技术科普 | 如何翻译不可编辑文档?Abbyy + ChatGPT超强工作流快速搞定
分享英语和翻译路上的故事~ 最近做了几份证书的翻译,因为文件的特殊性,译员拿到的时候基本都是扫描件,这种情况是无法直接导入翻译软件进行处理(无论是机翻还是用trados这类的CAT软件),如果用传统的翻译方法人工对照扫描件进行翻译和排版效率非常低,高投入低回报。这时候就要来点科技了。
首先需要把扫描件进行OCR识别(光学字符识别),来把它变成可编辑的文档,然后进行处理,这一步就要用到强大的Abbyy Finereader和ChatGPT了。
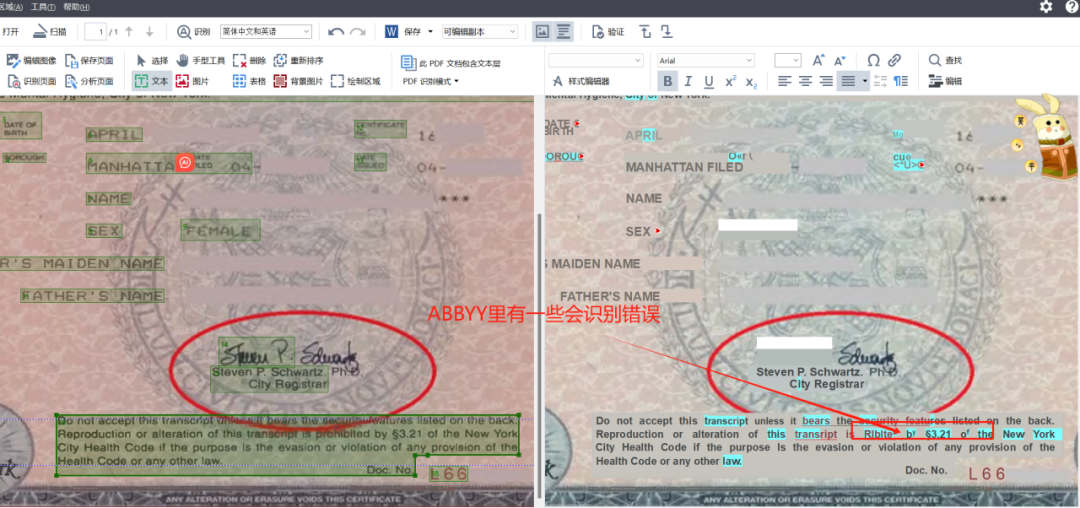
我网上找了一个证件样本。首先在Abbyy Finereader打开文件进行识别,我们看到识别以后可以比较好地保留原来的排版样式。(PS:这个软件在喵喵整理的“搞翻译必备软件资料包”里,后台回复4可购买所有工具,包括20+领域记忆库和术语库,翻译圈子成员免费获得。) 原文件 识读以后的文件
可以看到有一些错误
但是软件只能识别个大概,有很多细节需要手动调整,而且有的文字识别不出来。但是粗糙的识别文件已经保留了原来的格式,现在就要用ChatGPT来精细化作业了。
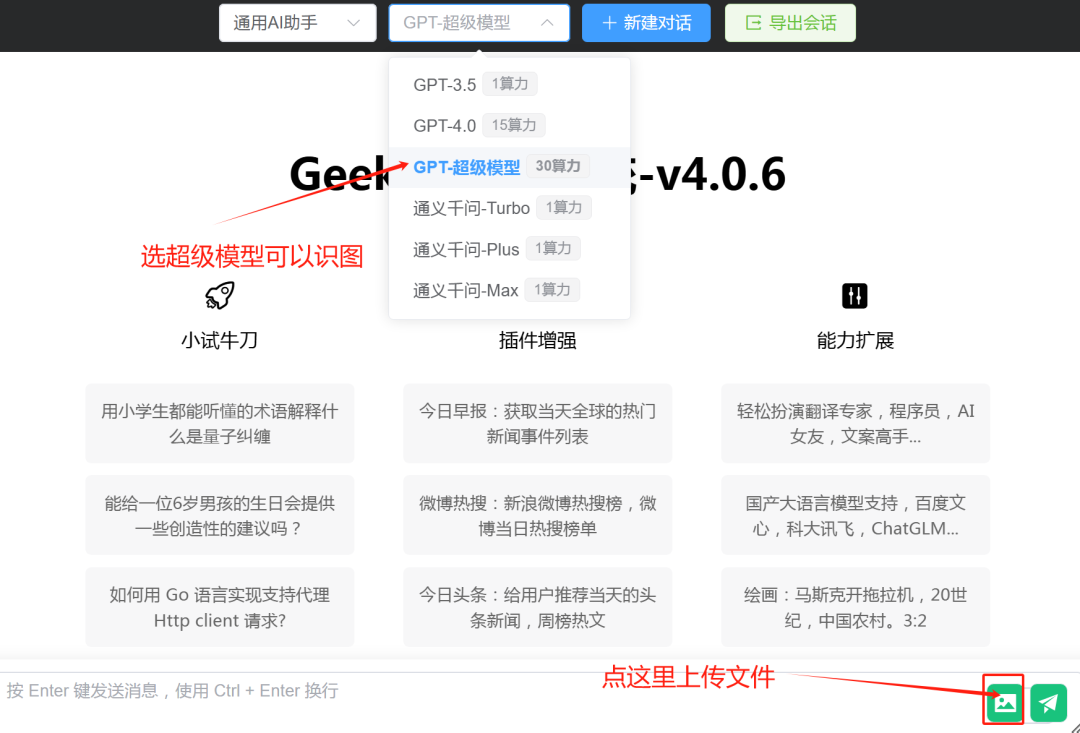
