搜索煮译 | 那些好用的OCR工具(中)
在上篇中,我们对扫描全能王和Doc2X这两款OCR工具进行了介绍,它们的出色性能和实用功能使其成为众多用户的必备工具。继续这个系列,我们将在中篇中聚焦于PaddleOCR、OCRmyPDF、Simple-ocr-opencv和EasyOCR,这四款工具各有特色,涵盖各种用户需求,为文字识别领域提供了丰富的解决方案。 官方地址: 安装命令:pip install paddleocr 使用示例:
import paddleocr
# 初始化识别器
ocr = paddleocr.OCR()
# 读取图像文件
img_path = ‘/path/to/image.png’
img = paddleocr.read_image(img_path)
# 进行OCR识别
result = ocr.ocr(img)
# 输出识别结果
for line in result:
print(line)
-
不足:无法识别并输出表格,没有公式识别的能力。
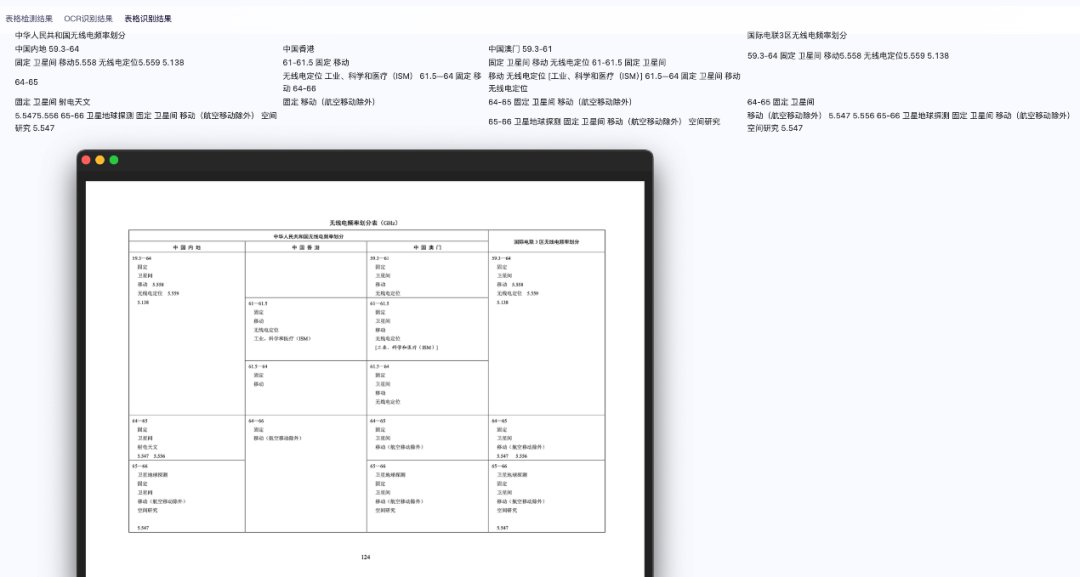
OCRmyPDF是基于Tesseract-OCR开发、训练的文字识别提取的开源项目。它可以将扫描或图像文件中的文本转换为可编辑的PDF文档。
-
官方地址:
https://github.com/ocrmypdf/OCRmyPDF
-
安装命令:pip install ocrmypdf
-
使用示例:
ocrmypdf/path/to/input.pdf /path/to/output.pdf
-
优点:
跨平台支持:无论是Windows、macOS还是 Linux,OCRmyPDF都能完美运行,满足不同用户的需求。
易于使用:用户可以通过命令行界面轻松地将扫描的PDF 文件转换为包含OCR 文本层的PDF。
高度可定制:支持多种语言的OCR 引擎,用户可以根据自己的需求选择合适的OCR 引擎。

-
官方地址:
https://github.com/goncalopp/simple-ocr-opencv
-
安装命令:pip install simple-ocr-opencv
-
使用示例:
import cv2
from simple_ocr import OCR
# 初始化OCR识别器
ocr = OCR()
# 读取图像文件
img_path = ‘/path/to/image.png’
img = cv2.imread(img_path)
# 进行OCR识别
result = ocr.ocr(img)
# 输出识别结果
print(result)
-
官方地址:
https://github.com/JaidedAI/EasyOCR
-
安装命令:pip install easyocr
注:EasyOCR的模型是基于pytorch框架训练的,在easyocr下载同时会下载一些其它附加python包,例如pytorch,torchvision等,时间需要久一点。另外,官方提示win系统要预先安装好torch和torchvision。
-
使用示例1:识别图像中的文本
From easyocr import EasyOCR
# 创建 EasyOCR 实例
ocr = EasyOCR()
# 识别图片中的文本
result = ocr.readtext(‘path/to/image.jpg’)
# 输出识别结果
for text in result:
print(text)
-
使用示例2:识别视频中的实时文本
from easyocr import EasyOCR
# 创建 EasyOCR 实例
ocr = EasyOCR()
# 打开视频文件
video = cv2.VideoCapture(‘path/to/video.mp4’)
while True:
# 读取一帧视频
ret, frame = video.read()
if not ret:
break
# 识别视频帧中的文本
result = ocr.readtext(frame)
# 输出识别结果
for text in result:
print(text)
# 释放视频资源
video.release()
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
