译学文献 | 刘海涛:从语言数据到语言智能——数智时代对语言研究者的挑战
 速览精华?
速览精华?
刘海涛教授的这篇文章深入探讨数智时代对语言研究者的挑战,极具价值。文章剖析数智时代 AI 发展,指出其重新定义知识,引发语言研究变革。强调语言学家应关注 “数据→模式→知识→网络→智能” 链,在模式和网络环节发挥作用,从真实文本探寻语言规律,以解释大模型行为。此研究为语言研究者提供新视角与方向,助力把握数智时代机遇,推动语言学发展,对相关领域研究意义重大。
1
从图1不难看出,人工智能在20世纪80年代中后期曾经达到一个高峰,原因在于日本当时提出了一个第五代计算机计划(渊一博、广濑健,1987),也叫基于知识的智能机计划,其核心为逻辑程序语言Prolog+知识库,而所谓知识库是由人工建立的,知识表示形式采用的是人可以解释的形式。第五代计算机是可解释AI的集大成之作,但没有达到预定的目标,于是AI开始走上了下坡路。
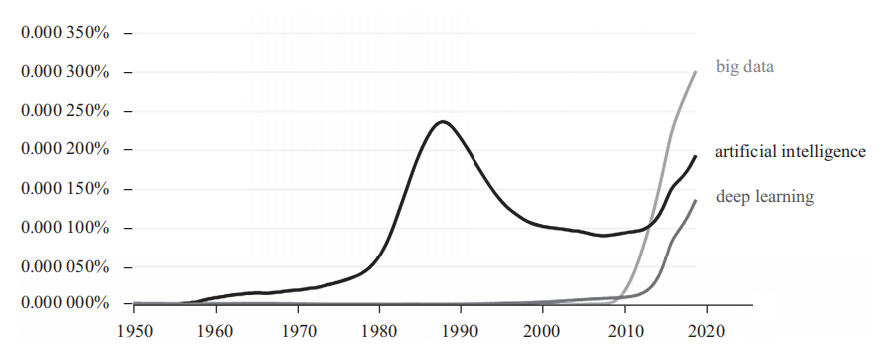
图 1 人工智能近70年的发展
然而,人们对于采用非传统的方式创造智能体的努力并没有停止,从图1可以看出在2010年左右,AI又开始进入上升通道,并保持强升态势。正如我们此前所说的那样,智能与知识的获得、表征与应用密切相关,从理论上讲,AI的进步离不开人们在知识处理相关领域的突破,但诡异的是,很多人认为这次AI的进步与知识无关,以至于不断有人说要在现在的技术中加入知识的成分。这话听起来很不合逻辑,似乎计算机突然之间变得不用知识就可以完成过去我们认为需要知识才能做的事情。新技术好像重新定义了智能,但事实上,我本人更愿意相信基辛格等人的说法,新技术重新定义的是知识,而不是智能,智能还是运用知识解决问题的能力。
仔细观察图1,我们还可以发现有另外两条线几乎与“人工智能”是同时起飞的,这就是“大数据”(big data)和“深度学习”(deep learning)。也就是说,AI是与大数据和深度学习联动的,智能是通过深度学习的方法从数据中涌现出来的,而不是像此前那样用人类理解的方式把我们认为是知识的东西输入机器,机器便有了智能。为了区别于传统的AI技术,人们将目前的AI称为“数据智能”或“数基智能”,于是人工智能时代也被精确为数据智能时代,进而精简为“数智时代”了。
数据为什么能涌现智能?这是未来很长时间内,数智时代对人类认知的挑战。对于语言学家而言,面临的挑战可以进一步精确为:语言数据为什么能涌现语言智能?
乍一看,这个挑战似乎是无法应对的,因为数千年来,人类关于知识与智能的探究基本都与数据无关,但仔细分析以ChatGPT为代表的新一代AI技术,还是可以找到一些切入点的。特别是对于语言学家而言,如果能把握这次千年难遇的人类认知或知识革命,就极有可能将挑战转变为机遇。我们这么说的理由在于:语言是人类的革命性特征,语言智能在人类的所有智能活动中是最能反映人类智能特点的。因此,“大语言模型”(Large Language Model,LLM)几乎成了数智时代的另一个代名词,也就不足为奇了。在一本名为《大数据入门》的书中,提到了有助于构建AI的学科,其中有计算机、数学、医学、心理学、工程和语言学(Sarangi & Sharma,2020:26)。这里引用这本书的目的不是说语言学有多重要,而是想再次强化数据与智能的关系,而这种关系对于传统的语言研究来说是陌生的。事实上,正是这种陌生使主流语言学与这个时代渐行渐远,也就有了“解雇一个语言学家,系统性能会更好一些”的说法,当然,也有诸如“每当你雇用一位受过良好训练的语言学家时,你的树库就会更好一些”等积极的说法。
作为数智时代的语言研究者,听到这两句话,可能需要反思这样一些问题:为什么解雇了我们,系统会更好呢?是我们获得知识的方法不对?还是表征知识的方式有问题?抑或是我们一直关心的问题,可能不是驱动人类语言系统运作的主动力?什么才算是受过良好训练?树库是什么?树库好一些与系统好一些有什么关系呢?