在这里选择GPT超级模型即可进行图片对话。(最近升级改版了,界面有一点不一样) 点击GPT超级模型 点击上传文件
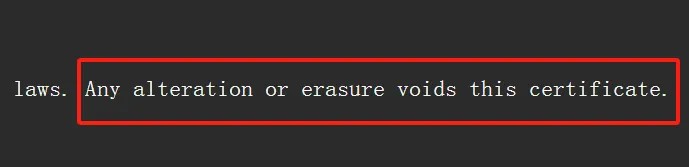
反应了一会它就生成了纯文字。还是蛮准确的,一些Abbyy没能识别的地方它也读出来了。
可以看到页尾这里非常模糊的地方Chat也读取了。 原文件还挺模糊的
接下去就是结合Chat识别出来的纯文字去校证一下Abbyy的识别结果,然后导出word文档,这时候就可以在软件里处理了,省去了人工排版的的时间。
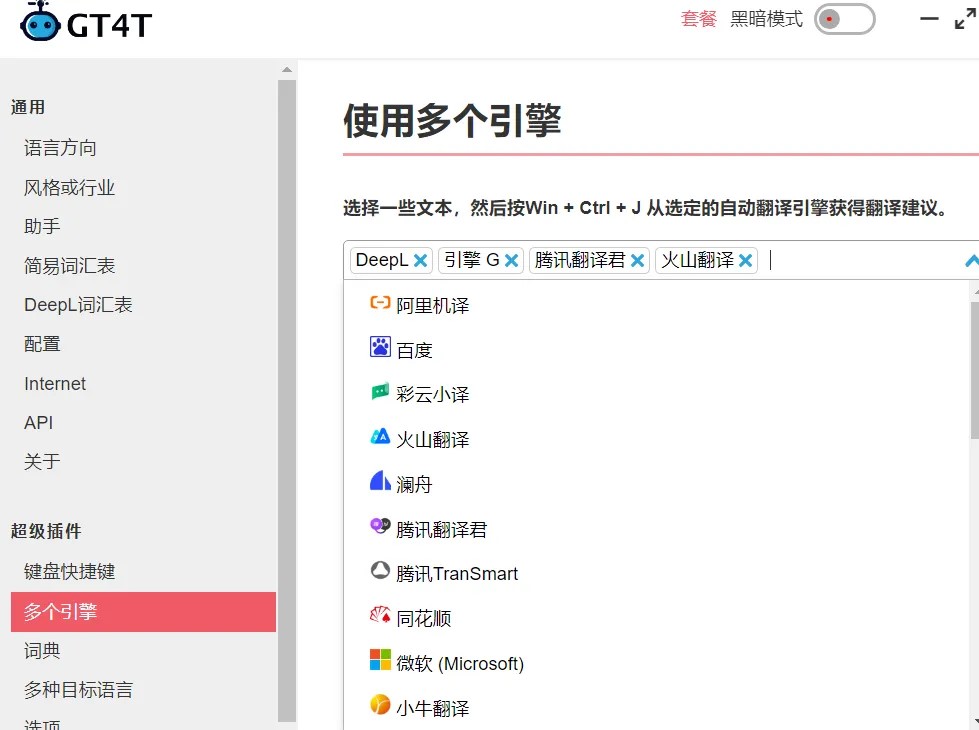
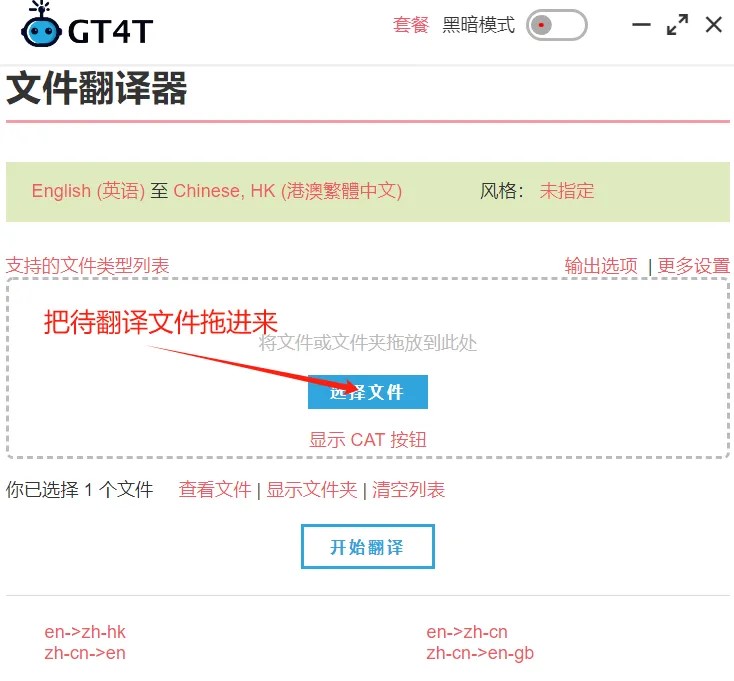
这里文档翻译推荐一款软件gt4t,是Dallas大佬开发的一款超方便的翻译软件,集成了几乎市面上所有主流的机器翻译引擎(谷歌、deepl、百度什么的),可以直接浏览器搜索下载。 选好翻译语对,直接把文档拖进文件翻译器即可翻译,就不用一段一段手动复制到谷歌或者deepl里翻译。pdf文档也可以翻译,软件会先转换成word然后输出word译文。除了这些常规文件,gt4t还能直接处理trados和memoQ的项目文件,对译员来说超方便!具体支持的文件格式可以参考这里,真的是超级全 https://gt4t.cn/docs/zh-chn/landing-page/file_translator/
