译学文献 | 赵衍 张慧 杨祎辰:大语言模型在文本翻译中的质量比较研究


摘要:该研究选取了小说《繁花》中的部分代表性文本,分别用ChatGPT 4.0、文心一言和讯飞星火三个大语言模型以及Google翻译、百度翻译、有道翻译和DeepL四个传统在线翻译系统进行多角度、多轮翻译测试,并用豪斯量表和MQM量表对译文的准确性和文学性进行评价。结果显示,文心一言和讯飞星火在文学文本汉译英上的表现超越了传统的国内外机器翻译系统,而且优于ChatGPT。
关键词:大语言模型 文本翻译 翻译质量评价
随着计算机技术和计算技术的不断进步,翻译正从人工翻译全面走向机器翻译(Machine Translation,MT)。机器翻译是利用计算机将一种自然语言(源语言)转换为另一种自然语言(目标语言),经历了基于词典的翻译、基于规则的翻译、基于统计的翻译、基于机器学习的翻译等几个主要阶段。
近两年来,随着算法和算力的不断进步,基于海量、高质量训练文本的大语言模型(Large Language Model, LLM)开始出现,其参数规模动辄上亿甚至百亿、千亿。大语言模型具有跨领域和跨任务的通用性,在多个基准测试(Benchmark)上均有出色表现,因此,也被称为基石模型或基础模型。大语言模型具备强大的语言理解和语言生成能力(Pavlick,2022),并能根据指令完成包括翻译在内的各类任务。此外,大语言模型还具备情景学习(In-Context Learning, ICL)和思维链(Chain-of-Thought, CoT)等涌现能力,能够利用上下文中的额外信息对自身生成的预测结果进行优化调整,为机器翻译范式革新提供了可能(朱文昊等,2023)。大语言模型的出现,让机器翻译迈入新时代:一方面,大语言模型可直接作为机器翻译工具来使用;另一方面,大语言模型也可作为翻译教学的重要辅助工具,提高翻译教学的效率和效果。
翻译学包括翻译理论研究、翻译史研究、翻译批评研究三个重要组成部分(张霄军,2007)。翻译质量评估(Translation Quality Assessment, TQA)属于翻译批评研究的范畴。近年来,随着全球交流的不断加深,对翻译需求的不断增加推动了翻译质量评估研究的深入开展。
国外翻译质量评估研究始于20世纪70年代。其中,影响较大的是朱莉安·豪斯(Julian House) 的功能—语用原则、凯瑟琳娜·赖斯(Christina Reiss)的语篇类型评估原则以及马尔科姆·威廉斯(Malcolm Williams)的论辩理论模式(李曦, 2010)。朱莉安·豪斯所著的《翻译质量评估模式》及修订本《翻译质量评估修订模式》是翻译质量评估研究史上的经典之作。朱莉安·豪斯试图创设一种新的模式,通过从语义、语用和语篇三个层面对原文和译文进行分析和比较,从而得到描述两者之间对应程度的详细报告,然后再据此评价译文的好坏(张美芳,2005)。
除了对已出版翻译作品的评估和职业翻译实践中的评估,翻译教学中的评估也被纳入翻译质量评估的范围(Melis & Albir,2021)。但是,相较于前两类评估领域的不断演进和完善,翻译教学中的翻译质量评估存在研究不足的情况。有学者提出融合学界和业界的评估方法,如在评估中采用MQM错误层级量表(李彦、肖维青,2020)。
国内翻译教学的研究目标经历了从吸收跟进西方译学理论与方法到实证中国文学外译的翻译、传播与接受的变化(王峰等,2024)。随着研究目标的变化,研究对象也发生了变化。传统翻译教学研究常受限于技术条件和伦理偏见,多以人类译者或其完成的翻译作品为研究对象,很少将传统机器翻译或大语言模型翻译考虑在内(胡开宝、李晓倩,2023)。同时,传统翻译教育面临着教学资源获取低效、教学互动受限、反馈滞后、数字素养提升缓慢等问题,大语言模型的出现为这些问题提供了解决方案,成了翻译教育创新的驱动力(王华树、谢斐,2024)。因此,近年来,翻译教学研究的对象从人工文本转为机器翻译文本,大语言模型在翻译教学中的应用研究也开始兴起。
