
1、BLEU评价指标|Bilingual Evaluation Understudy
《中国大百科全书》(第三版·网络版)发布了张家俊教授撰写的“BLEU评价指标”词条。现转录如下,以资交流。
机器翻译研究者经常会被问到这样一个问题:现在的机器翻译系统译文质量如何?这是一个简单却又很难回答的问题。相对于其他自然语言处理任务,如语音识别,机器翻译任务一般不存在标准答案。只要语义一致,一个源语言句子可以对应多个正确的目标语言译文。如何评价机器翻译系统的译文质量成为至关重要的问题。人工评价是最简单的一种方法。对于某个机器翻译系统输出的译文,聘请专家逐个查看每个译文,评判其正确性。由于“正确性”是一个大过宽泛的概念,通常在人工评测中使用忠实度和流利度作为判新标准。忠实度衡量译文传达了原文意思的程度,保留了原文多少信息,相当于“信、达、雅”中的“信”;流利度则衡量译文是否流畅通顺,是否符合目标语言的表达,相当于“信、达、雅”中的“达”。然而,人工评测不仅成本昂贵,而且效率很低。研究者经常在设计新的机器翻译算法后希望立刻检验该算法的有效性,人工评价就很难满足这种需求。因此,自动评价是一种理想的方案。
2002年,IBM的K.怕尼内尼(Kishore Papineni) 等人提出了一种机器翻译译文质量的自动评价方法BLEU。BLEU评价指标的原理是:如果机器翻译系统的译文越接近专业译员的翻译结果,那么该机器翻译系统的效果越好。一般地,对于包含若干测试用例(源语言句子)的测试集,首先请一个或多个专业译员将测试用例翻译为目标语言译文。每个测试用例将对应一个或多个工参考译文。BLEU评价指标就是通过计算机器翻译系统的译文与人工参考译文的匹配程度,来度量机器翻译系统的性能。其计算方法大致可描述为:首先,计算机器翻译译文与人工参考译文之n元组(通常取n = 4)的配数目占机器翻译译文所有n元词组总数的比率;然后,对所有n元词组的匹配率取几何平均。为了防止长度过短的机器译文获得较高的BLEU值,通常在几何平均的基础上增加一个长度惩罚因子,从而得到最终的BLEU值。计算公式如下:
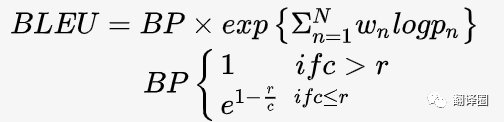
其中,1元词组的匹配率可以反映机器译文的忠实度,而2元到4元词组的匹配率能够一定程度地衡量机器译文的流利度BLEU是使用最广泛的自动评测指标,由于其简洁、可靠,被各机器翻译评测组织用作译文质量的官方评价指标,极大地推动了机器翻译研究的发展进程。而且,很多学者通过研究发现BLEU评价指标与人工评价具有很高的一致性。
2、作者简介
张家俊,中国科学院自动化研究所,研究员,中国科学院大学, 岗位教授。
专利成果:1. 一种基于谓词论元结构的统计机器翻译方法, 发明, 2015, 第 3 作者;2. 一种基于模糊树到精确树的统计机器翻译方法, 发明, 2016, 第 2 作者, 专利号: CN102117270B。研究领域:机器翻译、自然语言处理、跨语言文本分析。
3、文献来源
原文发表于《中国大百科全书》第三版网络版,欢迎各位学者阅读、分享。
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
– END –
转载来源:《中国大百科全书》(第三版网络版)
转载编辑:张一孟
