IERC公众号全新版块——“IS下午茶”
#形式
每月一次的学术论文分享
IS, short for Interpreting Studies
#内容
像分享下午茶小点般
为你送上最有意思的口译研究文献推荐
在这里
有最经典的学术著作
有最前沿的研究工作
还有书海拾贝的论文研读
欢迎来到IS下午茶
口译研究超好玩!
欢迎大家到文末留言区讨论交流~

IS下午茶 · 第23篇
○
最近在网络媒体上引发热议的AI聊天程序ChatGPT又一次将大众的目光吸引到了人工智能上,惊叹人工智能的飞速发展。在翻译领域,人工智能即将替代人类译员的声音更是不绝于耳,但事实真的如此吗?今天这杯下午茶就让我们来品一品一本有关口译员和人工智能的书。
书本简介
这本书名为Interpreters vs Machines: Can Interpreters Survive in an AI-Dominated World?,2019年出版,作者是咨询口译员兼研究员Jonathan Downie博士。

图1. 书本封面
首先让我们看看整本书都在讲些啥。
全书分为5个部分,共14章。
第一部分依次探讨了什么是口译、人如何口译、计算机如何“口译”。
第二部分讲述了口译如何成为一种职业,而如今又如何在机器口译面前日渐失去上风。口译员的公共关系、自我营销方式、机器口译提供商所宣传的主张和益处都在这一部分得到呈现。
在第三部分,作者没有直接给出自己对于口译未来走向的看法,而是展示了多种可能,让读者来选择。第6章——待机器口译发展完备之时,终将替代人类译员。第7章——通过健全的法律保障,人类译员还是可以保住自己的饭碗。第8章——人类译员被限制在少数几个领域。第9章——口译新未来:人类口译成为质量标准。
第四部分指出,如果人类口译要成为未来口译行业的标准,口译员就需要改变自我宣传、营销和完成口译工作的方式。
最后一部分提出了问题——当我们决心争取人类口译的未来时,我们是否会错过一个皆大欢喜的结局?
以上就是这本书的全貌。现在让我们切换近景,仔细了解一下计算机如何“口译”。
机器口译
该书作者指出,在了解机器口译的工作原理之前,我们需要先理解其背后的假设,即口译是一个序列到另一个序列的通道模型问题。

简单来说就是,机器口译开发人员认为口译是理解一个语言组块,然后在一种新的语言中,创造一个能够表达相同意义的语言组块。
作者认为,这种看法忽视了一种语言使用的社会语境、使用该语言的原因和使用该语言的人群。例如,英文中的第二人称代词只有you,当目的语的第二人称代词根据正式程度、复数形式或社会地位的不同而有多种表达时,人类译员会根据当下的社交需求,选择最合适的代词进行口译,而机器则受制于数据库,数据库有啥翻啥。
所以该书作者指出,将机器口译视为带有音频的机器翻译并不为过,当前的机器口译或许应该被称为“语音翻译(speech translation)”。至少在现阶段,机器口译或语音翻译应当被视为机器翻译的子集。无论一个系统的语音识别有多么强大,合成的声音有多么自然,语音翻译的质量上限都取决于所使用的机翻引擎的能力。因此在这一章,作者着重介绍了机器翻译的原理和发展历程。
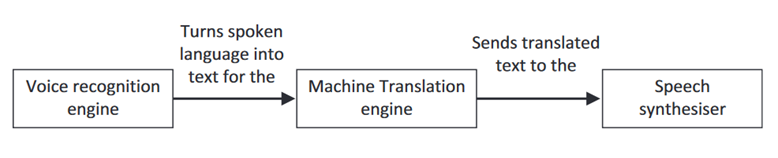
图3. 机器口译基本操作模型(Jonathan, 2019: 37)
第一阶段:语音识别
作者指出,要想获得最好的语音识别效果,需要有一个最佳的环境,在该环境中用语音识别系统熟悉的语言发言。否则,语音识别软件很可能“cannae git whit ah’m yabberin’ aboot”(苏格兰口音,实际是“cannot understand what I am talking about”)。