GPT、BERT等大规模预训练语言模型的出现进一步推动了机器翻译的发展。机器翻译作为自然语言处理(Natural Language Processing, NLP) 中的一个经典任务,在大语言模型研究中被广泛实践(Minaee et al.,2024)。在此背景下,前期相关研究主要聚焦大语言模型的易用性,或讨论大语言模型如何利用提示工程在教学中发挥主体作用(许家金、赵冲,2024),或提供现状分析与方法论的指导(王立非、林旭,2023)。因此,虽然大语言模型为翻译教学提供了更多可能性,但在大语言模型尚存一些不足以及版本不断快速迭代的背景下,如何将其应用于外语翻译教学实践,如何迎接大语言模型对译者能力、语言质量和翻译伦理带来的挑战,促进“工具理性” (实用主义)与“价值理性”(人文主义)的统一(王贇、张政,2024),以及如何对接大语言模型技术的快速发展、推动其在外语教学中的应用(胡开宝、高莉,2024),仍是亟待解决的问题。
大语言模型表现出的基础语言能力和泛化能力具有划时代意义。具体到文本翻译领域,大语言模型对自然语言出色的理解能力在一定程度上有助于提升译文的准确性和可读性。但是,若大语言模型未经过针对特定领域的参数微调或训练下游任务,其翻译质量能否超越传统的机器翻译工具和垂直翻译系统尚待验证。
目前的大语言模型均基于Transformer架构,通过自注意力机制和位置编码等关键技术,对海量文本进行训练,再通过对抗训练和不断的参数调优生成而来。在大语言模型内,往往有百亿、千亿规模的参数(GPT-3.5已经有1750亿个参数),这些参数用于文本语义的表示,当把文本输入大模型后,文本就会被映射到高维的向量空间中。由于大语言模型基于海量、高质量的文本训练,其对语义的理解更加宽泛、准确、细腻,具有传统文本处理工具无法比拟的优势。
翻译涉及语言、文化、语境等多方面因素。翻译的目标是“信达雅”,即译文的内容要准确,语法结构顺畅且连贯,语言具有文学性。从理论上而言,相较于传统翻译系统,基于大语言模型的机器翻译在“信达雅”三个维度上均应该有更好的表现。
第一,更准确。自引入神经网络后,机器翻译就进入了神经机器翻译 (Neural Machine Translation, NMT) 时代,神经机器翻译基于海量语料进行模型训练,并采用神经网络完成源语言到目标语言的翻译。在神经机器翻译系统中,源文本被快速映射到丰富的 语义向量空间中,语义理解更准确,在多数语言对上逐渐超过了统计机器翻译方法(李亚超等,2017)。大语言模型可被视为更高级的神经翻译系统,基于包含千亿规模参数的大型神经网络。从理论上来讲,它们对源语言语义的理解更透彻,输出的译文也更准确。
第二,上下文更连贯。对长文本的处理是传统机器翻译系统面临的一大难题,其表现是译文上下文缺乏逻辑性和连贯性。大语言模型中引入了Token这个概念用于控制上下文长度。Token是支持大语言模型进行语言处理的最小意义单位,是模型的基础单元,一个模型能处理的最长文本长度就是Token的长度。大语言模型能够处理的Token越长,上下文的语义关联程度就越好,语义表达就越准确。现在很多大语言模型都具备同时处理几千到几万个Token的能力。因此,从理论上来说,大语言模型在翻译长文本的任务上能有更加出色的表现。
第三,更接近人类语言的表达方式。机器翻译是通过算法不断去“猜”下一个词的连贯过程,传统思路是把匹配度最高(综合得分最高)的词作为下一个词。但经验告诉我们,人类语言具有多样性和一定的随机性,匹配度最高的词不一定是最合适的词。因此,很多大语言模型中都设置了一个被称为“温度” (Temperature)的参数,用于控制模型生成文本的随机性和创造性。“温度”值越高,预测词的概率方差越小,候选词越多,模型生成的文本就越多样化和具有创造性;反之,温度越低,生成文本的一致性越高,就越缺乏多样性。“温度”的设置,让大语言模型生成的内容更加符合自然语言表达的多样性和随机性。事实证明,ChatGPT这类的生成式AI具有更丰富的语言表达能力。
