
无论是在平常的翻译练习还是在学术研究中,语料库作为学习工具或是研究方法都不可或缺。那么,在做基于语料库方法的研究时应该如何建立自己的语料库呢?看完这篇,一定能对你有所启发!
语料库一词译自英文“corpus(复数常用corpora)。
语料库语言学家辛克莱将其定义为“按照一定的采样标准采集而来的、能够代表一种语言或某语言的一种变体或文类的电子文本”。
语料通常都会以txt格式保存。
如果是书面语料,需要先扫描将其转成电子版,然后通过OCR识别,再自行校对和格式转换;
如果是语音语料,则需要首先进行转写,再进行后续步骤;
而如果已经是电子语料(如pdf,mobi,html等)则直接进行格式转换即可。
OCR识别工具推荐:ABBYYFineReader2,天若文字识别,Adobe Acrobat Pro DC等。
格式转换工具推荐:Adobe Acrobat Pro DC,或网站Aconvert,iLovePDF,Convertio等。
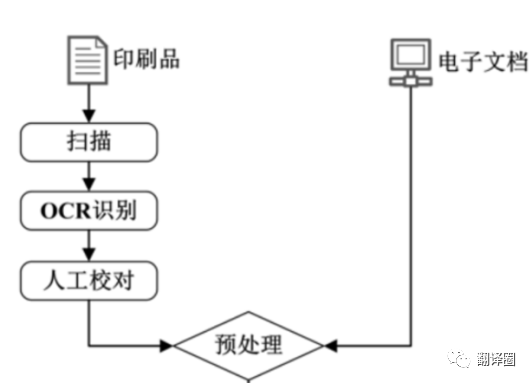
接下来就是语料的预处理,对语料进行校对降噪。
在这个过程中,我们需要把整理好的文本中多余的空格、空行、回车、乱码、错别字、以及其他不需要的信息(包括附录,表格,前言等)都去除掉。
推荐工具:MS Word和EmEditor(网址https://www.emeditor.com/)
P.S.在语料清洗的过程中,正则表达式是一个好帮手,在一些语料清洗工具中也提供了快捷键,不需要手动输入正则表达式,且能满足不少读者的需要。小编在这里附上示例表:

感兴趣的小伙伴可以在网址https://www.runoob.com/regexp/regexp-tutorial.html进行了解和学习~
首先请大家了解一下:
分词(tokenization)是指将一串字符转换成可以分析,容易识别的形符(token)——也就是词语——的过程;
标注(annotation)是指将文本中的词语按照各种属性(part of speech)进行标注;
但是请注意,对于汉语来说,分词是必须的,因为汉语的词语之间没有明显分隔,不进行分词的话难以识别分析;而标注不是必需步骤,在有需要时进行即可。
举个例子:
分词前

分词后

标注后

分词标注工具推荐:TreeTagger,CorpuswordParser(汉语),StanfordParser(英汉)等
以上工具都可以在http://corpus.bfsu.edu.cn/TOOLS.htm进行下载

截止以上前三步,语料的加工基本已经完成,但如果你的语料是双语或多语,则需要对其进行对齐处理。
对齐是指将多语言语料实现句子的一一对应,也可以实现段落的一一对应,以形成规范的语对。
对齐推荐工具:memoQ,Tmxmall等
对齐完成后如图:

此图出自于上海外国语大学语料库研究院的《习近平谈治国理政》多语数据库综合平台
完成以上步骤就完成了对语料的处理和加工,成功建立了语料库!
语料库建成后,小编在这里推荐两个常用的语料库检索分析工具:Antconc和Wordsmith。这两个软件可以帮助大家更好地对语料进行检索,生成词表等,是语料库人不离手的好工具!
此外,除了自建语料库,大家也要利用好现有的语料库,如:
英国国家语料库(British National Corpus,简称BNC)
http://www.natcorp.ox.ac.uk/
美国当代英语语料库(Corpus of Contemporary American English,简称COCA)
https://www.english-corpora.org/
SketchEngine
https://www.sketchengine.co.uk/
… …
以上就是本期全部内容啦,希望这篇文章可以在你探索语料库建立的途中提供一些帮助~
实践出真知,快去动手试试吧~
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
翻译圈公众号旨在为读者提供名师和专家对口笔译的真知灼见,CATTI考试和MTI入学考试信息,翻译等语言服务就业资讯,以及口笔译学习资源和知识,希望在翻译之路上,为大家助上一臂之力。欢迎大家积极留言,为我们提供建设性意见,我们共同进步!
原文作者:张一孟
