论文链接:
Demo:
Code:
https://github.com/ga642381/SpeechGen

大型语言模型 (LLMs)在人工智能生成内容(AIGC)方面引起了相当大的关注,特别是随着 ChatGPT 的出现。
然而,如何用大型语言模型处理连续语音仍然是一个未解决的挑战,这一挑战阻碍了大型语言模型在语音生成方面的应用。
因为语音信号包含丰富的信息,包括说话者和情感,超越了纯文本数据,基于语音的语言模型 (Speech Language Model, Speech LM)不断涌现。
虽然与基于文本的语言模型相比,语音语言模型仍处于早期阶段,但由于语音数据中蕴含着比文本更丰富的信息,它们具备巨大的潜力,令人充满期待。
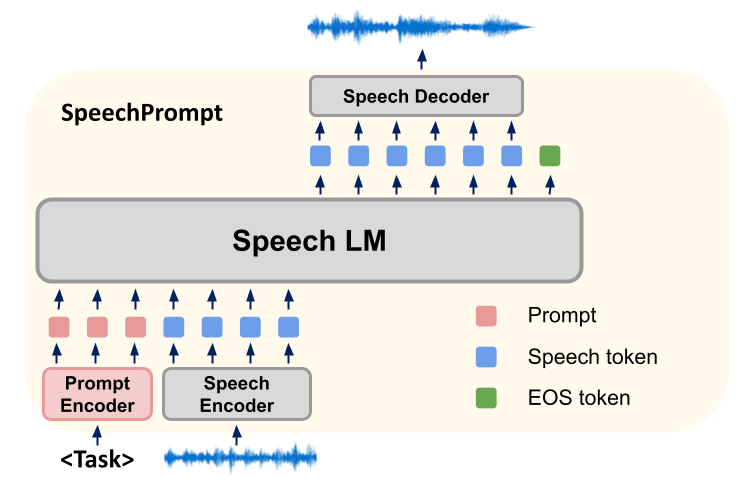
研究人员们正积极探索提示 (prompt) 范式的潜力,以发挥预训练语言模型的能力。这种提示通过微调少量参数,引导预训练语言模型做特定的下游任务。