前言
传统的计算机辅助翻译工具有三大核心技术用于辅助译者提升翻译效率和翻译质量,分别是:术语、翻译记忆和机器翻译。
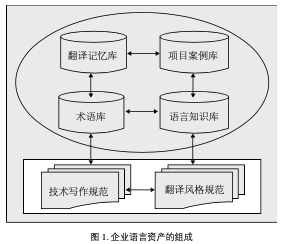
崔启亮老师曾经梳理过企业内部的语言资产形态,如下:
最近行业内有关GPT的各种讨论都对GPT对机器翻译的影响、技术写作的影响、翻译教育的影响等多有讨论,但“翻译记忆”这个计算机辅助翻译技术的核心鲜有讨论。
我认为,以GPT为代表的大语言模型技术是对计算机辅助翻译工具内置翻译记忆技术的彻底颠覆。
在简言微信公众号之前的文章中大家可以查看我写的一系列与翻译记忆原理相关的文章,翻译记忆之所以能够提高效率是因为译者在翻译过程中可以基于过去翻译的双语数据来翻译形式上相似的新句子。
注意,这里我特别指出了“形式”相似,因为无论是衡量字符串相似度的模糊匹配还是衡量机器翻译质量的BLEU都是形式上相似,我在之前的文章中介绍原理时都详细分析过。
但GPT的出现,则通过词嵌入(Embedding)技术将相似度的计算从形式层面带到了语义层面。为了证实这一点,我在ParaTrans上添加了“记忆”模块。
视频展示
正文
一、翻译记忆的对齐与上传
目前国内外翻译记忆在线对齐工具中,TMXmall做得应该是最好的:

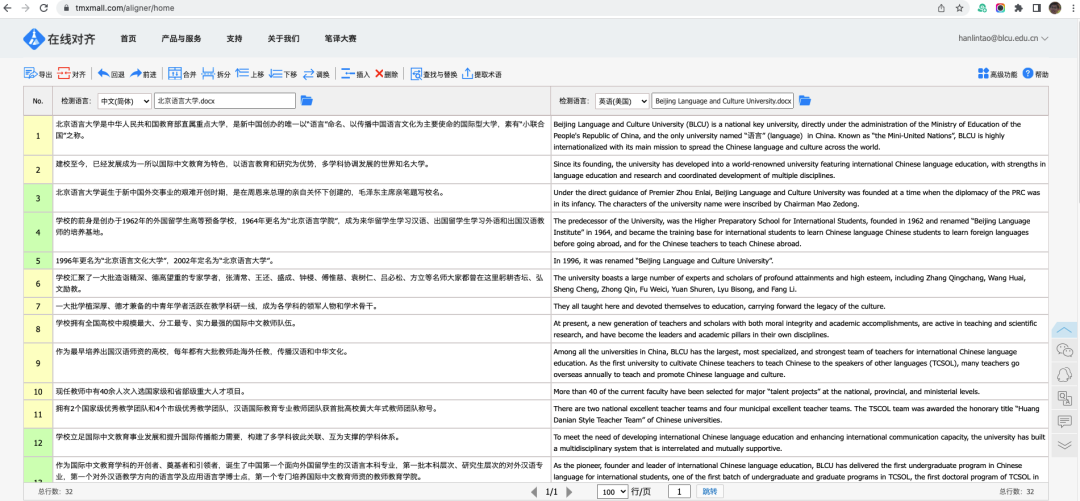
离线对齐工具可以选择Abbyy Aligner。
在B站上有这两款工具详细的教程,本文就不再介绍了。《译者编程入门指南》一书中也有相关章节具体分析。
双语文本对齐后生成的tmx格式文件就是翻译记忆。
通过ParaTrans可以将tmx格式的翻译记忆上传到后台:

二、语义计算
翻译记忆上传后需要使用GPT的Embedding API进行语义计算:
GPT的Embedding API是一个非常简单的API:
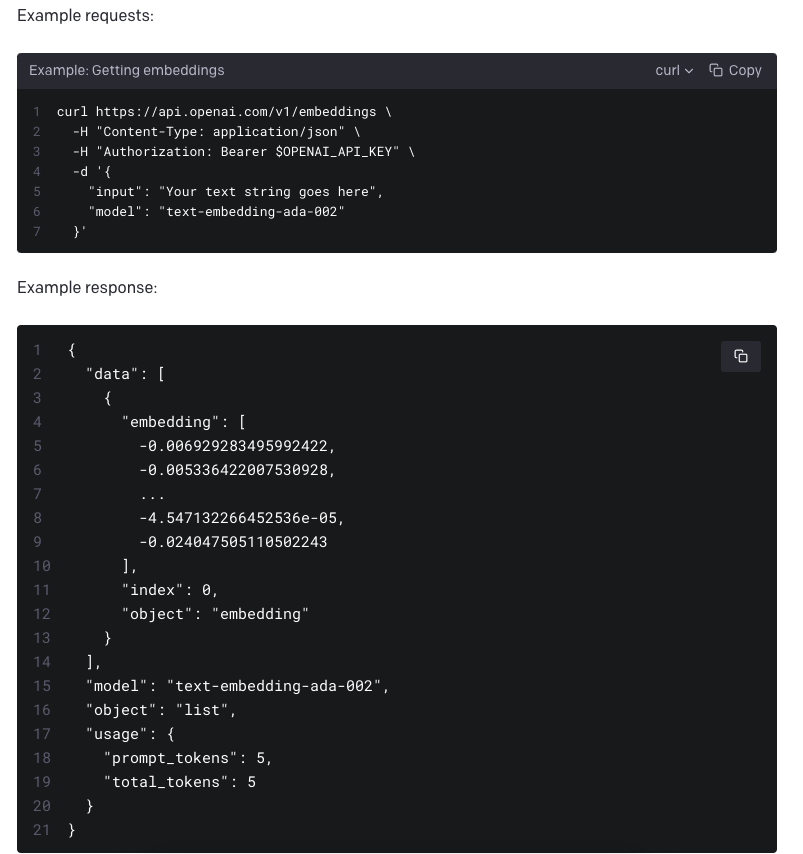
在实际工程处理中,只需要几行代码就可以获得一个中文或英文句子的词嵌入数据,并可以方便存储到数据库中:

三、记忆问答
当用户向记忆库发出问题时,GPT是如何给出智能答案的呢?
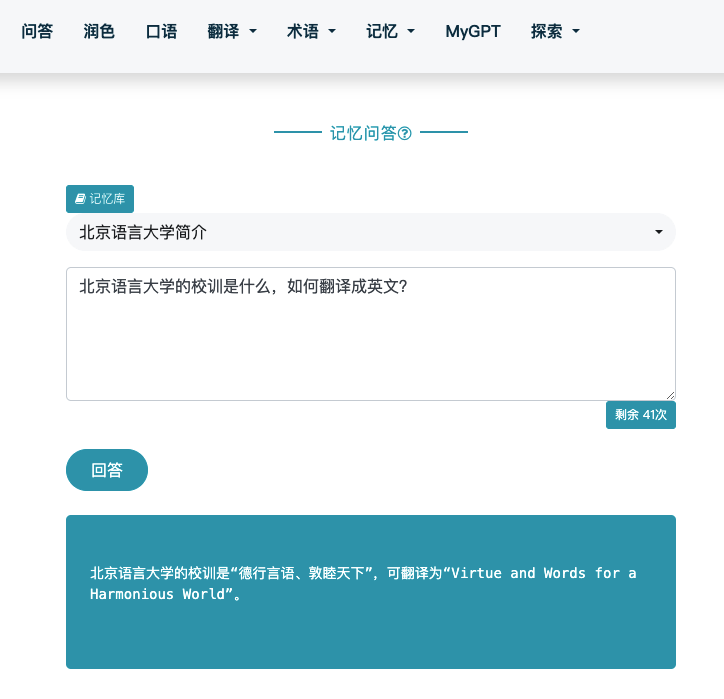
首先,当用户发出一个问题后,GPT会计算用户的问题的Embedding,即一串数字,然后使用这串数字和数据表中也有的每个翻译记忆的中文和英文文本的Embedding进行相似度计算,这个计算的过程只需要几行代码,效率非常高:

在得到了几个相似度非常高的双语文本后,把这些双语文本作为Prompt的一部分连同之前的问题拼接在一起,送给GPT:

然后GPT就可以给出智能的答案了。
结语
我在最近的几次讲座中多次提到:不要仅仅使用ChatGPT中的问答数据来判断GPT对翻译教育、翻译实践和翻译研究的价值,而是要真正的去理解GPT API的价值,基于GPT 的API来设计和研发服务于译者的新一代计算机辅助翻译工具。
2018年我在简言里写过这样一段话:
“只要你会一些基本的编程知识,你就能开始运用这些免费的自然语言处理技术做出对自己的学习、工作和研究有帮助的小工具。
不知道大家有没有听说过“AI 民主化”(Democratizing AI)这个概念,在未来的几年里越来越多的文科专业学生也将掌握编程知识,如果能够充分利用市面上的开源或免费的(哪怕是付费的)人工智能技术,那么大家将会看到一大堆有创意有价值的办公工具和研究工具,为我们的生活赋能。
不光百度在做这样的有价值的事,腾讯、阿里、谷歌等一大批互联网公司都在不断开放自己的人工智能服务,让更多人可以通过极为简单的方法应用人工智能技术。
我相信这是未来技术发展的趋势。”
在前几天中国翻译协会年会的分论坛上我也这样说过:

如果未来的译者能够学会如何调用人工智能技术的API,那么一定可以有更多丰富的翻译技术创意产品。
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。
转载来源:简言
转载编辑:周琳