限于篇幅,本文不可能面面俱到地回答以上问题,有兴趣的读者可参考刘海涛(2022)。下面我们从语言研究的角度讨论文本、数据、模式、定律、知识和智能的关系,希望有助于发现数智时代语言研究的切入点。
语言学教材Language Files中有一张我喜欢在“语言学导论”课上常用的“言语交际链”示意图(Dawson & Phelan,2016:8),图中有9个环节:(1)思考想传达的东西;(2)挑选能表达想法的词语;(3)依规则将这些词语按一定的顺序排列起来;(4)找出这些单词的发音;(5)将这些发音送到说者的发音器官;(6)说者发出有关词语的声音;(7)听者听到声音;(8)听者将声音解码为语言;(9)听者接收到说者想传达的思想。
这9个环节,除了(6)(7)之间的音序列,其他环节都是难以进行客观观察的,大多是我们对于语言生成与理解过程的想象和构拟,但遗憾的是,我们很难据此构造出类似人类水平的机器,而没有按照这种方式构建的数(基)智(能)体却有更强的自然语言交互能力。为什么会这样呢?如果将音序列转换为文字,那我们可进行客观研究的对象就变成了线性的文字符号序列。换言之,基于这些音(文字)序列发现的规律可能更接近科学意义上的语言规律。人类语言所具有的这种线条性,是人类生理机制约束的产物,也是索绪尔认为的语言最重要的两大特性之一。但专门研究语言的科学家对可观察的人类语言线性序列所蕴含的规律又知道多少呢?如果考虑到,诸如ChatGPT之类的AI系统就是从这样的序列中习得语言规律,并使用这些规律预测线性语流中接下来会出现的词,进而生成符合人类使用习惯的语言符号序列的,那么,ChatGPT的成功,可能就揭示了一些“在科学上非常重要的东西:人类语言及其背后的思维模式在结构上比我们想象的更简单、更‘符合规律’。ChatGPT已经隐含地发现了这一点”(沃尔弗拉姆,2023:103)。这是否也意味着,现代的语言研究者把语言想得过于复杂了,复杂到了人不好理解,机器更搞不懂的程度。更有可能的是,这种复杂并没有揭示语言系统运作的本质规律。如果是这样,ChatGPT恰巧“发现”的规律长什么样呢?
在谈到ChatGPT如何生成更像自然语言的词时,沃尔弗拉姆(2023:11)说道:“还可以通过强制要求‘词长’的分布与英文中相符来更好地造‘词’。”虽然对于主流语言学而言,词长分布可能是陌生的,但它却一直是计量语言学研究的一个主要方向(Chen et al.,2015;练斐等,2024)。如果词长分布的规律有助于生成更自然的“词”,那句长分布的规律也会有益于生成更自然的句子。基于数十种语言的真实语料,人们发现词长分布符合齐普夫-阿列克谢夫分布规律(Popescu et al.2014:14-86),而句长则更符合扩展正负二项分布(周义凯、刘海涛,2023)。“从这个意义上来讲,学会一门语言,本质上就是掌握一套非常复杂的概率分布。”(陈浪,2024:40)由于这些源于自然语言文本的概率分布反映了以天然神经网络为载体的人类语言系统运作的基本规律,而“语言模型的目标就是建模自然语言的概率分布”(张奇等,2024:1),所以这些数据驱动的语言研究可以提供切实的理论基础,使大模型能够选择更好的参数、构拟更好的人工神经网络,进而使机器学习更有针对性、更有效、更省力。
显然,尽管词长、句长分布规律简单适用,但仅有这些是不够的,我们还需要其他层面的数基规律,如依存距离最小化和依存方向连续统(刘-有向性)等可以反映人类语言系统组织和运作的规律(刘海涛,2022)。这些规律是从人类真实语料中发现的,或者说,大多是人无意识地从语言的使用过程中获得,又在语言的使用中不断完善而形成的,是人类语言系统得以顺畅运行的基础,也是语言智能的反映。既然如此,我们的问题即为,ChatGPT之类的大模型是否掌握了这些规律,换言之,在大模型这个“黑盒子”里,能找到类似的规律吗?如果能找到,这些规律又长什么样呢?