大语言模型在语义理解上的表现极大程度上依赖于其训练语料,训练语料的数量、质量和类型决定了其在不同任务上的性能。在文本翻译中,如果大语言模型的训练语料中缺少相关平行文本和专业词汇,则其翻译质量就难以得到保证。
第一,缺乏翻译专用的训练语料。训练语料对机器学习系统的性能表现有至关重要的影响。大语言模型的海量训练语料大部分来自互联网,虽然训练语料规模庞大,但在语料中缺乏对提升模型翻译性能至关重要的数据对(Pairs)。因此,大语言模型虽然在一般语义理解和对话方面表现出色,但在文本翻译方面的表现未必优于传统的专用翻译工具。
第二,缺乏专业领域知识。大语言模型的“大”主要体现在其训练数据量大、模型层数大、模型参数量大和训练模型的计算量大。海量参数赋予大语言模型更广泛的语言理解能力,因此,大语言模型具有更强的通用性和更好的泛化能力。但在特定领域,大语言模型的表现未必优于一些传统领域的垂直语言模型。在文本翻译领域,大语言模型一般都不会特别面向文本翻译进行专门训练,更不会使用特定领域的专业平行文本进行训练,因此,大语言模型在一些特定文本翻译上的表现可能并不优于传统翻译软件,即大语言模型虽然对通用表述的理解力更强,但缺乏专业知识。而有些传统翻译工具内置了专业词汇库,对专业词汇的翻译更加准确。但是,如果用大量的特定领域内的专业平行文本对大语言模型进行微调或者训练下游任务,则可大幅度提升大语言模型在特定任务上的翻译性能。
第三,无 法 消 除 大 语 言 模 型 的 幻 觉。“ 幻 觉”(Hallucination)是大语言模型的一个重要缺陷。“幻觉”指的是大语言模型在推理时,会生成不遵循原文或者不符合事实的内容(Ji et al.,2023)。大语言模型的幻觉主要表现为逻辑谬误、捏造事实和数据驱动的偏见三种形式(Ji et al.,2023)。数据源、训练过程和推理过程是大模型产生幻觉的三大来源(Huang et al.,2023)。虽然可以通过调低“温度”、改进提示工程、整合外部知识等方法在一定程度上减轻大语言模型的幻觉,但目前还无法从根本上消除大语言模型的幻觉。
本次实验旨在通过测试,纵向比较传统翻译工具与大语言模型在汉译英翻译任务上的表现,以及横向比较当前主流大语言模型在汉译英翻译任务上的表现。实验的主要测试指标包括译文的准确性和译文的文学性。
本文选取当前国际主流的大语言模型ChatGPT 4.0,以及国内主流的大语言模型文心一言和讯飞星火。同时,本文还选取了Google翻译、百度翻译、有道翻译、DeepL四个传统在线翻译系统作为对比。
为全面测试各类翻译系统在各维度的表现,研究团队选择了金宇澄著的长篇小说《繁花》。该小说自2012年发表在《收获》 杂志后,多次获国家级重要奖项,是一部高质量的文学作品。本研究选取了《繁花》的第三章第三节,共计2755字。《繁花》的原文风格独特,多用短句、夹杂沪语,句式特征及篇章衔接本身具有可研究性。节选段落含有生活对话、人名、方言、诗句等,包含形式丰富的中文句式,将其作为源文可较为全面地测试大语言模型和传统翻译工具在翻译准确性和文学性方面的表现。
由于ChatGPT大语言模型设置了“ 温度” 指标,每次用不同的提示(Prompt) 会得到不同的结果,甚至每次用相同的提示,也会得到不同的结果。基于该特性,研究团队用不同的提示句对ChatGPT 4.0分别进行了三次翻译测试:第一次“请翻译以下文档” ,该次测试的译本以下简称ChatGPT 4.0-1;第二次“请你翻译得更详细些” ,该次测试的译本以下简称ChatGPT 4.0-2;第三次“ 假设你是位有经验的译员,你的任务是把中文小说翻译成英文,请翻译以下文字,译文忠实于原文且地道” ,该次测试的译本以下简称ChatGPT 4.0-3。
