技术应用 | 如何利用大语言模型搜索翻译类学术文献
大语言模型,如GPT-4等,已经在多个领域展现出其强大的应用潜力,其中包括搜索学术文献。这里列举一些大语言模型助力学术文献搜索的一些方法。本节使用到的模型为Kimi.ai.
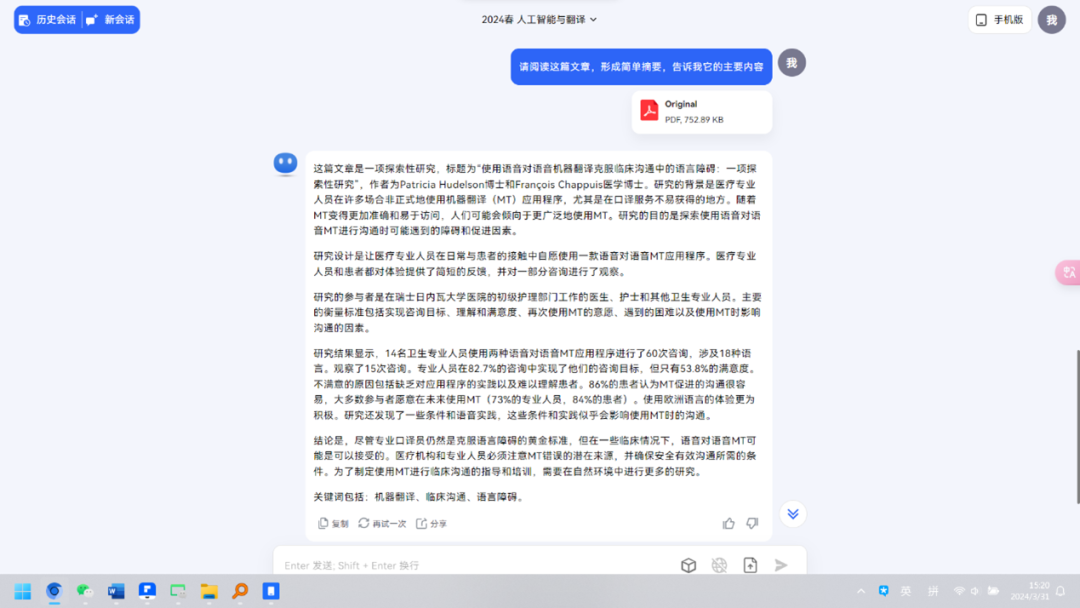
大语言模型可以帮助研究者从大量的文本中提取关键词。通过输入相关的研究主题或概念,模型可以生成一系列相关的关键词或短语。这些关键词可以用于在学术数据库和搜索引擎中进行更精确的搜索。如下图: 大语言模型可以阅读并理解大量的学术文献,然后生成简洁的摘要。这对于快速了解文献的主要内容和结论非常有帮助,尤其是在初步筛选文献时。如下图(测试使用到的文章:Machine learning based robotic End Effector System for Monitoring and Control of External Bleeding of Vehicle Accident Victims, Review Paper DOI: 10.36647/CIML/02.02.A004):
利用大语言模型的语义理解能力,可以进行更为深入的语义搜索。这意味着模型不仅能够根据字面意思搜索文献,还能够根据上下文和语义关系找到相关文献,从而提高搜索的相关性和准确性。
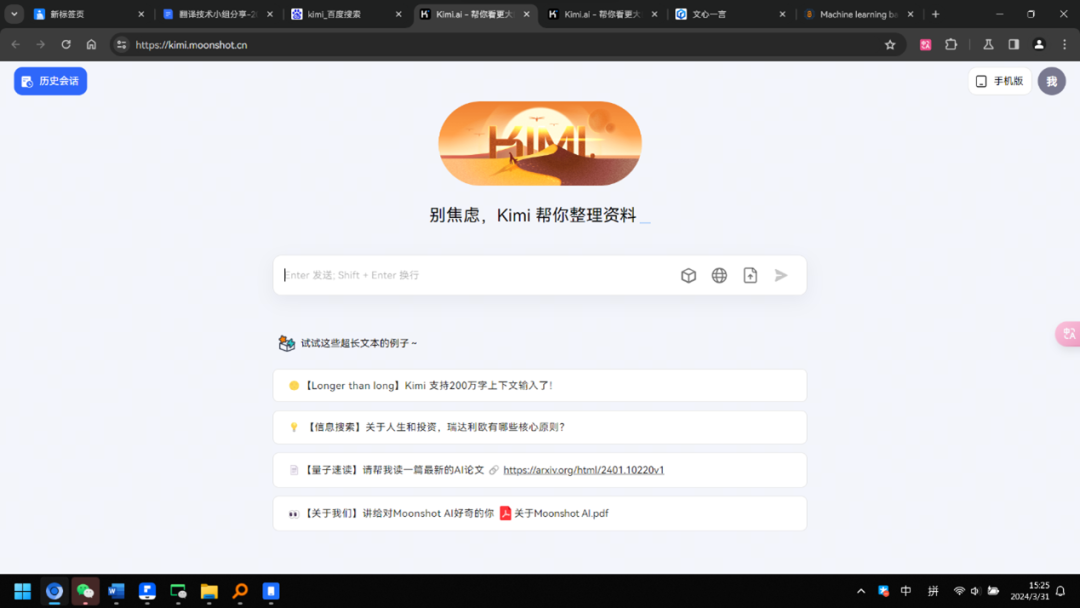
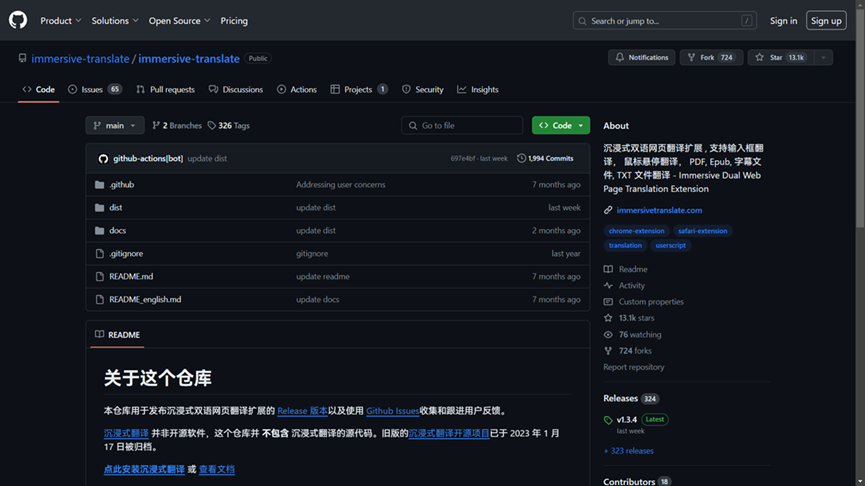
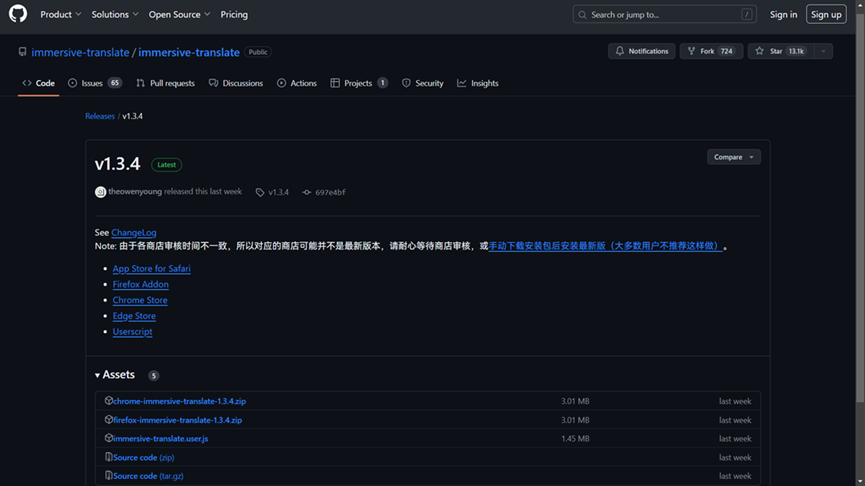
如图,来自中国的Kimi语言模型宣称能支持200万字上下文输入。强大对话能力能够提升用户的使用体验,也能更好助力研究者利用大语言模型提高文献查找效率。 大语言模型通常具备多语言处理能力,这使得它们可以跨越语言障碍,搜索和翻译不同语言的学术文献。例如,如果一个研究者想要找到中文的翻译研究文献,可以使用大语言模型来搜索并自动翻译成研究者熟悉的语言,由此提高学术文献阅读效率。 