神经机器翻译(NMT)在每个人的脑海中。它的质量已经到令人震惊的程度,而且就在我们说话的时候,它还在继续提高。科技巨头正在神经机器翻译应用上投入大量资金。大大小小的语言服务提供商都在生产中部署它。翻译人员越来越多地在工作流程中使用它。事实上,对许多人来说,译后机器翻译已经成为一种默认的工作方式。
由于其为深度学习设计的端到端计算架构,神经机器翻译比其前身统计机器翻译更容易理解。但核心机器翻译研究仍然是少数人的特权。对于大多数用户来说,机器翻译仍然是一个黑匣子,其行为往往不可预测,但由于最近旨在提高机器翻译素养的努力,这种情况已经开始改变。MultiTraiNMT项目是朝着这个方向迈出的重要一步。
什么是MultiTraiNMT?
由欧盟Erasmus+计划资助的MultiTraiNMT是一个专门旨在“开发、评估和传播开放存取材料和开源应用程序的项目,这些材料和应用程序将导致欧洲各地的语言学习者、语言教师、见习翻译人员、翻译教师和专业翻译人员对机器翻译的教学和学习得到加强”。不仅仅是欧洲。MultiTraiNMT是由巴塞罗那自治大学、阿拉坎特大学、格勒诺布尔——阿尔卑斯大学和都柏林城市大学的专家团队在过去三年中与Prompsit语言工程和KantanMT一起开发的,它邀请所有感兴趣的各方作为合作伙伴加入它,以:
- “在课堂上使用项目教材和相关活动。”
- “测试MutNMT教育平台和活动,以管理用于教学目的的NMT引擎。”
- “参与任何其他促进机器翻译技能发展的培训或研究活动。”
下文简要介绍该项目的三个相互关联的组成部分。
书籍
2022年7月发布的开放存取教材Machine Translation for Everyone,涵盖了很多领域——从技术基础到机器翻译的伦理和广泛的社会影响。虽然明确了是供课堂使用的,但这本书的九章由相关领域的专家撰写,非常清晰且适合每个人。每一章都可以单独阅读,并附有大量更专业的文献参考。
活动
教材的每一章都有两种类型的活动:
- 自学问题从多项选择到纵横字谜和填空练习(见图1),并为那些按照自己的进度学习的人提供即时自动反馈。
- 开放式、可定制的教师指导的迷你项目,邀请读者思考围绕机器翻译的许多有趣和具有挑战性的问题,并撰写短文。(参见图2。)
图1:第五章“如何处理机器翻译中的错误:译后编辑”的填空练习

图2:第六章“伦理与机器翻译”的短文作业目前有超过200个优秀的、准备充分的活动,作者使用开源的H5P平台将它们如此细致地放在一起,值得称赞,该平台允许用户将它们集成到Drupal或Moodle等学习管理系统和WordPress等发布环境中。翻译教师可以根据他们的需要进一步调整活动。这也是一个很好的自我测试:如果你能正确回答大部分问题,你可能对机器翻译很了解!要理解这一点,请浏览问题。您将接受广泛主题的测验——从神经网络的基础知识到著名的单词嵌入语义炼金术,到BLEU和TER等机器翻译评估指标,到使特定机器翻译引擎适应给定任务以及在第二语言学习中使用机器翻译的机遇和挑战。如果你发现你的背景有很大的差距,读读这本书吧!它有所有的答案,即使你已经熟悉了这些材料,也是一本非常值得一读的书。除此之外,它试图为一个已经变得非常复杂的领域提供一个统一的视角。
MutNMT
MutNMT的名称源自古埃及的母亲女神Mut,它是一个Web应用程序,可让您无需任何编码即可了解机器翻译的原理!任何拥有谷歌账户的人都可以访问该应用程序七个功能中的五个:数据、引擎、翻译、检查和评估。(参见图3)让我们来看看这些特性。数据:专家用户已经上传到系统的快速扩展的平行语料库集合。有些语料库有数百万对句子。这些是用来训练神经机器翻译发动机的。任何用户都可以“抓取”一个可用的语料库,并将其添加到他们的个人收藏中(“您的语料库”)。语料库也可以作为两个并行文本文件的压缩存档进行预览和下载。引擎:提供了由专家用户在可用语料库上训练的越来越多的神经机器翻译模型列表。同样,用户可以“抓取”任何引擎,并将其添加到他们的个人集合(“您的引擎”)中进行翻译和检查。您还可以查看给定引擎的训练日志,了解大量有用的信息。不再需要的语料库和引擎可以从单个集合中删除。