本研究采用业界的质量评估模式,基于MQM错误层级量表中的“准确度”指标对翻译结果进行了客观统计,并根据朱莉安·豪斯评估模式中的语义、语用和语篇维度对译文质量的文学性进行了等级评估。
本文从漏译、增译、错译三个维度对10个译本进行了对比分析。
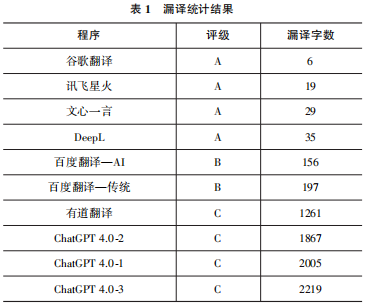
漏译体现了源文语义在译本中的缺失。本文采用量化方式,对漏译的原文字数进行了统计,根据统计结果将译文质量分为三个等级:A(漏译字数0~100)、B(漏译字数101~1000)、C(漏译字数1001~2500)。统计结果如表1所示。
仅有3类译本出现了增译现象:ChatGPT 4.0、DeepL和谷歌翻译。增译有两种类型:(1)自行增加源文中没有的内容。DeepL和谷歌翻译虽然是传统翻译软件,但仍会在翻译过程中自行增加源文中没有的内容。例如,谷歌翻译增译内容“I‘m not sure if I’m going to be able to do this, but I’m going to be able to do it”。这可能与传统翻译软件使用的训练语料有关:训练语料中可能存在与源文部分相似的文本,就将训练语料的所有译文作为源文的译文输出。(2)对源文内容进行了总结。不翻译源文,仅对相关内容进行总结的情况只存在于大语言模型ChatGPT 4.0中。其原因可能主要是在ChatGPT的训练语料中缺少源文,模型不会翻译,就对源文进行了总结概括来“交差”。以下为ChatGPT 4.0提供的译文。
ChatGPT 4.0-1增译部分: The narrative also touches on Yinfeng’s discomfort due to excessive breast milk, seeking help to alleviate her condition, hinting at the complex realities and intimate details of life within the community.
ChatGPT 4.0-2在最后做了总结:This detailed description of “Blossoms” Chapter Three, Section Three, offers a window into the everyday lives, interpersonal relationships, and societal norms of its characters, painting a vivid picture of their world through the lens of ordinary, yet profoundly meaningful, interactions and experiences.
ChatGPT 4.0-3提供的译本中显示: The excerpt ends with Xiaomao returning home, facing his mother’s wrath for his adventures and their bittersweet, complex relationship, highlighting the generational and personal struggles within this tightly knit community.
增译字数统计情况显示,ChatGPT 4.0-1增译单词数为31,ChatGPT 4.0-2增译单词数为101,ChatGPT 4.0-3增译的单词数为38,DeepL增译单词数为20,谷歌翻译增译单词数为6。
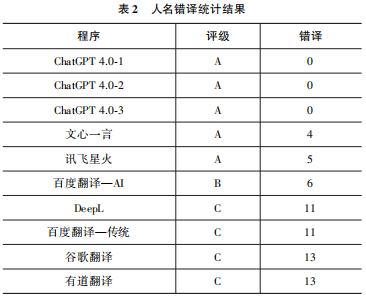