前文说过,语言的线条性很重要,不仅因为它是人的生理机制约束的产物,是语言作为一种人驱系统的体现,更是因为线性字符串几乎是语言研究者唯一可客观观察的对象。索绪尔在《普通语言学教程》中也意识到(1980,0.3 章节),语言是言语的“平均数”,没有一个人的语言是完备的。索绪尔说的这个从言语中产生的抽象的语言“平均数”就是“语感”,也可以说,你的语感或语言是从语言使用中涌现出来的。如果语言是言语的“平均数”,越多的“言语”数据参与到计算过程中,算出来的“平均数”就越接近那个抽象的“语言”,你的语感也就会越好;如果没有一个人的语言是完备的,在“平均数”的计算过程中,有越多人的“言语”参与进来,最终得到的“平均数”(语言)也就越完备。如果再考虑到语言不是一个非黑即白的系统,而是一个灰色的概率系统,没有数据是无法感知到语言的“灰度”的,那么,从大量真实语料中获得线性规律并用这些规律做事的ChatGPT能比它的AI前辈们更智能的原因,也就不难理解了。
回到刚才提及的两个问题:能找到类似的规律吗?如果能找到,这些规律又长什么样呢?这两个问题密切相关,因为人们找不到不知道长什么样子的东西。想要在大模型中找规律,先要搞清楚规律长什么样。尽管规律长什么样可能确定不了,但它不长什么样,还是清楚的。因为在大语言模型中,除了实数还是实数,所以大模型中一定没有我们语言学家习惯的各种东西。这样一来,大模型学到的语言规律就只能是数基规律,此前提到的词长、句长分布规律就是这种规律。除此之外,要找的规律还应是有用的和可理解的。
考虑到所有这些因素,张子豪和刘海涛(2023)研究了词的线性位置分布规律,即词在句子中的线性位置的概率分布。该研究表明,词的线性位置分布在6种语言中存在普遍模式,更重要的是,我们也在大模型的内部发现了这些模式。这可能说明,驱动人类语言系统运作的知识可能并不是或不只是以人类数千年来认为的形式存在的和起作用的。这些从真实语言中发现的、我们原本“不知道自己不知道”的规律,可能有助于人类逐渐打开数智黑箱,有益于在透明的数智玻璃箱中发现语言学家本该知道的东西。在这种情况下,我们也不能由于自己的认知局限,忽视数基大模型在知识获得、表征与处理等方面引发的革命性变化,而简单地说数智体是“高科技剽窃”“随机鹦鹉”等,因为模式和规律也是知识,而且是有用的知识。
如果语言大模型只是基于从语言数据中所发现的模式(规律)生成符合这些模式的文本,我们总觉得缺了一点什么,因为人类语言是脱离不了意义的存在。事实上,“自然语言处理界几十年的发展历史就是与歧义斗争的历史”(刘海涛,2001:25-26)。大模型能取得今天的成就,说明它找到了更好的歧义消解的方法,而这单靠词长、句长分布规律是搞不定的。为什么此前采用语言学家习惯的语义处理方式,计算机解决不好意义问题呢?其根本原因可能在于,语义学家一直采用各种形式化的手段来处理本质上不可分解的“意义”,而大模型抛弃了所有这些用五花八门的概念打造的远离日常语言的空中楼阁,回到了真实的语言,踏上了像人一样处理语言的征程,所以成功了。为什么回到日常语言,基于大量的真实语料,就能更好地把握词语的意义呢?因为按照维特根斯坦的说法,一个词的含义是它在语言中的用法,即意义只能在语言使用中发现,在使用中建构。也可以说,要捕捉一个词的意义,需要构建这个词与其他相关词的关系网络,否则语言学就成了研究“没有人的人类语言”的游戏。这个问题,我们在31年前已有提及(刘海涛,1993)。毫不夸张地讲,大模型能有今天,很大程度上是由于它实现了“用法论”。从文本语料中获得词的用法信息,并将其表征为一个唯一的向量,几乎成了当前计算机处理语义的标准操作(Smith,2020)。我们用这种方法可以得到每个词语的语义值,而且这个值还能随使用的变化而变化,学得越多,对词义的理解也就越透彻,充分体现了语言的概率性和学习的本质。
从真实语料中得到的人类语言线性规律为大模型生成符合人类使用习惯的字符串提供了有用的知识,基于“用法论”的语义处理机制又使大模型有了生成有意义话语的能力,所有这些都被集成在以人造神经网络为核心的电脑之中。如果将这种基于网络的知识处理方式符号化,学习或训练的本质就是增加新的节点,在已有节点间增加新的联结,调整网络中已有节点之间的权重等旨在寻求关系、构造网络的简单操作,而语言生成不外乎是在习得的网络的加持下不断预测线性语流中接下来可能出现的词语的过程。尽管我们对两种神经网络的了解还很有限,尽管神经网络与语言符号网络有这样那样的不同,但人和大模型均是在网络的支撑下运作的这一点是可信的,因此我们需要开展基于网络的各种语言学研究。这一点,其实也可在索绪尔(1980:160)的《普通语言学教程》中找到理据,“语言既是一个系统,它的各项要素都有连带关系,而且其中每项要素的价值都只是因为有其他各项要素同时存在的结果”。按照这个说法,研究语言最适宜的方法可能是网络方法,因为,只有网络才能更好地展现语言系统的要素以及它们之间的联系(Hudson,2007)。在大模型时代,不仅要用网络方法研究人类语言的结构模式和演化规律(陈衡、刘海涛,2023;刘海涛,2022),也要研究大语言模型内部的组织结构(Zheng,2024)。只有这样,才有可能破解大模型之谜,进而加深对知识获得、表征和处理机制的理解,打破数千年来在人类“软件”研究方面一直存在的“获得不足,验证来补”的困局。
作者简介:
刘海涛,浙江大学外国语学院教授,博士生导师。研究方向:计量语言学、数字人文、依存语法、语言规划。
来源:高教社外语
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
