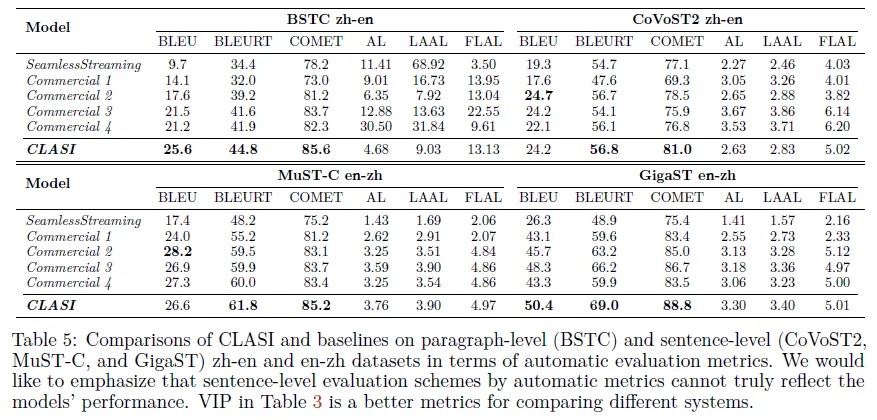
补充实验
在四个数据集上进行了评估。结果表明,CLASI在自动评估指标上表现优于基线模型。但作者也指出,句子级别的评估可能会高估SiST系统的性能。由于人工评估成本高昂,作者未能提供VIP。
MM-RAG性能
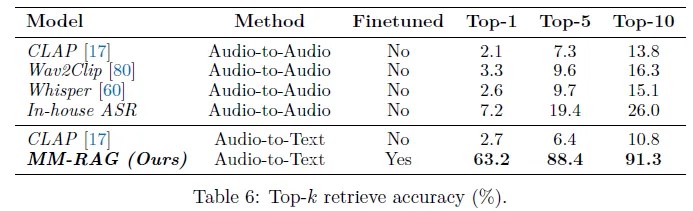
检索
MM-RAG在开发集上的表现远远优于其他开源模型,达到了91.3%的Top-10检索准确率。作者比较了两种方法:音频到音频和音频到文本。在音频到音频的方法中,使用TTS模型将外部知识数据库中的文本键转换为音频格式,形成一个基于音频的键数据库。然后使用ASR模型对音频键和用户输入音频进行编码,使用MIPS算法确定Top-k检索项。在音频到文本的方法中,作者将MM-RAG与CLAP进行了比较,结果MM-RAG表现显著优于CLAP。值得注意的是,MM-RAG检索器中使用的音频编码器与CLASI中使用的相同,这样可以确保集成对整个框架的计算延迟最小化。
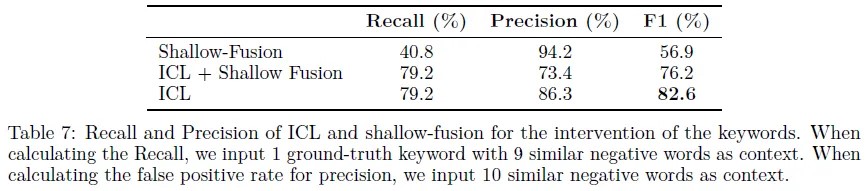
ICL表现
MM-RAG通过检索外部知识库中的术语作为上下文信息,提高了模型的上下文学习能力,特别是在术语密集的场景下。与浅层融合相比,该模型在召回率和精确率方面表现更好,F1得分最高。同时,作者还进行了MM-RAG模块的消融实验,结果表明外部知识库的引入可以显著提高VIP得分。