错译可分为以下三类:第一,人名前后翻译不一致。例如,在百度翻译—传统提供的译本中,主人公沪生的译名共出现Hu Sheng、Shanghai students、Shanghai residents、The Shanghai Student四种表述,在译文中随机使用。这主要是翻译系统为了体现其译文的文学性,对在文中不同位置出现的同一人名采用了不同的译文。本文将人名错译分为三个等级:A(错译数1~5)、B(错译数6~10)、C(错译数11~15),结果如表2。
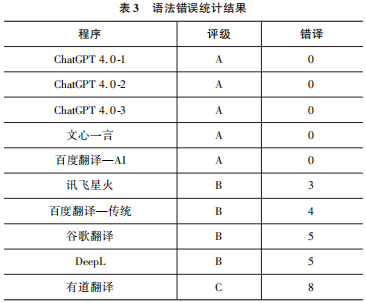
第二,语法错误。在传统翻译软件中,常见时态错乱的情况。例如,在DeepL译文中,“Husheng look at the door sign said”,同时使用一般现在时和一般过去时,前后时态不一致。这主要是由于译文存在一定的随机性。本文将语法错误分为三个等级:A( 错译数0~2)、B(错译数3~5)、C(错译数 6~8),结果如表3。
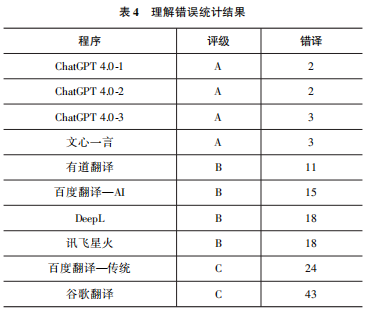
第三,对方言、俗语和诗歌的翻译理解错误。例如,源文中的人物小毛娘在与王师傅对话询问儿子小毛的行踪时,连续使用三句方言“到啦块去了” “啦个同学呢”“小赤佬,讲定不出门,脚头子又痒了,橄榄屁股坐不稳”。综合所有译本,仅有文心一言准确地理解了对话中的俗语、主语以及上下文逻辑关系,其他翻译系统在对语境与方言的分析上均理解错误。这表明文心一言在处理中文文本方面具有深厚的功底,其主要原因是比起其他大语言模型和传统翻译系统,文心一言拥有更高质量、更多数量的中英文平行文本作为训练语料。本文将理解错误分为三个等级:A(错译数0~10)、B(错译数11~20)、C(错译数21及以上),结果如表4。
从以上大语言模型在三个维度的综合表现来看,文心一言表现最佳;在传统翻译软件中,DeepL表现最佳。
《繁花》是一部具有深厚文学艺术价值的作品,拥有丰富的叙述内容,以细腻的笔触描绘了人物的情感和内心世界。作者运用了上海方言,为作品增添了浓厚的地方特色和文化韵味。
在评价译文文学性时,本文主要考虑了以下三个方面。(1)文字的可读性(语义);(2)对地方特色文化专有项和特色表达处理的到位程度(语用);(3)对特色写作手法的再现程度(语篇)。按文学性表现由好到差排序如表5所示。
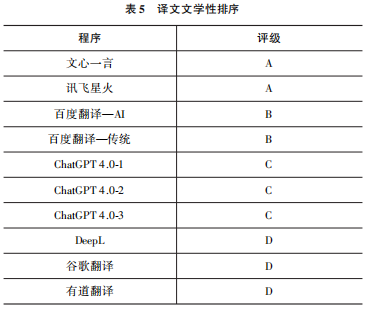
从可读性角度来看,译文在语言学意义上的正确性和连贯性是流畅阅读体验的基础。在这层意义上,D档译文普遍存在大量误译和漏译,译出部分可以观察到明显的字面翻译痕迹,基本上不具备文学性。其主要原因是DeepL、谷歌翻译和有道翻译都是传统的基于机器学习的翻译系统,对上下文长度的支持有限(在1000~5000字符,且包含标点符号)。而ChatGPT 4.0可接受的文字输入长度达到3.2万个Token,可支持约2.4万个单词的上下文。
此外,由于“文学性” 是一个很难精确衡量和准确量化的维度,是各类翻译系统共同面临的难题,如果再缺乏训练语料,传统翻译系统在“文学性” 方面的表现基本上都不佳。《繁花》的英文版截至目前尚未出版,现有的各翻译系统的训练语料中均无《 繁花》的中英文平行文本。因此,传统翻译软件在翻译《繁花》片 段时出现的大量字面翻译痕迹在情理之中。
在处理地方特色文化和特色表达时,各翻译系统普遍出现误译。这一现象与关于“理解错误” 的统计数据并不矛盾,ChatGPT 4.0在三种提示下虽出现较少“理解”问题,但其译文存在大量删节。在A、B、C档译文中,仅讯飞星火对上海特色美食“红烧百叶结”(braised louver knot)的翻译正确,其他译文或漏译,或将其处理为“面筋” (gluten) 或“豆腐皮” (bean curd skin)。上海里弄房屋特色的“老虎窗” (roof window/dormer)大多按字面直译为可能造成读者理解困难的tiger window,只有ChatGPT 4.0-3将其简化处理为window。上述问题都会影响读者体验文中所描述的生动上海。