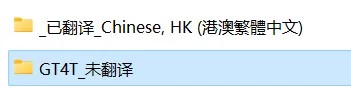
翻译完成以后会有两个文件夹,“未翻译”和“已翻译”,翻译好的文件就在“已翻译”里。
软件下载以后会有初始免费体验额度,用完以后需要购买字符套餐来翻译。购买套餐可输入优惠码miaomiao获得9折优惠。
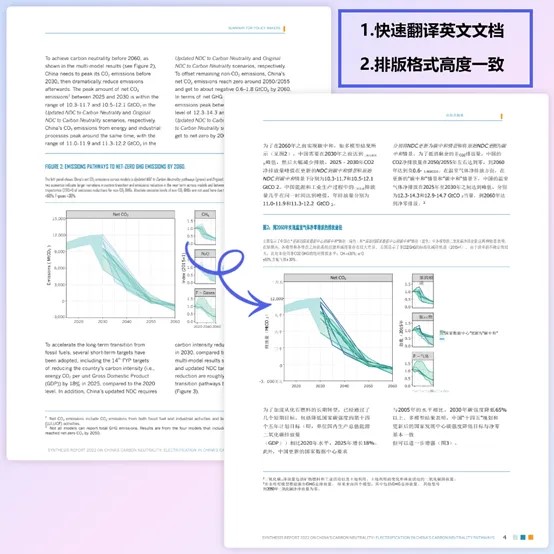
pdf文件翻译我之前分享过Medpeer平台,对于格式比较复杂图表比较多的文件可以基本上100%还原排版,可以节省很多人工排版的时间。不过翻译只是这个平台的一个功能,更多的还是为科研服务,可以查找文献、科研绘图,现在也集成了ai功能。 图片来自Medpeer公众号
关于不可编辑文件和图片的翻译,现在微信也有识图功能,可以直接从图片复制文字,手机也自带一键翻译功能,但是少量还可以,如果处理的文件比较复杂效率就比较低了。
不得不说科技改变生活啊,有了新工具就要用起来!比如之前有一个翻译问询,需要翻译一幅古画上的题词,由于高考之后文化水平直线下降,题字还真看不太懂,所以我用Chat先识别了一轮,然后调整了一下,效率很高。



特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
转载来源:OrangeJuice译站
