技术应用|FunAudioLLM:打破语言壁垒,开启多语音交流!
论文介绍
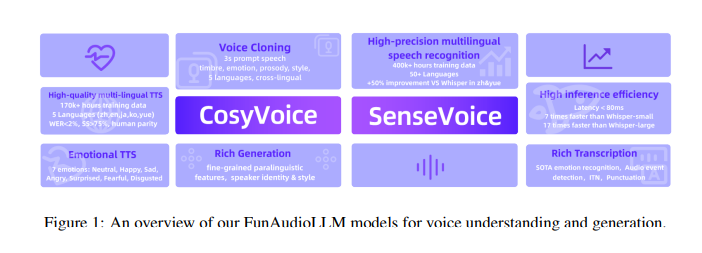
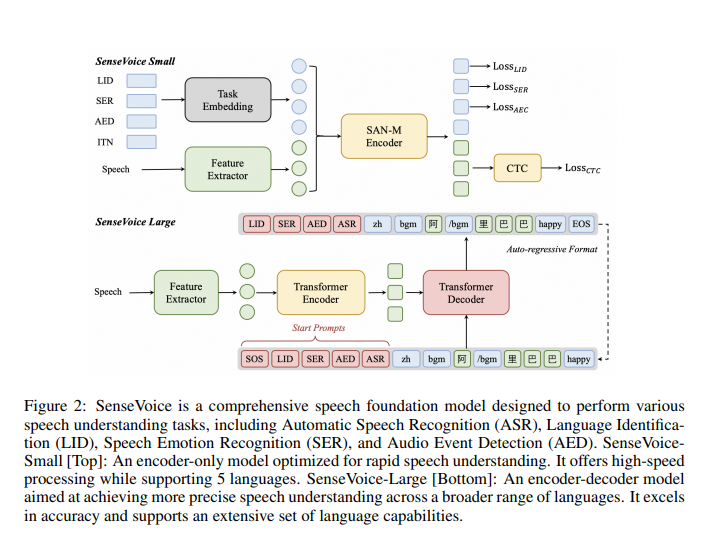
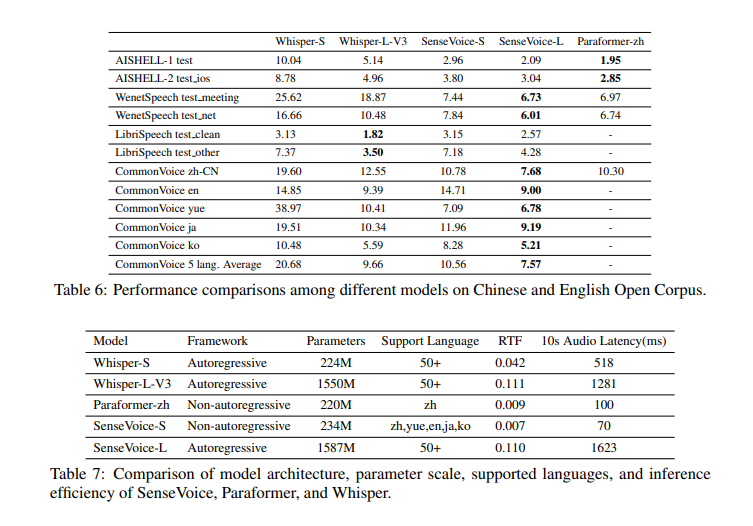
论文下载
-
论文地址:https://arxiv.org/abs/2407.04051
-
Github地址:https://github.com/FunAudioLLM

群内会定期推送语言服务行业最新动态、活动预告、竞赛通知?等内容~
欢迎你的加入?!
论文地址:https://arxiv.org/abs/2407.04051
Github地址:https://github.com/FunAudioLLM
群内会定期推送语言服务行业最新动态、活动预告、竞赛通知?等内容~
欢迎你的加入?!

电话:15811379550
邮箱:yuxiang.ding@lingotek.cn