相应地,提升语音识别系统性能就需要不断收集关于“特定地区的口音、口语、习语”的数据。这一点很有可能借助Alexa和Siri这样的语音助手实现。
除此之外,语音识别系统还存在另一个bug。那就是当前的语音识别系统仅能识别字词,无法识别语调、重读和语气这样的副语言信息。
在一些语言中,这些细节可能无关紧要,但在像英语这样的语言中,这些细节至关重要。例如“I only told her I loved her”,重读的词不同,意思也会发生变化。在法庭、谈判及咨询等场景中,这些细微的差别可能还关乎成败。
当语言发生变化,语音识别系统也需要再次训练。作者认为除非有预测性算法可以用于语音识别,否则语音识别会永远滞后于语言使用。
现在,假设一个人的口音、语言表达都能为语音识别系统识别,且没有任何语调,那么我们就来到了机器口译的重头戏——机器翻译。
第二阶段:机器翻译
作者提出,了解机器翻译,首先需要了解其工作原理和质量评价方式。
当前有三种实现机器翻译的方法:
?1.基于规则的机器翻译(Rules-Based Machine Translation, RBMT)。
原理:
· 程序员和语言学家一同为每一种语言制定规则,如词性、词法、句法等。
· 规则与双语词汇表结合。
具体过程:
RBMT系统先根据规则分析源语文本中的每一句话,然后完成每一个词的词根和每一个语法结构的翻译,最后改正存在的错误。
优点:
利用语言学家的专业优势,完成一种语言的解构和另一种语言的建构。
缺点:
· 光是建立起规则还不足以实现准确翻译。
· 人使用语言时常常打破语言学家书写的语言规则,当语言使用发生变化,RBMT系统也需要得到调整。也就是说,规则和实际语言使用之间存在差异。
· RBMT系统难以处理习语和歧义。
?2.由于这些缺陷以及处理器和存储技术的发展,机器翻译领域迎来了统计机器翻译(Statistical Machine Translation, SMT)。
原理:
· 收集大量双语平行语料和目的语单语语料训练SMT系统。
· SMT系统借助统计概率和数学符号,计算出不同翻译结果的概率,最后产出概率最大的译文。
举例:
假设有一个庞大的法英双语平行语料库,对于“Marie est une femme”这句法语,这个语料库中有1000条这句话的英语译文,其中999条都译为“Mary is a woman”,只有1条是“Mary is a lady”。那么SMT引擎就会由此推断,下一次见到“Marie est une femme”这句话时,它很有可能需要将其译为“Mary is a woman”。
优点:
· 不需要人编写规则。
· 当用来训练SMT系统的语料库库容够大、涵盖语言对够多、语言质量够好时,SMT产出的译文质量会很不错。
· 一些组织机构常常需要翻译许多语言表达相似的文件,此时就可以使用SMT替代人的重复工作。
缺点:
· SMT非常依赖预测和高频率词组,用于机器口译时,口语的创造性、无序性和多样性会成为一个难点。
· SMT缺乏文化意识和百科知识。
· SMT无法解读译文的意义或语气。
· SMT产出译文的清晰程度和质量极其依赖其系统内现有数据的质量。
?3.2015年以来,基于机器学习的神经机器翻译(Neural Machine Translation, NMT)方法兴起,给机器翻译领域带来了新变革。
从广义上讲,NMT是一种基于人工神经网络的方法,它把翻译过程描述为可以用人工神经网络表示的函数,所有的训练和推断都在这些函数上进行(肖桐,朱靖波,2021:331)。
作者认为要了解NMT,首先需要了解机器学习(machine learning)。
那么啥是机器学习?
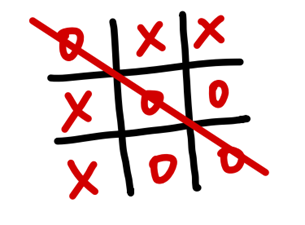
图4. 井字棋示意图