在评价译文对原作特色写作手法的再现程度时,译文的完整性是重要考量指标,存在大量删减的三个ChatGPT译文尽管行文更流畅,用词也较恰当,但依旧只能排在C档。在三个ChatGPT译文中,采样片段描绘了一段生动场景:沪生和小毛走近苏州河,看到河上景象,沪生背诵了一首关于美景易逝的诗,两人就诗的作者产生了分歧,小毛表示“听不大懂”,各自“不响”。这个片段通过描绘环境和刻画人物内心,展现了人物的情感世界和对生活的不同态度。其中,沪语词“不响”(字面意思是“不说话”)在整部作品中出现1500次(金宇澄,2017)。执导电视剧版《繁花》的香港导演王家卫表示,“如果用一个词来形容《繁花》,必定是:‘不响’” (阙政,2024)。文学评论家许子东认为“不响”是属于上海人的“一句顶一万句”,体现了上海人精于世故的沉默、坚忍不拔的精神以及对现实生活的深刻理解和感悟(陈嫣婧,2024)。这些生动片段和人物刻画细节的保留对于再现作品的文学性非常重要。排名A、B两档的译文都保留了这些片段,其中两个百度翻译的译文表现较为接近,传统版翻译软件的译文更贴合原文,但连贯性略逊色,因此排名靠后。传统翻译软件译文连贯性不足的主要原因在于其以句子或段落为单位进行翻译,缺乏长文本语料,故译文的上下文之间缺乏关联。
位列A档的文心一言和讯飞星火对原文整体还原度都较高。语言文学性细节对比如表6所示。

文心一言在文学性方面的表现更为出色,它不仅在语言的选择上更为丰富和细腻,而且在情感和意境的传达上也更为深刻,更好地体现了原文的文学价值。其原因在于,海量的高质量中文语料保证了文心一言在中文表述上的准确性和生动性。然而,讯飞星火的译文也有简洁性和直接性的优势,特别是在强调流畅性和易读性的翻译情境中,这种优势更明显。这与讯飞星火的“基因”有关:科大讯飞是一家专业从事自然语言处理和专业机器翻译的公司,其翻译软件擅长外贸、医疗、金融、计算机、体育、法律、能源等专业领域的翻译,相比较文学性,讯飞星火的翻译更强调译文的准确性和简洁性。综合而言,文心一言更符合读者对文学语言的期待。
本研究选择了ChatGPT 4.0、文心一言和讯飞星火三个大语言模型以及Google翻译、百度翻译、DeepL、有道翻译四个传统翻译工具,分别对长篇小说《繁花》的第三章第三节进行了汉译英的翻译测试。结果显示,文心一言在翻译准确性的各项指标及译文的文学性方面均表现优异;讯飞星火除了对方言的理解稍逊色之外,其他各方面的表现也较为突出;ChatGPT在翻译的准确性上表现突出,但在文学性方面稍逊色,且会漏译大量源文;谷歌翻译和DeepL漏译字数较少,在其他指标项中均表现一般甚至垫底;百度翻译在各项指标中的表现均处于中间位置;有道翻译在各项指 标中的表现均居末位。综合来看,文心一言和讯飞星火这两个中文大语言模型在汉译英任务上的表现不仅超越了传统的国内外机器翻译系统,也优于当前业界公认的ChatGPT,其主要原因是文心一言和讯飞星火用于训练模型的语料和平行文本在数量和质量上都优于其他大语言模型,这也变相验证了训练语料的类型、数量和质量对大语言模型的重要性。
本研究选用了小说《繁花》中的部分文本测试大语言模型和传统翻译系统在汉译英任务上的表现,虽然选取的内容包含了形式丰富的中文句式和词汇,但从测试的样本量来看,仍略显不足。此外,本研究在测试大语言模型的表现时仅用了三种提示方法。因此,今后的研究可以从增加测试文本的类型和数量,以及改进提示词等方面开展。


赵衍,上海外国语大学信息技术中心
张慧,上海电机学院外国语学院
杨祎辰,上海外国语大学英语学院
文献来源|原载《外语电化教学》2024年第4期。推送已获作者授权,引用请以期刊版为准。
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