我们考虑利用大语言模型进行文献翻译。大部分文献在保存到本地(或在线阅读)时为pdf格式,我们试图找到一个工具,依托大语言模型实现pdf全文翻译,并且结果最好可编辑以方便修正或排版。 最终我们在GitHub上找到了符合上述需求的项目。GitHub是一个面向开源及私有软件项目的托管平台,得名于它只支持Git作为唯一的版本控制系统。您不需要了解Git,因为大多数项目的开发团队已经将成品打包完毕。现在我们将介绍Immersive Dual Web Page Translation Extension,一款实现输入框翻译、鼠标悬停翻译、PDF、 Epub、字幕文件、TXT 文件翻译的浏览器插件。 首先找到项目网站https://github.com/immersive-translate/immersive-translate界面如下: 单击右侧Releases模块下的标签,免费下载该工具。截止到笔者写此稿时,最新版本为1.3.4. 然后, 在“Assets”处选择适合的版本下载。
下载完成后,进入浏览器的拓展管理页。这里以谷歌浏览器为例。请注意鼠标悬停的地方,单击进入管理。 如图,将下载好的压缩文件直接拖入管理页面。拓展插件安装完成(请注意需要打开浏览器的“开发者模式”)。
该插件支持调用多个第三方翻译平台的接口,包括传统机器翻译(如百度翻译、谷歌翻译等),也支持大语言模型翻译(如DeepL, OpenAI, Azure等)。用户需要依照提示,设置翻译服务提供商(这里笔者已经设置好“火山翻译”)。若缺失该步骤,默认翻译服务提供商为“微软翻译”。 将本地的pdf文件托入浏览器,文件被打开。单击拓展插件,选择“点击翻译pdf”. 在新页面中,原文献翻译成功,并且格式对齐效果良好。屏幕左右形成双语对照。 如果对翻译结果不满意,用户可以手动修改。如下图,请注意被选中的一行字是笔者添加的。 点击右上方“保存”按钮,全文翻译的结果可以以pdf的格式保存到本地。 由此,利用该浏览器插件和第三方大语言翻译模型接口,可以实现本地pdf格式文件的翻译、修改和输出保存。 