这种技术因其高效和有效而在NLP领域备受青睐。在语音处理领域,SpeechPrompt展示出了在参数效率方面的显著改进,并在各种语音分类任务中取得了竞争性的表现。
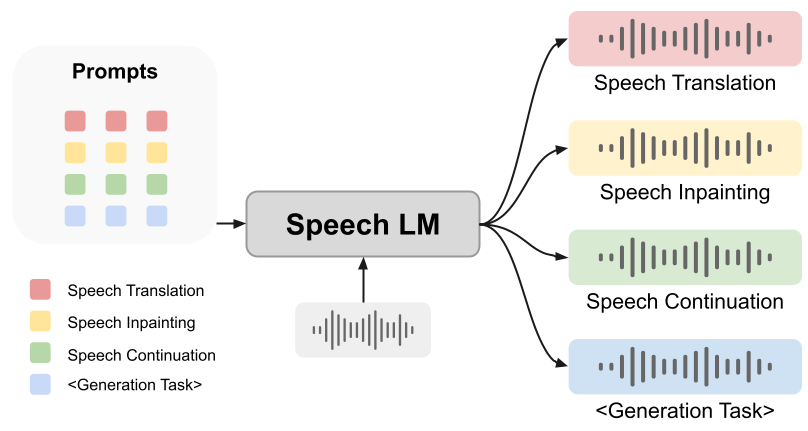
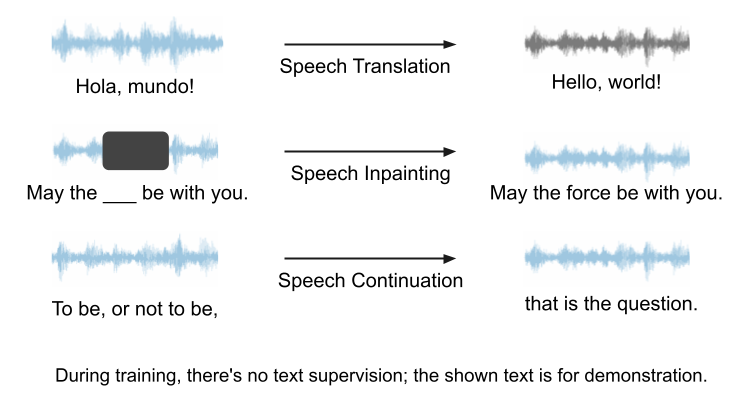
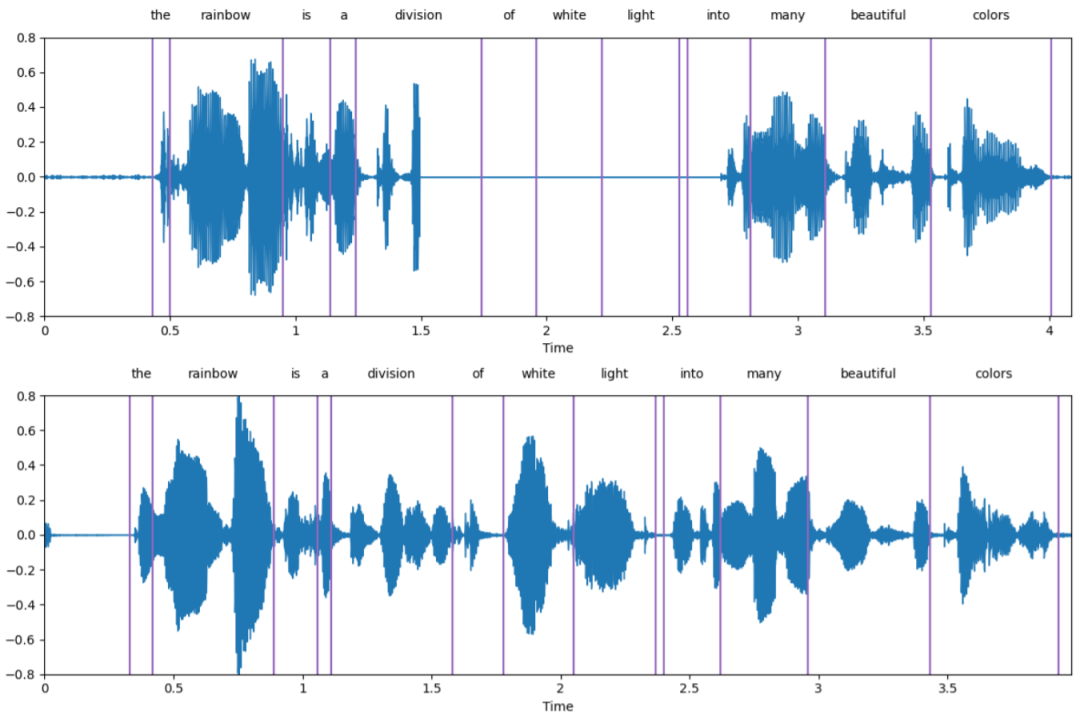
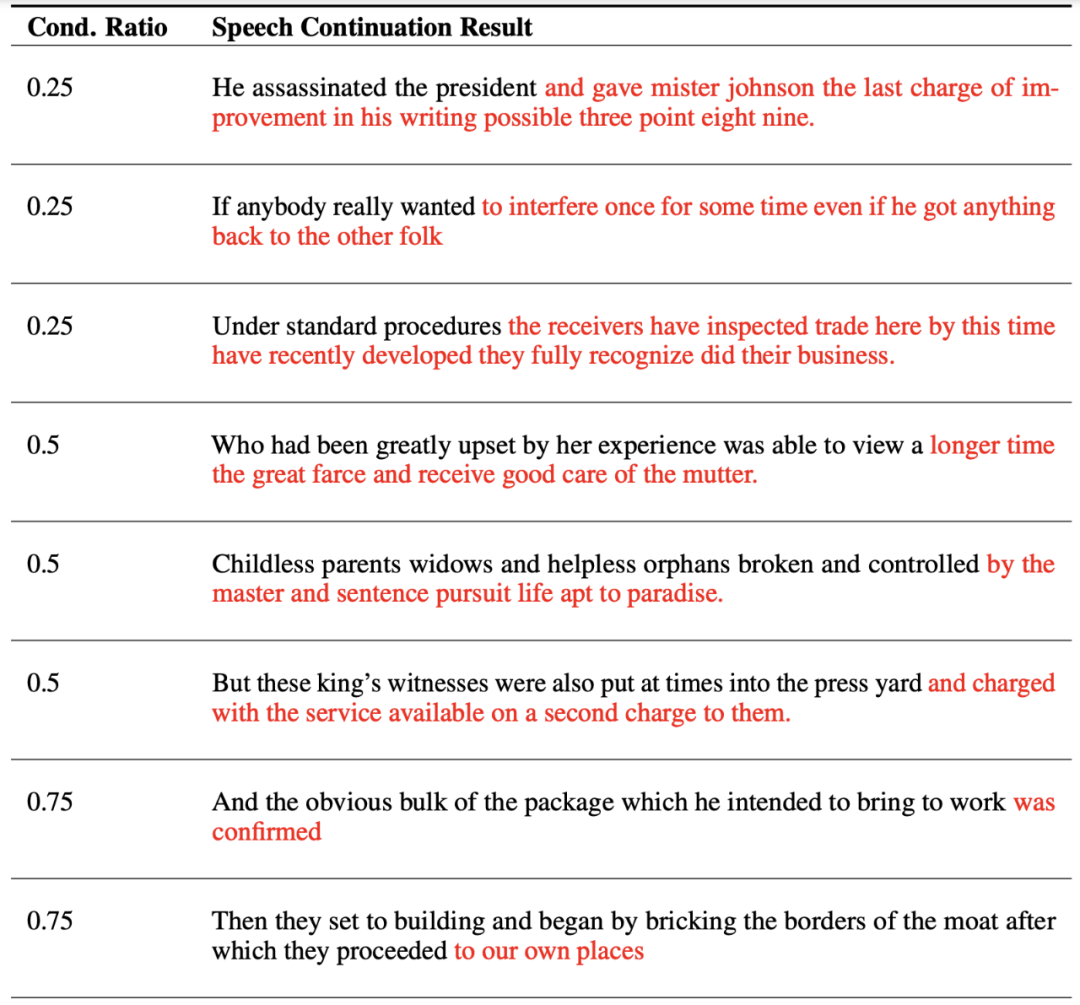
然而,提示能否帮助语音语言模型做生成任务仍是未解之谜。在本文中,我们提出一个创新的统一框架,SpeechGen,旨在激发语音语言模型进行生成任务的潜力。如下图所示,将一段语音、一个特定的提示(prompt)喂给 speech LM 作为输入,speech LM就能做特定的任务。比如将红色的 prompt 当作输入,speech LM 就能做 speech translation 的任务。