
规则-based 方法是自然语言处理领域中的一种常见方法和技术,可以追溯到早期的计算机科学和人工智能研究。 早期的规则-based方法主要基于人工编写的规则和知识库,例如语法、词典、语义网络等,用于处理语言和知识的表示和推理。这些方法在一些特定任务中表现出色,如语音识别、机器翻译等。 在规则-based方法的基础上,逐渐发展出了一系列相关技术和方法,如关键词匹配、正则表达式、句法分析、语义角色标注、信息提取等。
规则-based 方法指的是基于语言学知识和规则的方式进行翻译。
该方法认为翻译是一种基于语法、词汇和句法等规则的过程,并且这些规则由专家手动编写。
通常包括以下几个步骤:
1. 规则定义
首先需要定义一系列规则,这些规则描述了输入与输出之间的对应关系。
2. 信息提取
在这一步骤中,需要从输入文本中提取出所需的信息。
3. 解析与处理
根据规则和语法对输入进行解析和处理。
4. 输出生成
根据解析和处理的结果,按照预定的规则和格式生成输出。
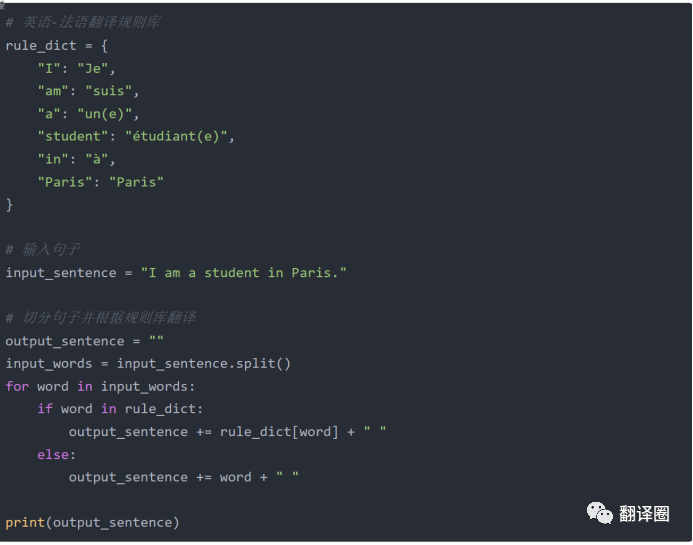
以下是一个简单的规则-based 方法的示例代码,用于将英语中的简单句翻译成法语。
当涉及英语-中文的规则-based方法时,实现起来更加复杂。
因为英语和中文之间的语法结构和词汇差异很大。
以下是一个简单的示例代码:
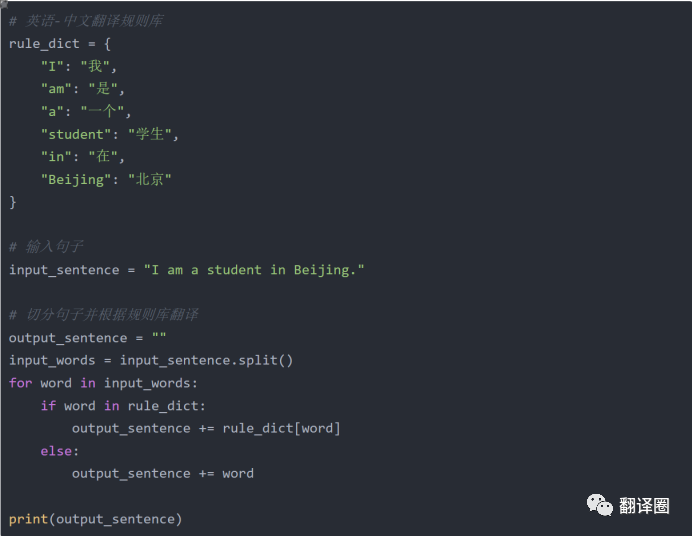
上述两个代码首先定义了一个规则库,包含一些基本的翻译规则。程序将输入句子分割成单词,并根据规则库进行翻译。最终输出翻译结果。
虽然规则-based 方法的思路直观简单,但是其效果有限。
1. 长难句、歧义和多义等复杂情况下,翻译质量难以保证。
2. 语言之间存在很多的差异和变化,规则-based 方法也很难完美地覆盖所有情况。
3. 规则-based 方法需要大量的人力和时间来构建和维护规则库,
4. 需要不同的规则库来处理不同的语言对。
尽管规则-based方法的灵活性和泛化能力相对较弱,但在一些特定的场景和任务中,它们仍然是一个有用的工具。如:
1. 机器翻译中的后处理:在统计机器翻译系统中,规则-based方法被用于后处理阶段,通过定义规则来修正翻译的错误或改进翻译的准确性。
2. 专业领域的应用:在某些特定的领域和任务中,由于领域知识的丰富和约束条件的明确,规则-based方法可以更好地满足需求。例如,在法律领域的文本分析中,规则-based方法可以用于检测和提取法律条款。
代码可在CSDN查看
https://blog.csdn.net/weixin_47412550/article/details/133661785?utm_source=miniapp_weixin
特别说明:本文仅供学习交流,如有不妥欢迎后台联系小编。
– END –
翻译圈公众号旨在为读者提供名师和专家对口笔译的真知灼见,CATTI考试和MTI入学考试信息,翻译等语言服务就业资讯,以及口笔译学习资源和知识,希望在翻译之路上,为大家助上一臂之力。欢迎大家积极留言,为我们提供建设性意见,我们共同进步!
原文作者:张子明
推文编辑:刘柏君
