文本挖掘趋势 #
原先:70%精力获取语料、建库,30%解读数据
现在:懂得Python或R语言之后,能更为深入,例如:词向量训练、命名实体识别、情感分类
语料采集 #
自动采集工具 #
八爪鱼采集器、Teleport Ultra、TextForever、火车头采集器、后裔采集器、集搜客采集器、Python
手动采集方式 #
单篇文本的复制粘贴
批量文本处理与转换
文本处理(OCR)
ABBYY FineReader、Adobe Acrobat Pro DC、Nitro Pro、天若文字识别
格式转换
批量校对
酷库、GenAI辅助
语料清洗 #
通常需要清洗哪些内容? #
语料清洗的具体步骤和需要清洗的内容可能会根据研究的目标和语料的类型而变化。
去除无关内容: 这包括去除广告、页眉页脚、导航链接、HTML标签等在分析中不需要的内容。
去除重复内容: 这可能包括完全相同的句子或者段落,也可能包括在不同的上下文中重复出现的内容。
标准化文本:这可能包括将所有的文本转换为小写,去除或替换特殊字符(如*/#),将数字转换为一种标准形式等。
分词和词形还原: 将文本分割为单词或短语,然后将词形还原到它们的基本形式。
去除停用词: 删除如”的”,”和”,”是”等常见但对分析帮助不大的词。通过加载停用此表,例如文本中数字。中文目前可参考哈工大发表的停用词表,较为权威、全面。
处理错误的语法和拼写: 这可能包括使用拼写检查工具来纠正拼写错误,或使用语法检查工具来纠正语法错误。
在进行语料清洗时,有哪些注意事项? #
保持一致性:确保所有的清洗步骤在整个语料库中都被一致地应用。这是为了保证最后的分析结果是基于同样的基础数据。
保持可逆性: 在清洗数据的时候,尽量保留原始的数据,以便在需要的时候可以回溯到清洗前的状态。这也可以帮助你检查清洗步骤是否正确。
考虑分析的目标: 清洗的目标应该是为了更好地进行分析,所以清洗的步骤和方法应该根据分析的目标来确定。例如,如果分析的目标是理解用户的情感,那么可能需要保留表达情感的词汇,即使它们是停用词。
探索性数据分析 (EDA):在清洗之前和之后,都应该对数据进行一些基本的探索性数据分析,以了解数据的分布、异常值等信息。这可以帮助你确定清洗的效果,以及是否需要进行进一步的清洗。
国内外有哪些好用的语料清洗工具? #
Python自然语言处理库 #
NLTK_(NaturalLanguage Toolkit) : 这是一种非常流行的自然语言处理库,可以用于语言建模、分类、分词、词干提取、标记化等。
spaCy: 这是一个工业级别的自然语言处理库,包含了预训练的统计模型和词向量,可以用于命名实体识别、词性标注、依存关系解析等。
Gensim: 这个库主要用于主题建模和文档相似性分析,但也包含了一些基本的文本清洗功能,如去除停用词和标点符号。
Pandas: 这是一个用于数据处理和分析的Python库,包含了各种数据清洗和处理功能,如处理缺失数据、删除重复行、类型转换等
TextBlob: 这是一个Python库,用于处理文本数据,它提供了简单的API来进行词形还原拼写纠正、翻译等任务。
R #
R是一种用于统计计算和图形的编程语言,它的数据清洗和处理功能非常强大。R中的tidyverse包含了一系列用于数据科学的工具,包括dplyr (数据处理),ggplot2 (数据可视,等等。此外,tm和quanteda等包可以用于文本挖掘和语料清化),tidyr (数据整)洗。
MS Word文档清洗文本技巧 #
例如:将清洗好的语料转换成表格,并单独提取中英文
库酷 #
EmEditor #
Notepad++ #
语料标注 #
常见的标注内容有哪些? #
标注的内容取决于研究的目标和方法。
词性标注 (Part-of-speech tagging,pos tagging): 对文本中的每个词语进行词性标注,例如名词、动词、形容词等。工
命名实体识别 (Named Entity Recognition,NER): 识别文本中的命名实体,例如人名、地名、机构名等。
命名实体识别标注工具推荐:
l Brat
l Doccano:Doccano 是一个开源的文本标注工具,支持多种标注任务,包括命名实体识别、文本分类、序列标注等。它也提供了一个直观的用户界面,支持多人协作。