图5. 井字棋“机器”(图源Wikipedia)
准备9种颜色的珠子若干,不同颜色的珠子代表了在3×3棋面上的位置。准备304个火柴盒,在每个火柴盒上写上一种3×3的棋局,每个盒子表示一种不同的棋局,每个盒子里再放一些颜色各异的珠子。
首先放一个空棋盘在桌上,操作者找出代表空棋盘的火柴盒并摇晃它,从中随机抽取出一颗珠子,按照珠子颜色代表的位置开始走棋。在对手走了一步后,操作者又找出写有相同棋局的火柴盒,摇晃盒子,随机取出一颗珠子,按照珠子的颜色又走一步。然后不断重复该过程直至该局结束。
如果代表“机器”的操作者输了,棋面上的珠子就留在火柴盒外(可视为一种惩罚),减少再次出现失败棋局的概率。
如果代表“机器”的操作者赢了,“机器”走的每一步的珠子的数量会乘以3,依次放回原来的盒子(可视为一种奖励)。
如果是平局,珠子会被一一放回原来的盒子里,不增也不减。
这样一来,因为赢了之后珠子增多,这个“机器”就能“学会”下出更好的棋;反之,输了之后珠子减少,“机器”就能“学会”减少下错棋。关键点就在于,一次棋局的结果可以立即影响后面的棋局,从而提升表现。
所以,机器学习指的是一个系统通过学习过往任务的结果,更好地完成未来具体任务的能力。相应地,基于机器学习的NMT可以提升机器翻译的表现。
那么NMT的工作原理到底是什么呢?
提升表现是机器学习的功劳,
那么NMT又是如何发现并使用新规律的呢?
小结
第三阶段:语音合成
总结
作者认为,整体来看,这几个环节融合在一起已经可以完成口译任务了,但因各个环节存在的不足,机器口译应用于现实生活的效果并不理想。机器口译最大的困难不是理解语言,而是将语言和语境联系起来。在口译时,人类译员不仅可以理解发言人在说些什么,还知道发言人在对谁说,发言人为什么这样说,发言人如何说,发言人的目的是什么,而机器口译则很可能识别不出这些细微但关键的线索。所以作者总结道,机器口译的问题不在于语言,而在于人。
专栏手记

在讨论和应对AI给口译行业带来的影响和冲击前,我们或许要先做到“知己知彼”。对于大多数职业译员、学生译员和口译研究者而言,“知己”这一方面可能无需多言,每个人都对口译的过程有所了解或有自己的见解。但“知彼”呢,我们对基于AI的机器口译又了解多少?
这本书就为想要了解口译与AI但又苦于不懂复杂数理概念的人提供了一个入门的机会。作者在书中常常穿插自己的口译经历,解释复杂概念时往往也使用了一些生活化的例子,读起来相对简单。但也正因为是入门级的书籍,这本书对于一些概念解释得并不细致,比如机器翻译的三种方法实际上还可以进一步细分。作者在讨论机器翻译方法的优缺点时,也更侧重产出的译文,较少从技术更迭的角度做出评价。
最后,如同作者所言,“在读这本书时,最重要的是我们要意识到,无论我们从新闻报道或社交媒体上读到什么内容,口译的未来始终掌握在译员的手中”,与其终日被质疑或自我怀疑,不如先打破迷思。
品鉴文献:
Downie, J. (2019). Interpreters Vs Machines: Can Interpreters Survive in an AI-dominated World?. Routledge.
参考文献:
肖桐,朱靖波. (2021). 机器翻译:基础与模型. 电子工业出版社.
推荐观看:
https://www.3blue1brown.com/topics/neural-networks
https://www.youtube.com/watch?v=G-di38Fpgdw
总审核 | 许艺
校对丨侯臻柔
专栏作者 | 谭诗忆
排版丨曾韵双
特别说明:本文仅用于学术交流,如有侵权请后台联系小编删除。(日常转载文章)
转载来源:广外高翻 口译教育与研究中心
转载编辑:陈柯淼