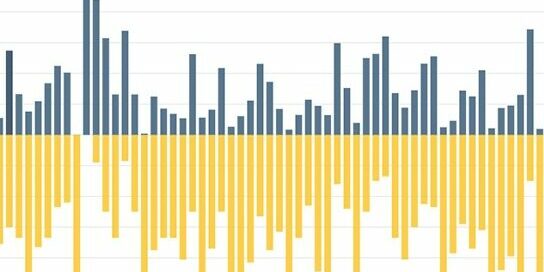
图3:MutNMT的翻译接口:在这里,您可以从您的个人收藏中选择一个引擎来翻译一个句子或一个小文件。这可能需要一些时间。重要提示:不要期待DeepL质量!相反,开始欣赏一个惊人的事实,一个神经模型完全从零开始训练,在一个相对较小的语料库上,用一个简单的工具包,只需要一个小时的图形处理单元(GPU)时间,主要用于教学目的,通常可以产生合理的翻译——而且是以如此透明的方式!检查:允许您更深入地了解按下“翻译”按钮时会发生什么。系统从“标记化”输入句子开始(将其拆分为单词、标点符号,有时还有子词段)。然后,引擎产生“N个最佳”候选翻译,从中选择最有可能的翻译。这些步骤是可视化的,供你注意和学习。您还可以比较给定语言对的几个选定引擎的输出。评估:通过将所选引擎的输出与参考翻译(希望由专业人工翻译产生)进行比较,计算几个流行的指标(例如,BLEU、chrF3和TER)。您需要上传一个源文件(最多500句,纯文本格式,每行一句话)以及MutNMT输出和参考文件,它们必须与源文件完全对齐。请注意,该测试集不应用于训练引擎!除了文档级别的分数之外,MutNMT还为前100个测试句子生成一个逐句的BLEU/TER“分数图”。(参见图4。)您可以查看它们中的每一个,以检查机器翻译输出可能有什么问题。另外,您可以使用评估功能对任何机器翻译输出(例如,来自Google Translate、ModernMT或您自己的定制引擎)进行评分,以获得对其质量的近乎科学的感觉——只需上传三个文本文件并按下“评估”按钮。
图4:MutNMT生成的机器翻译评估分数和图表
上传语料库和训练引擎(针对更高级的用户)
这里讨论的MutNMT的五个特性允许任何人打开神经机器翻译的“黑匣子”并进入其中。那些对它感到舒适并准备做更多工作的人可以申请“专家”身份,以便能够上传新的语料库和训练新的引擎。这非常令人兴奋,但也耗费时间和资源。有许多不同格式的多语言公共语料库,包括TMX和平行文本文件。如果你有大于10万单位的翻译记忆,你可以试着在上面训练一个引擎。给定语言对的语料库可以组合起来进行训练,总共有50万个句子对。此外,您还需要为“验证”和“测试”创建更小的独立语料库(3-5K个句子对)。建议为“评价”也创建一个语料库(500句对)。假设这些数据与训练集或它们之间没有重叠,您将为整个过程做好充分准备。在机器翻译研究和开发中,标准做法是通过将验证和测试数据从大型训练语料库中分离出来来产生它们。但是一些公共语料库是高度重复的,所以你需要确保产生的子集之间没有重叠,否则你可能会得到夸大的分数,但质量很差。在任何情况下,语料库都必须完全对齐、清理和预处理,才能与MutNMT一起使用。如果“专家”用户决定在教学中使用MutNMT或以官方身份与MultiTraiNMT合作,他们可能会被进一步提升为“管理员”。如需更多提示,请阅读注释部分和侧边栏中引用的材料,并观看MultiTraiNMT YouTube频道上非常有用的视频。
打开黑匣子
学习机器翻译最好的方法就是打开它的黑匣子。由于像MultiTraiNMT这样的努力,这变得越来越有可能。深入了解神经机器翻译的背后是非常有力量的!
(机器翻译,轻度译后编辑,仅供参考。)
编辑:曾钰璇