l Prodigy:Prodigy 是由 spaCy开发团队开发的一个商业标注工具。它支持命名实体识别、文本分类等多种标注任务,并且可以很好地集成到 spaCy的工作流程中。Dataturks: Dataturks 是一个基于云的标注工具,支持命名实体识别、图像标注等多种标注任务。它提供了一个直观的用户界面,支持多人协作,并且可以直接生成可以用于训练模型的数据。
l Labelbox:Labelbox 是一个全面的标注平台,支持文本、图像和视频等多种类型的数据。它提供了丰富的功能,包括协作工具、质量控制工具以及 API,可以帮助你更有效地进行标注工作。
l LightTag:LightTag 是一个专注于文本数据的标注工具,支持命名实体识别、文本分类等多种标注任务。它提供了一个直观的用户界面,支持多人协作,和自动标注功能。
句法分析 (Syntactic Analysis) : 标注文本的法结构,例如主谓宾结构、状语位置等。
情感标注 (Sentiment Annotation) : 标注文本的情感倾向,并非简单的判断积极、消极,而是判断主观性、极性。
语义角色标注 (Semantic Role Labeling,SRL) : 标注子中的语义角色,例如施事者、受事者等。
此外,还有语篇背景信息、语篇结构的标注。
在进行语料标注时,有哪些注意事项? #
清晰的标注规范:一个明确、一致的标注规则是非常重要的。所有的标注者都应该按照同-套规范进行标注,以保证标注结果的一致性。
质量控制和检查:定期进行质量检查和双盲标注,可以发现并纠正标注错误,提高标注质量。
考虑语境: 语言是上下文依赖的,所以在标注时,需要考虑到词语的上下文语境。同一个词在不同的上下文中可能有不同的词性或语义。
处理歧义: 许多词语和句子都有歧义,标注时需要根据上下文和常识来解决歧义
保持更新: 语言是不断变化的,所以标注规范和工具也需要随着语言的变化进行更新。
足够的训练: 标注者需要经过充分的训练,理解和掌握标注规则,以保证标注质量。
常见的分词赋码路径 #
现有工具进行分词/赋码 #
可在北外语料库语言学网站下载:https://corpus.bfsu.edu.cn/
CorpusWordParser (肖航汉语分词/赋码)
BFSU Stanford POS Tagger 1.0 (词性标注
BFSU Stanford Parser (分词 dependency)
Stanford POS Tagger 4.2.0 (词性标注,Package) –需要Java环境Stanford Parser 4.2.0 (分词,Package) –需要Java环境
GenAI辅助的中英文分词/赋码 #
轻松使用Python和R进行文本多元化处理与分析
词性标注Python代码:
第一段英文标注、第二段中文标注
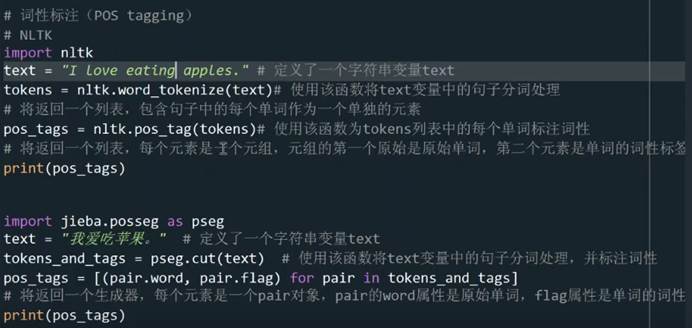
命名实体识别代码:

Q1:我的语料一般都是经OCR处理得到的,存在的问题有很多,清理十分费劲,基本全都是靠人工,这种有什么好的办法吗?
A:可以运用word, notepad++进行批量处理。例如英文中字符杂乱,可以使用这两个批量处理。或者使用ChatGPT等GenAI工具进行。在处理大批量文本时,制作自己的宏命令。
Q2:小语种例如韩语,如何处理?
A:
Q3:如果用LancsBox做语料分析是不是不用做分词赋码这一步呀?它自带的POS分析效果怎么样?
A:如果语料足够干净,效果值得推荐。
Q4:如果是想从文本中提取文化负载词,可以用Python提取吗?
A:命名实体识别。收集足够的文化负载词,训练一个命名实体识别模型,统一提取测试集、验证集。
Q5:在处理较大的文本时可能需要不止一个标注人员,标注之前是要明确一个标准吗?如何确定质量评估指标来评估标注的质量?
A:先找2000tokens的文本试错。前期共同的标注指南,不断反馈更新。
Q6:想统计中译本中的四字成语使用频率,请问有什么方法或者操作软件吗?
Q7:语料库与翻译研究可以有哪些思路、借助哪些工具呢?如何去积累自己的语料库?
Q8:术语标准的语料库,然后收集了几千篇sci论文作为另一个语料库,请问能用Python探查这些术语在这个sci论文语料库中的应用情况吗?