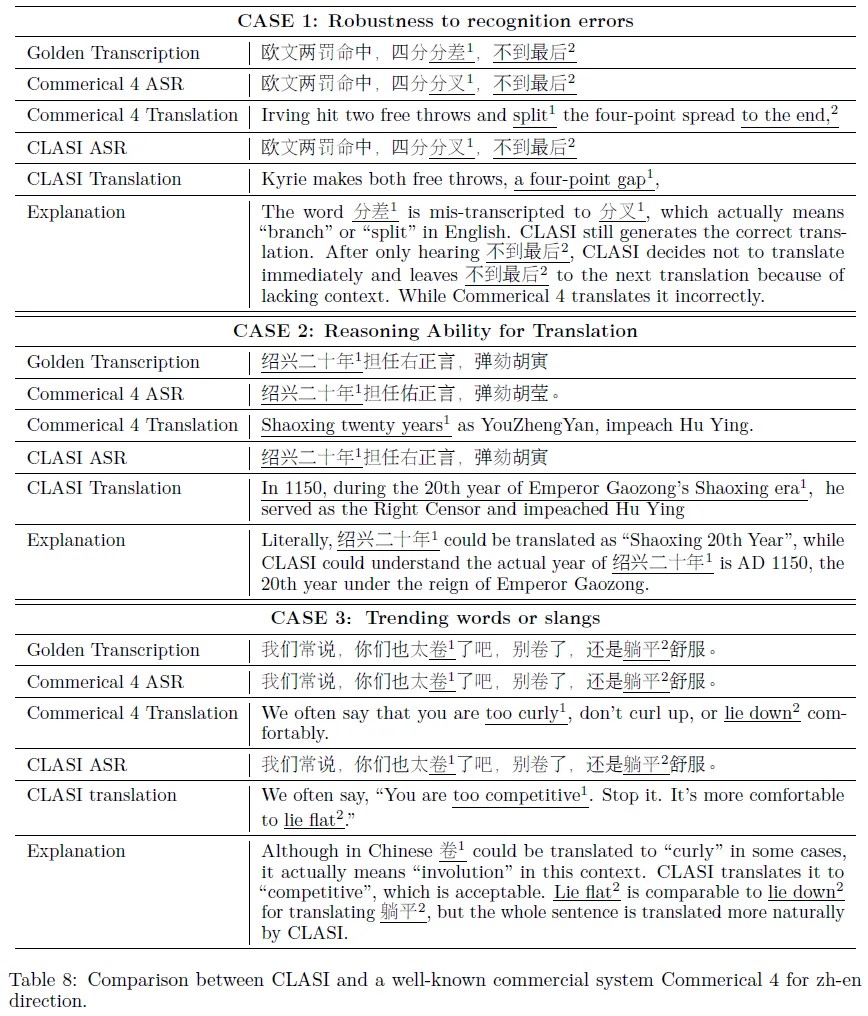
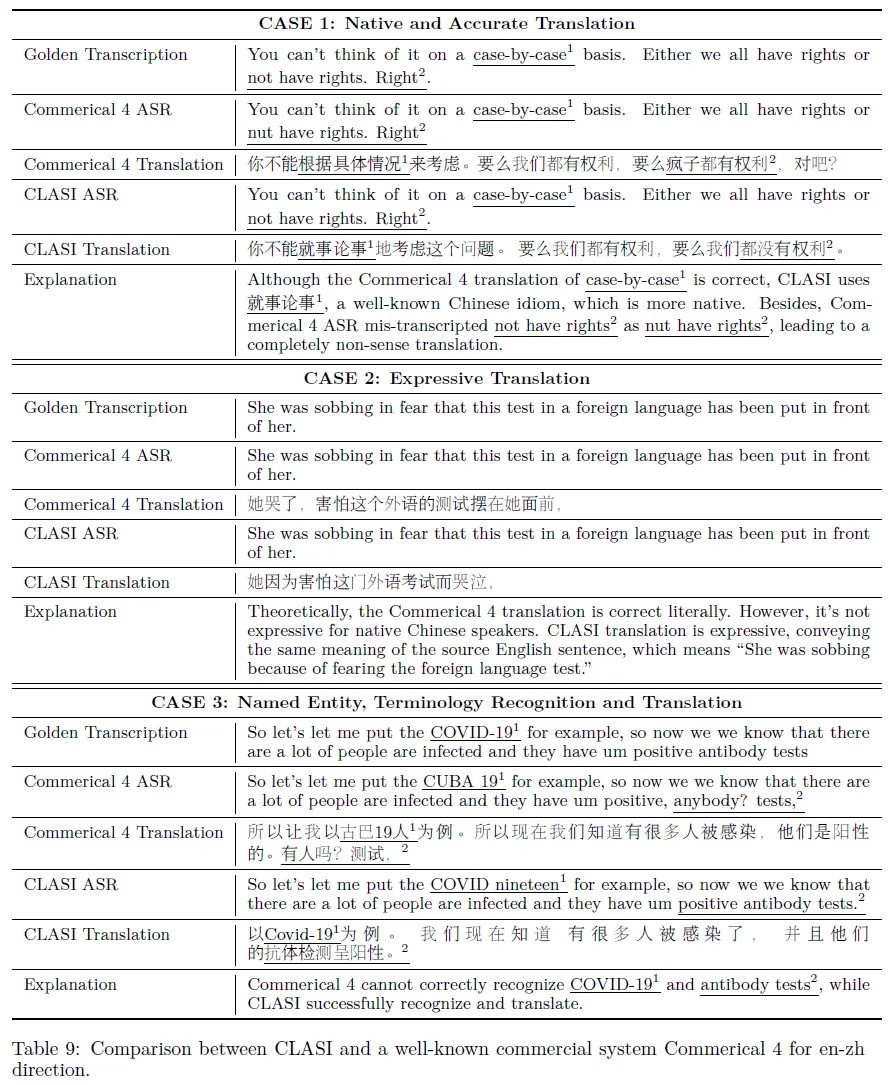
案例分析
本文介绍了CLASI在中英翻译中的能力,并通过案例展示了其优越性。与商业4号系统相比,CLASI采用级联方法,具有更好的鲁棒性和翻译能力。案例涉及到识别错误、推理能力、趋势词汇翻译、术语翻译等方面。
总结
CLASI是一个基于的语言模型代理,可以实现端到端的同声传译。CLASI通过大规模预训练和模仿学习获得了显著优于现有系统的性能。在中英文翻译方向上,CLASI在严格的人工评估指标下表现出人类水平的性能。CLASI的关键组成部分包括:(1) 基于编码器的LLM代理架构,可以通过简单的操作实现高质量或甚至人类水平的同声传译过程。(2) 从人类口译员的模仿学习中获得自然的读写策略,以数据驱动的方式平衡翻译质量和延迟。(3) 受到人类口译员准备轨迹的启发,CLASI可以从历史翻译和外部知识中进行上下文学习,为翻译提供足够的信息。CLASI的强大翻译能力可以进一步使跨语言交流在全球范围内变得无缝。![]()
![]()

我们致力于提供优质的AI服务,涵盖人工智能、数据分析、深度学习、机器学习、计算机视觉、自然语言处理、语音处理等领域。如有相关需求,请私信与我们联系。
请加微信“LingDuTech163”,或公众号后台私信“联系方式”。
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