根据笔者的体验,在很多情况下,大语言模型翻译结果胜势明显。下面的例子能够证明这一点。 DeepL 和 微软翻译 的对比: OpenAI 和 谷歌翻译 的对比: 大语言模型(如神经机器翻译系统,NMT)往往比传统的机器翻译系统(如基于规则的机器翻译,RBMT,和统计机器翻译,SMT)提供更高质量的翻译结果,主要原因应当包括以下几点: a.复杂性处理能力:NMT使用深度学习技术,特别是循环神经网络(RNN)和注意力机制,能够捕捉和学习源语言和目标语言之间的复杂和长距离依赖关系。这使得NMT能够更好地处理自然语言的复杂性和多样性。 b.语境理解:NMT通过大量的双语语料库进行训练,使其能够更好地理解语境和上下文信息。这意味着NMT在翻译时能够考虑到整个句子或段落的含义,而不仅仅是单词或短语的直接对应。 c.语义和语法的准确性:由于NMT能够学习语言的深层语义和语法结构,它在处理歧义和复杂语法结构时通常比传统模型更为准确。这减少了错误翻译和不自然表达的可能性。 d.数据驱动的学习:NMT系统通常使用大规模的数据集进行训练,这些数据集包含了各种语言风格和领域的样本。这种广泛的训练数据使得NMT能够适应多种翻译任务和需求。 e.端到端学习:NMT系统通常采用端到端的学习方式,这意味着从输入到输出的整个过程都是自动化的,不需要手动设计特征或规则。这种方法使得模型能够自我调整和优化翻译策略。 f.适应性和灵活性:NMT模型可以通过微调来适应特定的领域或语言对,从而提供更符合特定需求的翻译结果。这种灵活性是传统机器翻译系统难以比拟的。 g.持续的技术进步:随着人工智能和机器学习领域的快速发展,NMT系统不断得到改进和优化。新的模型和技术,如Transformer架构和预训练语言模型,进一步提高了翻译质量。 更高的翻译质量在降低研究者的理解难度、辅助研究者理解文意和抓取有效信息方面十分重要。推广到翻译类学术文献上,恰当地利用大语言模型,能够助力研究者搜索与理解翻译类学术文献。
群内会定期推送语言服务行业最新动态、活动预告、竞赛通知?等内容~ 欢迎你的加入?!






![]()
